ArXiv Dives: Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet


The ability to interpret and steer large language models is an important topic as they become more and more a part of our daily lives. As the leader in AI safety, Anthropic takes ones of their latest models “Claude 3 Sonnet” and explores the representations internal to the model, discovering how certain features are related to concepts in the real world in their Scaling Monosemanticity blog.
https://transformer-circuits.pub/2024/scaling-monosemanticity
Before we jump into the paper, a question I've been holding in the back of my mind was raised by one of our community members Cameron, "Why does this research result open up new interface possibilities?"
(If you'd like to join our discord and give your answer while reading the paper, make sure to join here: https://discord.com/invite/s3tBEn7Ptg)
This is a part of a live series we do on Fridays, the blog is the notes from our live session from May 31st, 2024. Feel free to follow along!
What is Mechanistic Interpretability?
“Mechanistic Interpretability” seeks to reverse engineer neural networks, similar to how one might reverse engineer a compiled binary computer program. After all, neural network parameters are in some sense a binary computer program which runs on one of the exotic virtual machines we call a neural network architecture.
This paper is inspiring because it still remain quite the black box when it comes to understanding why Neural Networks and Transformers make certain decisions over others.
For example:
When asking about travel, why would a neural network default to talking about the Golden Gate Bridge vs the Eiffel Tower?

How do we detect if the model is having “inner conflict” when responding?

What parts of the model are active when finding errors in code? Does the model know when it is executing malicious code? Can we get them to hallucinate errors that don’t exist, or fix bugs when they do?

These are the interesting types of questions that this paper starts to answer, and the way they tackle it is with what they call “Monosemanticity”.
What is Monosemanticity?
Transformers are “universal function approximations” that have the ability to encode and express a variety of concepts.
When you look under the hood, all of these functions just look like massive arrays of floating point numbers.
I recently saw a tweet from Tom Yeh that had a really nice diagram of what these numbers look like under the hood.
https://x.com/proftomyeh/status/1794702829103309291?s=61&t=kOXJIPyCP7NaKW2417uihQ
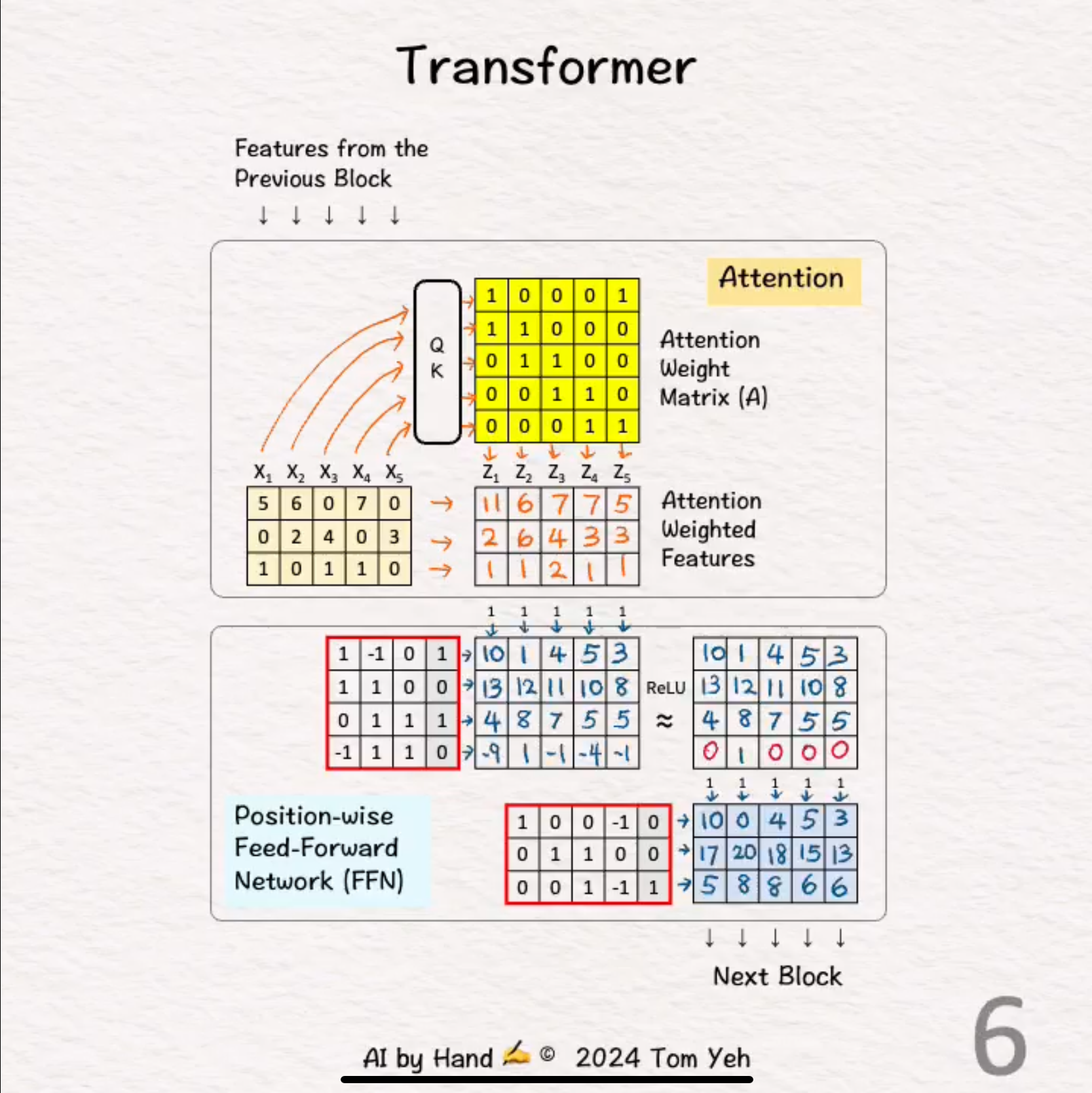
Each layer within a network has a linear set of numbers that get multiplied together and run through a non-linear transform to pass information along.
The problem is we as humans have a hard time understanding even the simplest of neural networks.
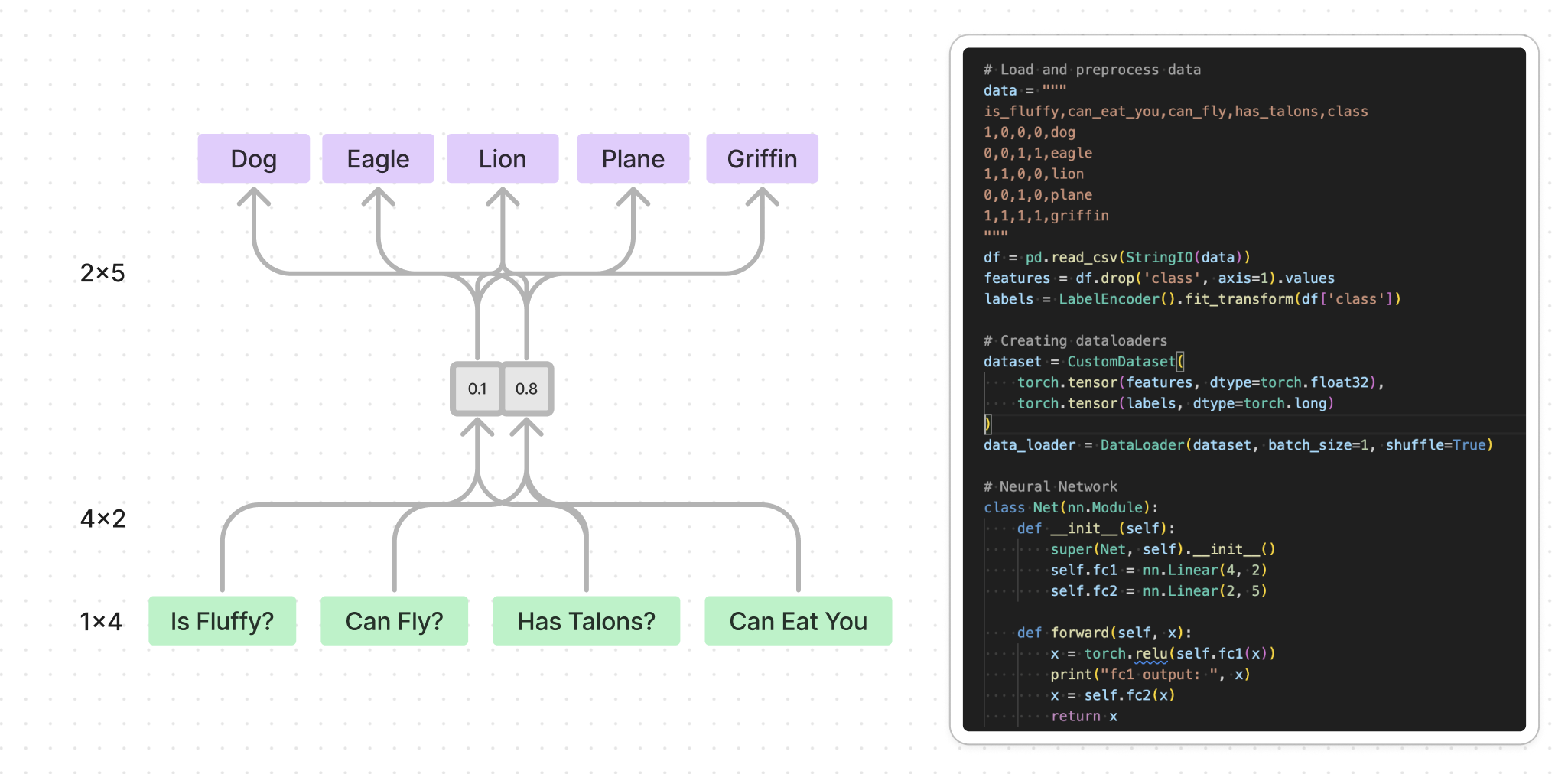
https://gist.github.com/gschoeni/2c48b403c8825253502a4a201946bc8a
Now scale this up to millions of parameters and much larger output sizes.
Anthropic has previous work trying to do understand how a single neuron can represent multiple concepts in their post “Toy Models of Superposition”. In their words: Linear representations can represent more features than dimensions, using a strategy we call superposition.
https://transformer-circuits.pub/2022/toy_model/index.html#motivation
More over, many neurons are polysemantic: they respond to mixtures of seemingly unrelated inputs. In the vision model Inception v1, a single neuron responds to faces of cats and fronts of cars. A single neuron can to a mixture of academic citations, English dialogue, HTTP requests, and Korean text.
So if each number in our matrix is helpful in describing multiple concepts, how on earth can we decompose these numbers to know which number affects which output? How can we interpret and modify these values so that we can target individual concepts?
This is where their work on “Monosemanticity” and “Mechanistic Interpretability” come in.
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. We had an entire dive on this topic before that may be good context to watch if the diagram below does not make sense.

Monosemanticity tries to create a dictionary that we can look up into for each set of features that corresponds to what concept they represent. This is what they call “dictionary learning” and in this case they use a Sparse Autoencoder to create the “dictionary”.
Autoencoders simply take an input, map it to a new set of values, then reconstruct the original set from the new. Usually Autoencoders are used to compress information from a high dimensional space to a lower dimensional one. For example go from a layer with 1024 values to one with 32 then back up to 1024.
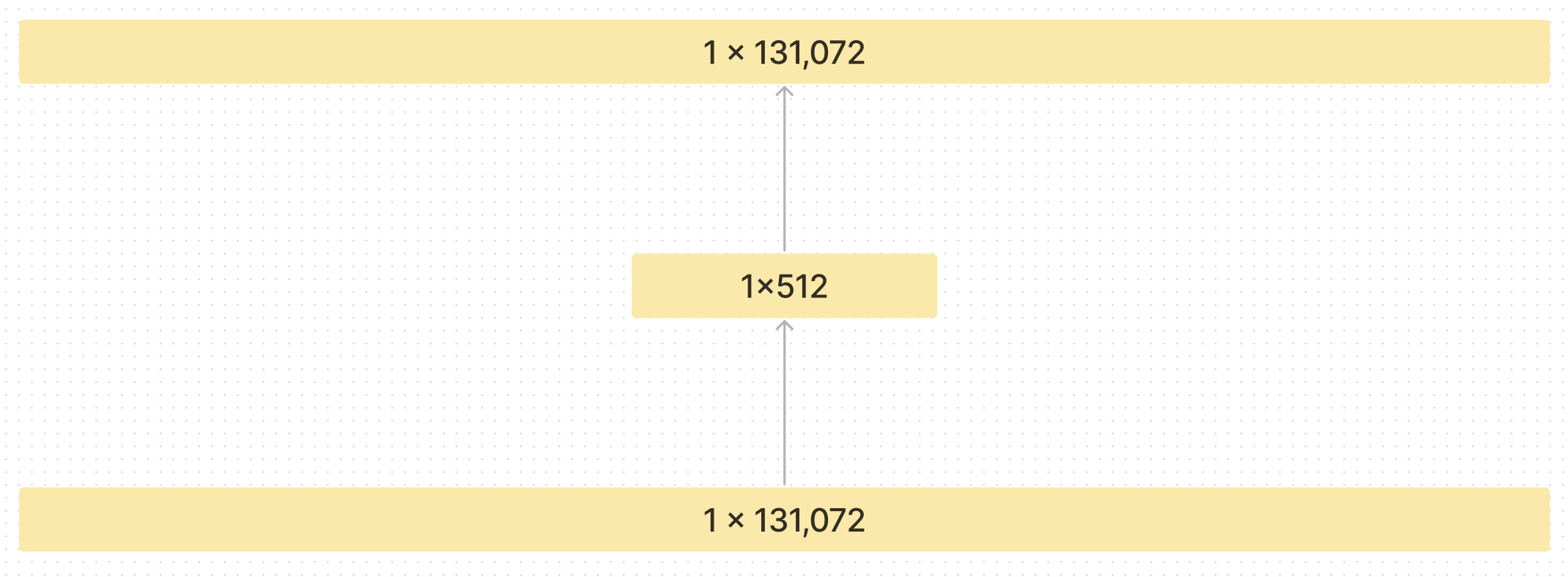
If you are ever in an interview and they ask you “What are applications of Autoencoders” you should answer “compression”. We are compressing this large set of numbers down to a much smaller one, and trying to reconstruct it.
To extract monosemantic features they flip the Autoencoder on its head and encode the information into a larger dimensional space.
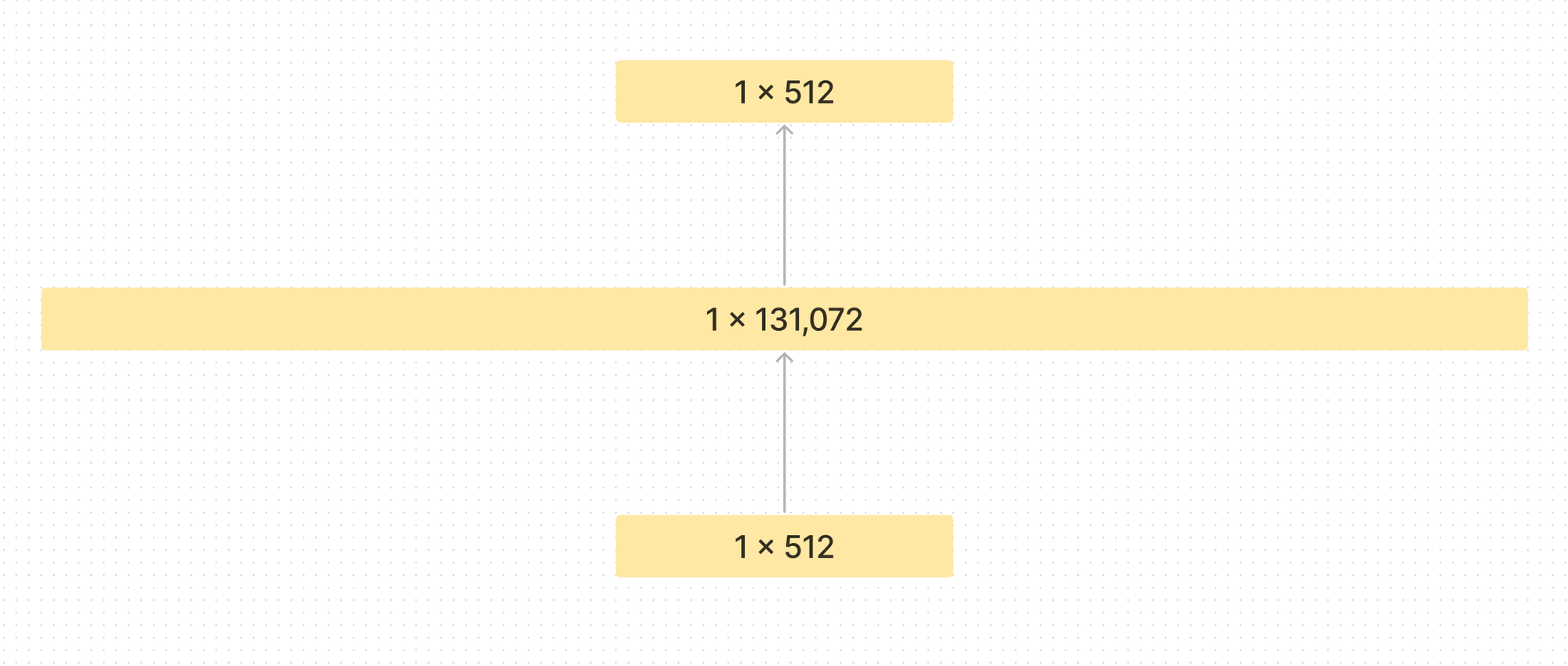
They call this a Sparse Autoencoder. Since there are multiple concepts represented in each neuron, they decompose into more features than there are neurons.
The hope is that concepts will be spread out like a one-hot dictionary within this larger layer.
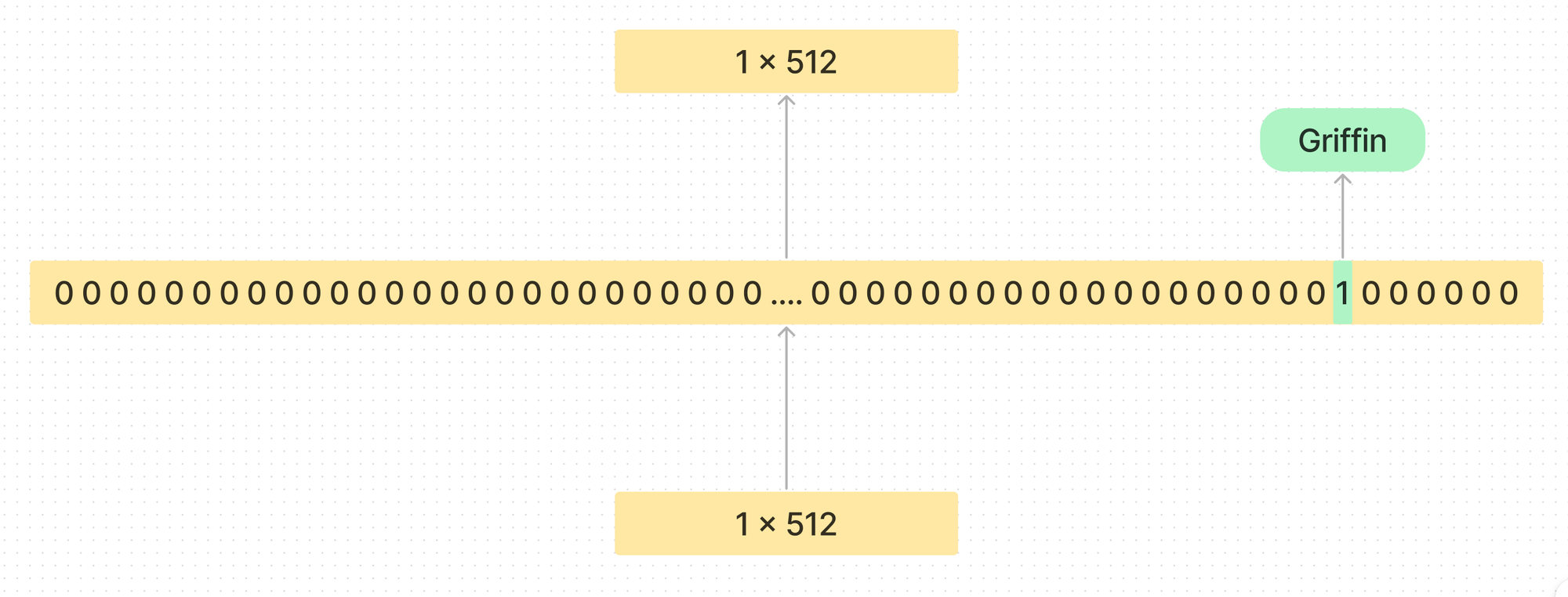
They showed in previous work that this worked well for small models, but it remained to be seen if they could scale this technique to larger ones.
https://transformer-circuits.pub/2023/monosemantic-features/index.html
This paper scales up previous work to make sure that their findings hold for larger language models. Specifically they apply it to Claude 3 Sonnet Anthropic's medium-sized production model.
Sparse Autoencoder
Our SAE consists of two layers.

The first layer (“encoder”) maps the activity to a higher-dimensional layer via a learned linear transformation followed by a ReLU nonlinearity.
They refer to the units of this high-dimensional layer as “features.” The second layer (“decoder”) attempts to reconstruct the model activations via a linear transformation of the feature activations.
The model is trained to minimize a combination of (1) reconstruction error and (2) an L1 regularization penalty on the feature activations, which incentivizes sparsity.

The L1 penalty on the feature activations creates sparsity in the activations because L1 is “spiky” in nature.

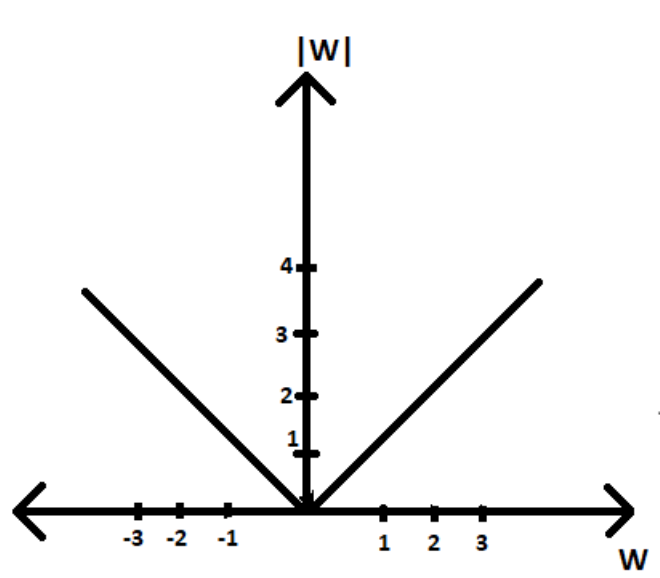
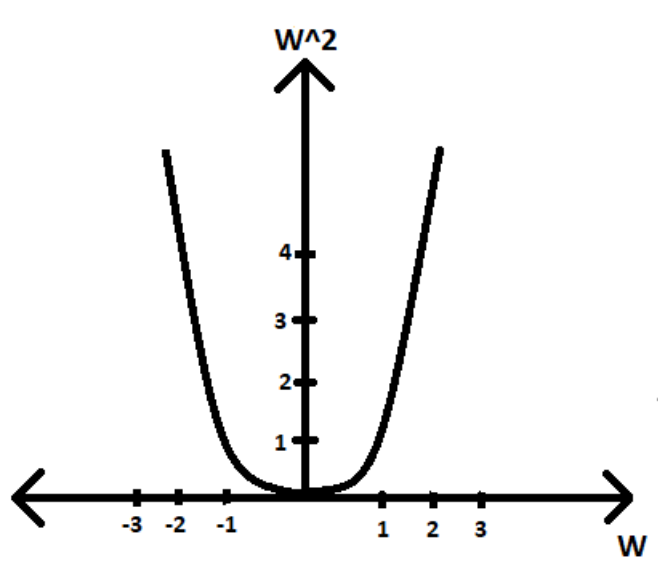
L2 is more smooth

The fact that they enforce a “spiky” L1 constraint means that many of the values will go to zero creating more sparsity. Think of the derivative of a the absolute value function. Since it is linear the derivative is a constant, and will be likely to go to zero if you enforce a low absolute value of all parameters.
The goal is that a very small fraction of features will have nonzero activations, so that we can feed in tokens and see which model activations are “explained” by a small set of active features.
The L2 part of the loss function is just the Mean Square Error, which means it is an imperfect signal of reconstruction of the signal, but it seems to work well in practice.

Experiments
They apply the Sparse Autoencoder to the residual stream halfway through the model. At the “middle layer”.

The residual stream is much smaller than the MLP layer, making training the SAE cheaper. It is also where the model is passing information through and has a reasonable level of abstraction being in the middle.
They train 3 SAEs with varying parameter count
- 1,048,576 (~1M)
- 4,194,304 (~4M)
- 33,554,432 (~34M)
On average the number of non-zero activations on a given token was fewer than 300.
🤿 Let’s Dive Into Some Examples
The goal of this section is to find features that are “genuinely interpretable”. Four example features are as follows.
- The Golden Gate Bridge
- Brain sciences
- Monuments and popular tourist attractions
- Transit infrastructure
They take a feature and rank pieces of text based on how strongly the piece of text activates the feature. The highlight colors indicate activation strength at each token (white: no activation, orange: strongest activation).


For each feature they attempt to establish that:
- Specificity: If the feature is active, the relevant concept is somewhere in the context
- Influence on behavior: Intervening the features activation produces relevant downstream behavior
Fun Fact:
In the 1M training run, we also find a feature that strongly activates for various kinds of transit infrastructure 1M/3 including trains, ferries, tunnels, bridges, and even wormholes!
I love how Anthropic makes interactive web apps instead of PDFs…You can explore more here:
https://transformer-circuits.pub/2024/scaling-monosemanticity/features/index.html?featureId=1M_3
Influence on Behavior
In order to investigate how these features influence the models they “clamp” specific features to artificially high or low values during the forward pass.
This means that they run the model with the SAE and when they do the reconstruction of the original features, they clamp the feature within the SAE in question.
We find that feature steering is remarkably effective at modifying model outputs in specific, interpretable ways. It can be used to modify the model’s demeanor, preferences, stated goals, and biases; to induce it to make specific errors; and to circumvent model safeguards
For example, if they clamp the Golden Gate Bridge feature:

Which is hilarious 😂 they had this version of the model live on their site for a week or so and you could see how it responded, but they must have taken it down.
More Examples
For more complex examples and behavior they explore code generation and completion.
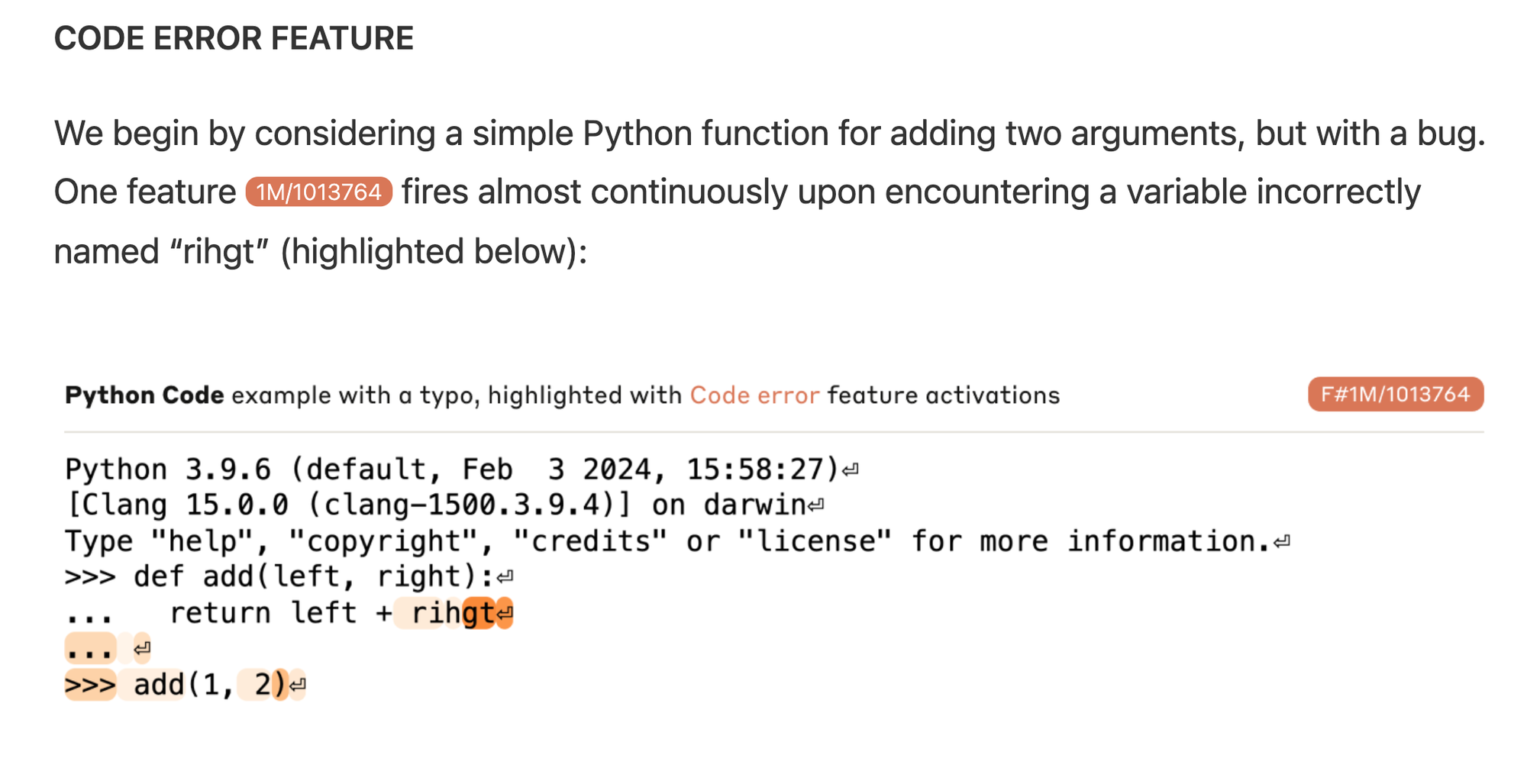


We found instances of it activating for:
- Array overflow
- Asserting provably false claims (e.g. 1==2)
- Calling a function with string instead of int
- Divide by zero
- Adding a string to int
- Writing to a null ptr
- Exiting with nonzero error code
From these examples it is clear that 1M/1013764 represents a wide variety of errors in code. But what about steerability?


Feature Neighborhoods
There are a variety of diverse features they find within the model. One challenge is that we have millions of features. Scaling feature exploration is an important open problem.
To explore the feature space they look at the cosine similarity between the activations.
A fun one is the “inner conflict” feature.
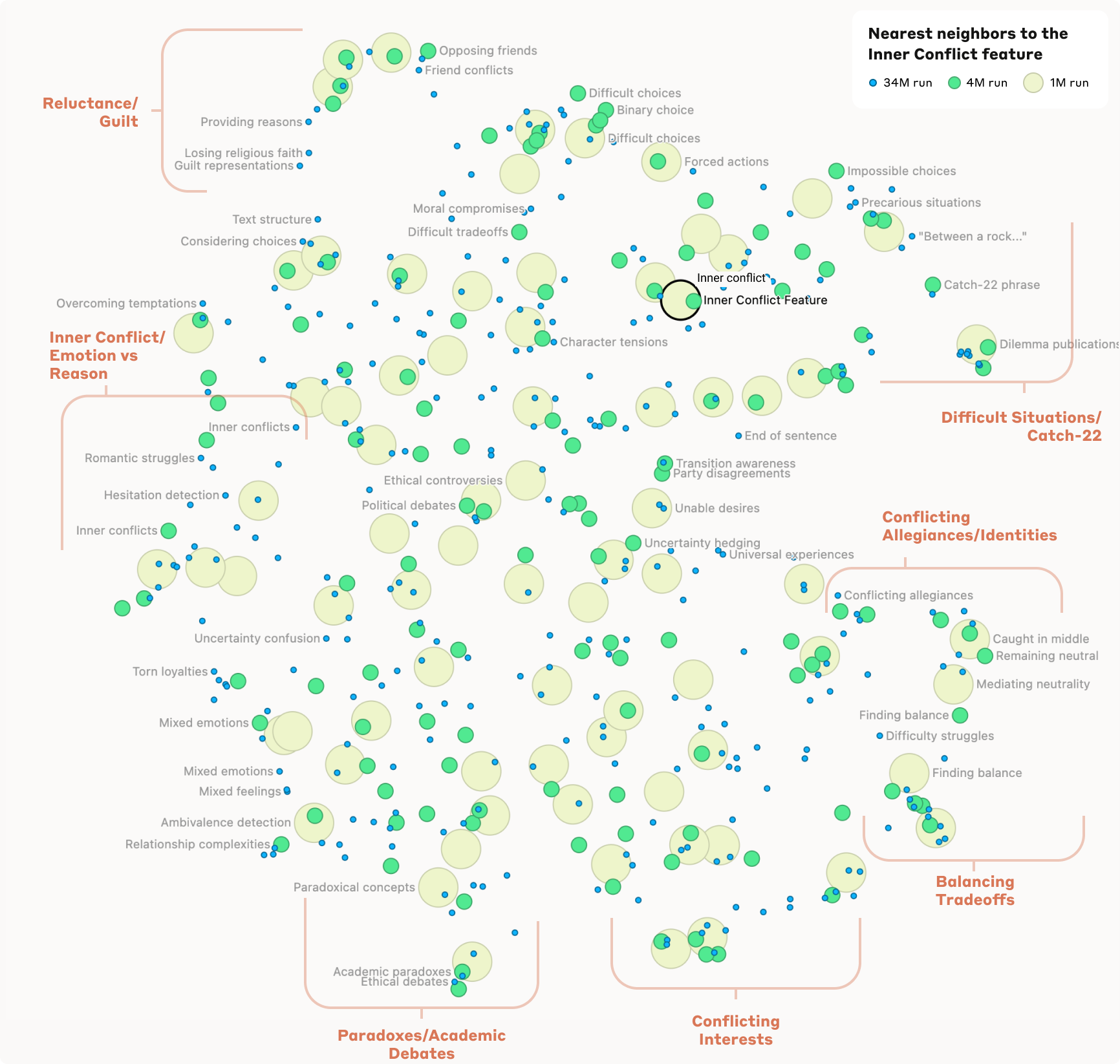
They have an interactive interface for this as well.
https://transformer-circuits.pub/2024/scaling-monosemanticity/umap.html?targetId=34m_31164353
There are so many features they identify it will be hard to cover them all here, let’s just scroll through and look at some interesting ones…
https://transformer-circuits.pub/2024/scaling-monosemanticity/#safety-relevant-code
Discussion
It is interesting to study how these features activate and if we can detect when “unsafe” ones occur. On the positive side I think it is also an interesting way to steer models to behave how you want without prompting directly. Lower level control of the activations that are less likely to be overridden in unknowing ways.
Can we use these techniques to detect bias before releasing a model?
Can we tell if a model is lying or hallucinating?
This study is limited in the fact that they just perform it on the “middle” residual stream within the transformer. There are far more activations to consider than this. I’m surprised they found so much in a single layer to be honest. It is computationally infeasible to do ablation studies on all activations.
Cross layer superposition also adds an interesting twist. Gradient decent allows information to pass between layers meaning there are features that are “smeared across layers”
Curious what people think, and returning to Cameron’s question: Why does this research result open up new interface possibilities?
If you'd like to join the convo and give your answer, visit our discord to talk with fellow engineers, researchers, and people who love AI: https://discord.com/invite/s3tBEn7Ptg