Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂
The team at Oxen.ai is dedicated to helping AI practictioners go from research to production. To help enable this, we host a research paper club on Fridays called ArXiv Dives, where we go over state of the art research and how you can apply it to your own work.
Take a look at our Arxiv Dives, Practical ML Dives as well as a treasure trove of content on how to go from raw datasets to production ready AI/ML systems. We cover everything from prompt engineering, fine-tuning, computer vision, natural language understanding, generative ai, data engineering, to best practices when versioning your data. So, dive in and explore – we're excited to share our journey and learnings with you 🚀

Llama 3.1 is a set of Open Weights Foundation models released by Meta, which marks the first time an open model has caught up to GPT-4, Anthropic, or other closed models in the eco...

![How to De-duplicate and Clean Synthetic Data [2/4]](https://ghost.oxen.ai/content/images/2024/08/blog-copy.jpg)
Synthetic data has shown promising results for training and fine tuning large models, such as Llama 3.1 and the models behind Apple Intelligence, and to produce datasets from minim...

![Create Your Own Synthetic Data With Only 5 Political Spam Texts [1/4]](https://ghost.oxen.ai/content/images/2024/08/political_spam.png)
With the 2024 elections coming up, spam and political texts are more prevalent than ever as political campaigns increasingly turn towards texting potential voters. Over 15 billion ...
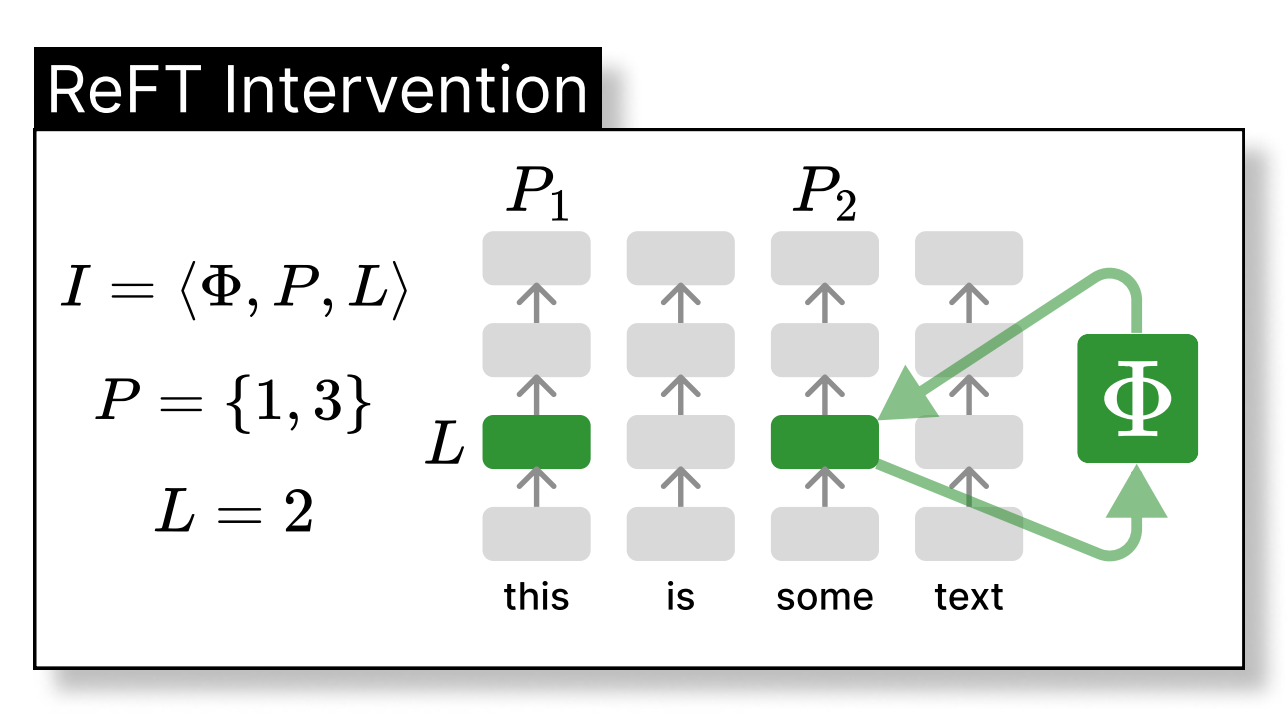
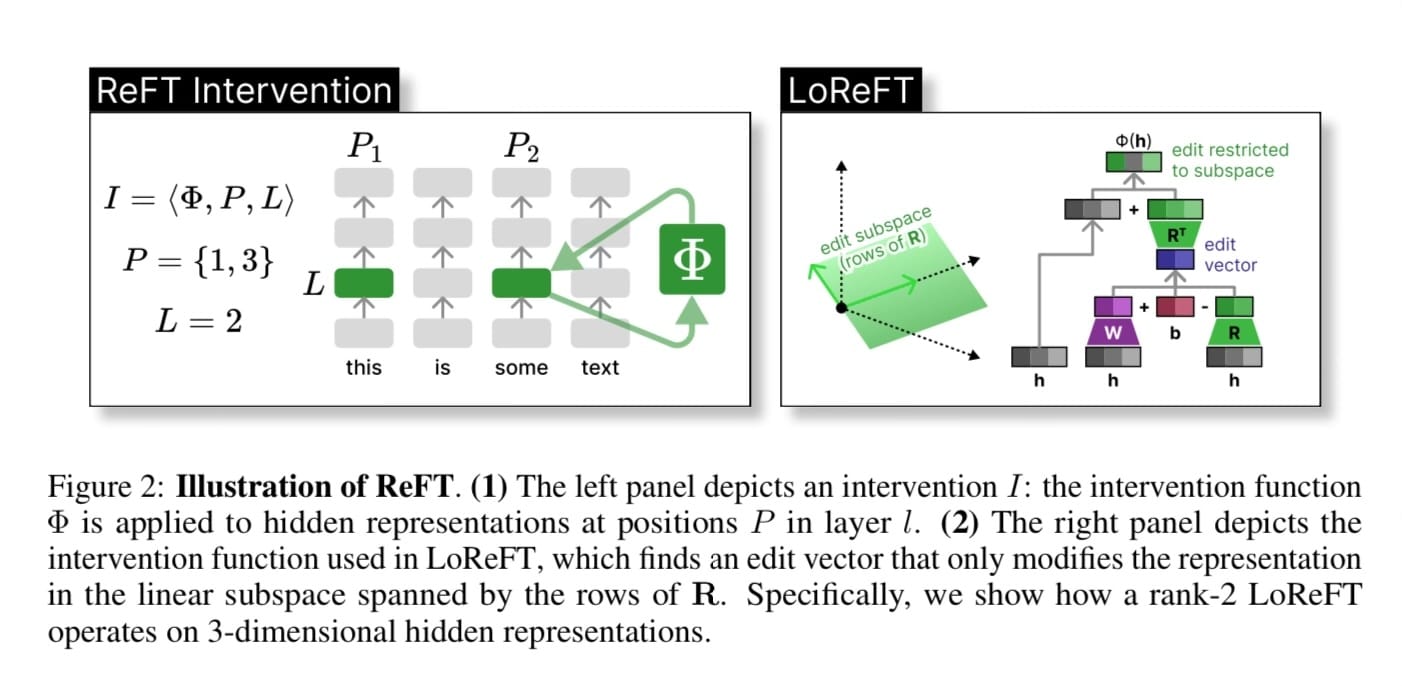
If you have been fine-tuning models recently, you have most likely used LoRA. While LoRA has been the dominant PEFT technique for a long time thanks to its efficiency and effective...
ArXiv Dives is a series of live meetups that take place on Fridays with the Oxen.ai community. We believe that it is not only important to read the papers, but dive into the code t...


Modeling sequences with infinite context length is one of the dreams of Large Language models. Some LLMs such as Transformers suffer from quadratic computational complexity, making...

The ability to interpret and steer large language models is an important topic as they become more and more a part of our daily lives. As the leader in AI safety, Anthropic takes o...

Diffusion Transformers have been gaining a lot of steam since OpenAI's demo of Sora back in March. The problem, when we think of training text-to-image models, we usually think mil...

Large Language Models have shown very good ability to generalize within a distribution, and frontier models have shown incredible flexibility under prompting. Now that there is so...
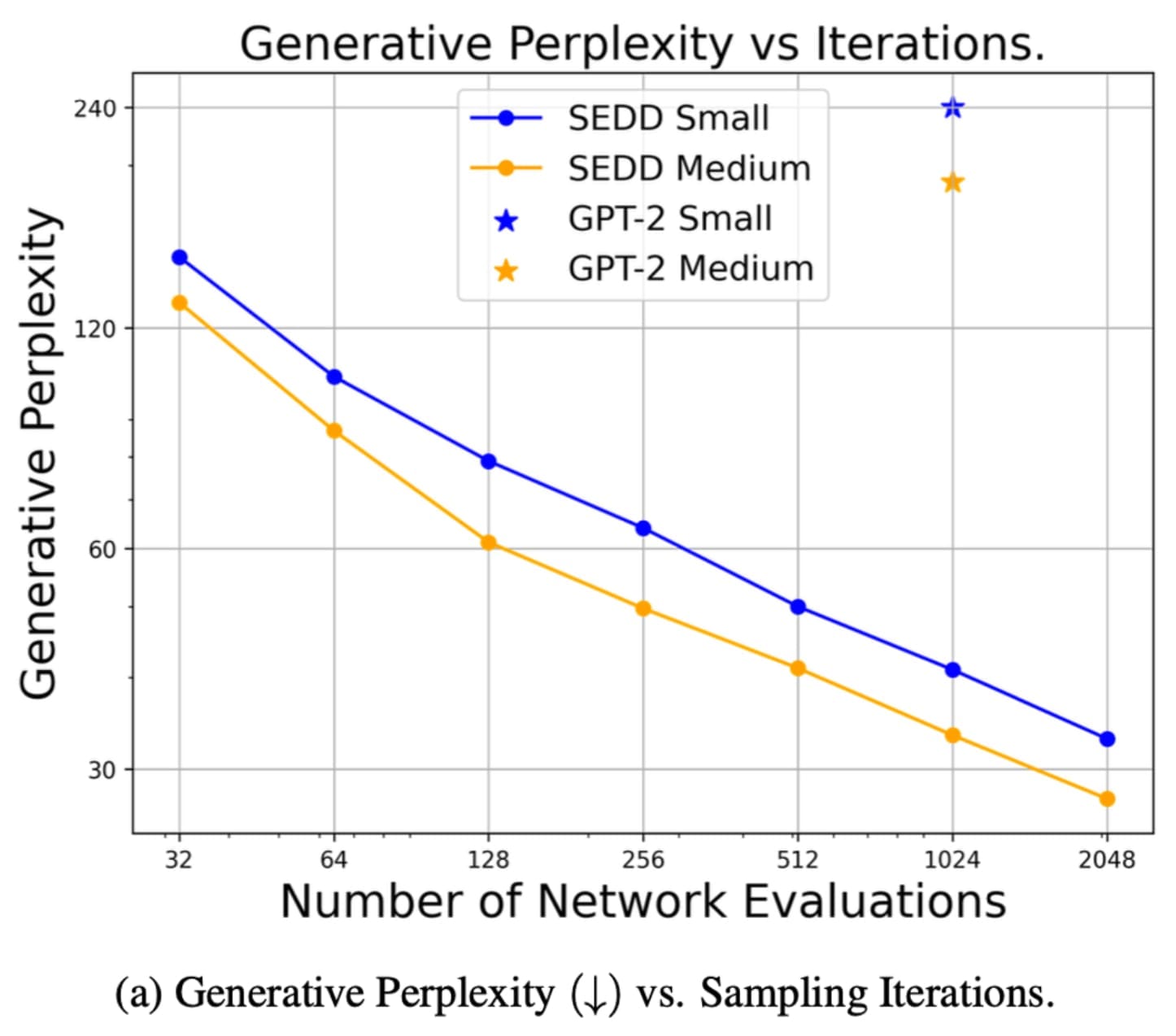
This is part two of a series on Diffusion for Text with Score Entropy Discrete Diffusion (SEDD) models. Today we will be diving into the code for diffusion models for text, and see...