Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂
The team at Oxen.ai is dedicated to helping AI practictioners go from research to production. To help enable this, we host a research paper club on Fridays called ArXiv Dives, where we go over state of the art research and how you can apply it to your own work.
Take a look at our Arxiv Dives, Practical ML Dives as well as a treasure trove of content on how to go from raw datasets to production ready AI/ML systems. We cover everything from prompt engineering, fine-tuning, computer vision, natural language understanding, generative ai, data engineering, to best practices when versioning your data. So, dive in and explore – we're excited to share our journey and learnings with you 🚀
![The Best AI Data Version Control Tools [2025]](https://ghost.oxen.ai/content/images/2024/12/ox-carrying-data.jpg)
Data is often seen as static. It's common to just dump your data into S3 buckets in tarballs or upload to Hugging Face and leave it at that. Yet nowadays, data needs to evolve and ...


Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in AI/ML. In this blog we’ll be diving into Open Coder, a paper and co...
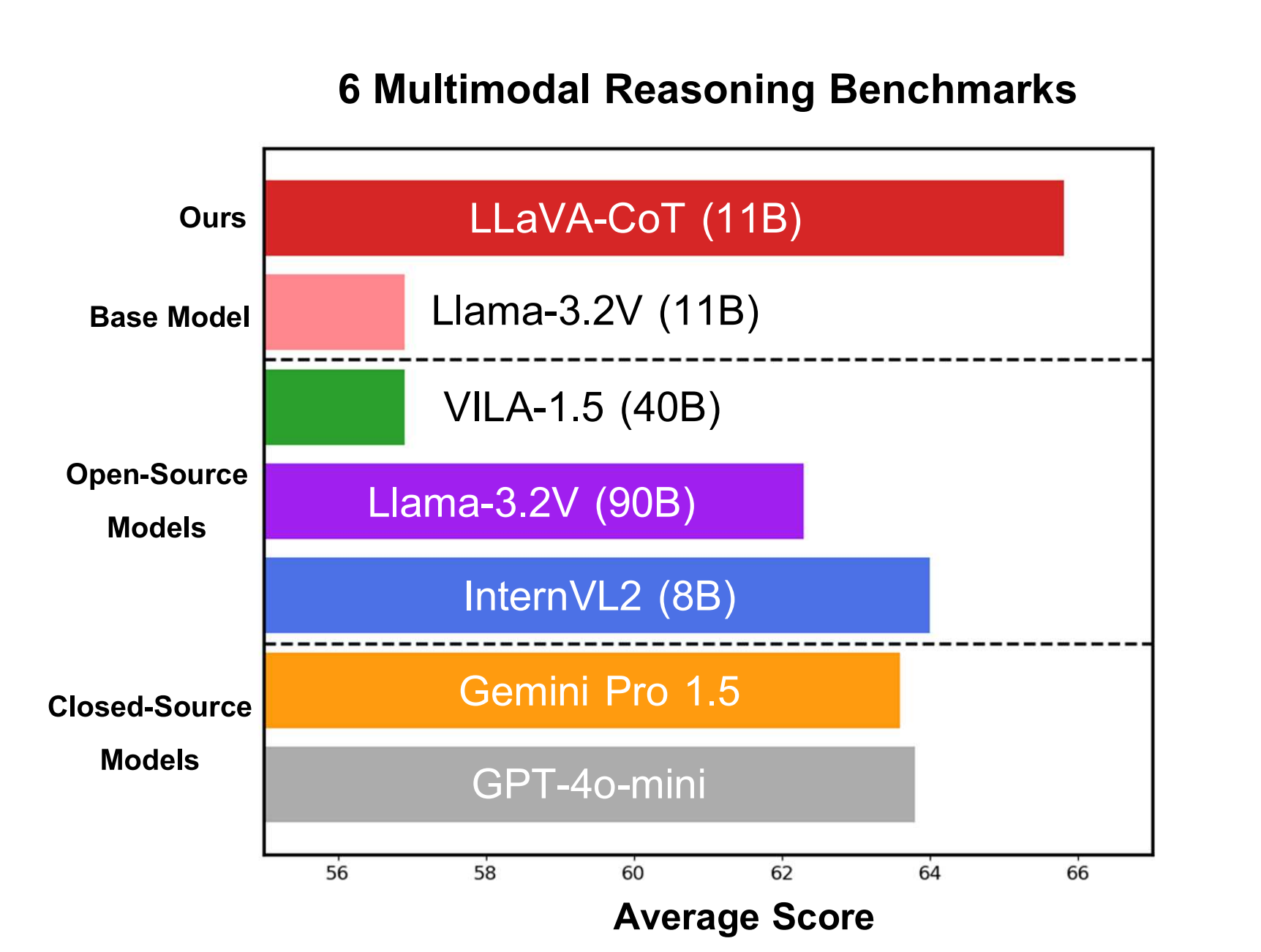
When it comes to large language models, it is still the early innings. Many of them still hallucinate, fail to follow instructions, or generally don’t work. The only way to combat ...
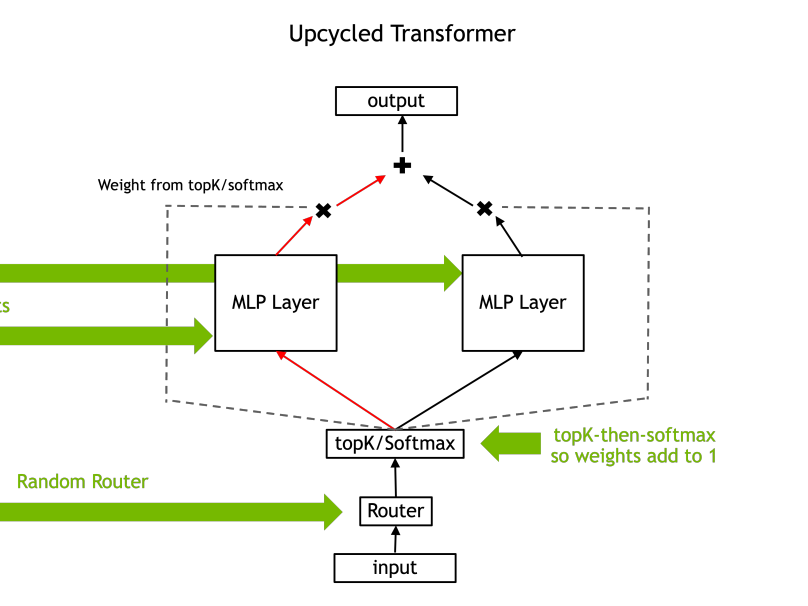
In this Arxiv Dive, Nvidia researcher, Ethan He, presents his co-authored work Upcycling LLMs in Mixture of Experts (MoE). He goes into what a MoE is, the challenges behind upcycli...
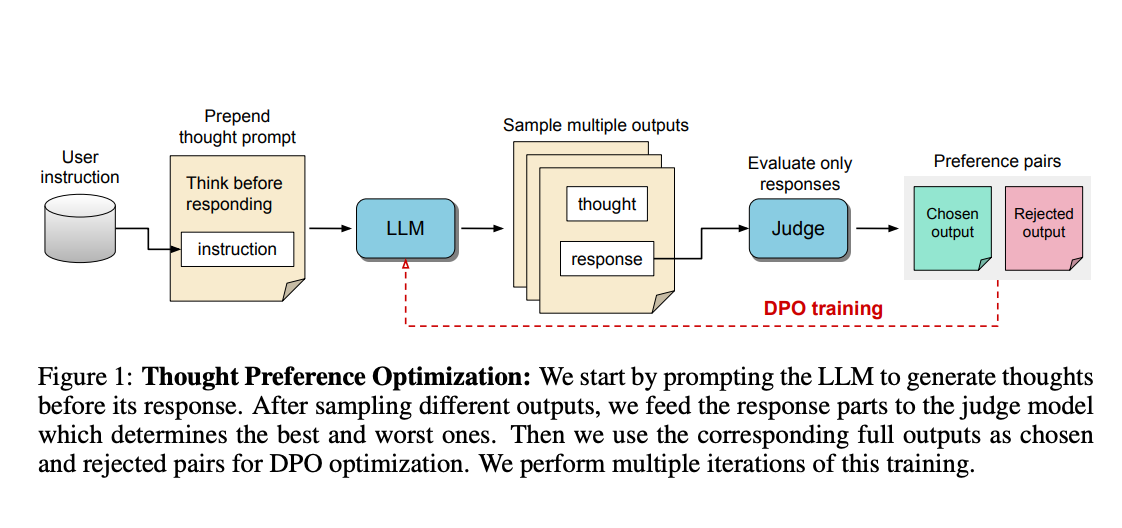
The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is a skill that some people have better than others 😉, but a sk...
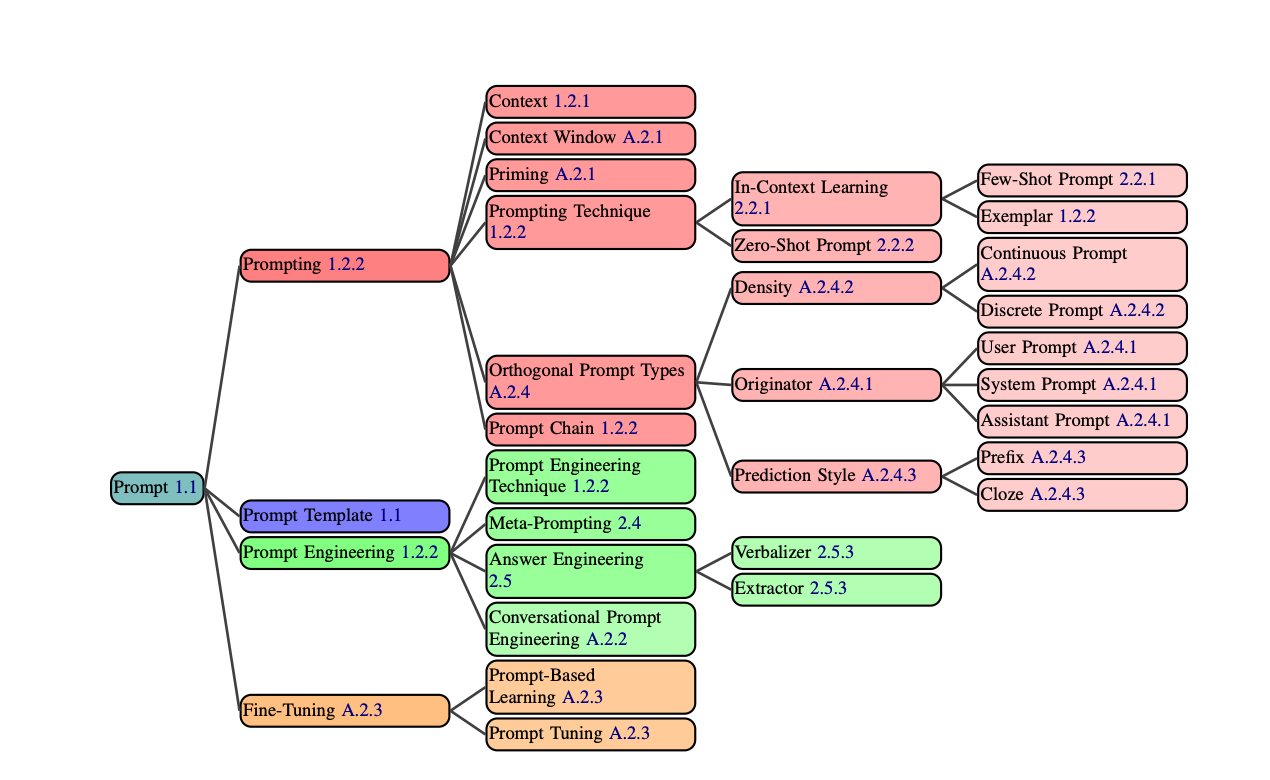
In the last blog, we went over prompting techniques 1-3 of The Prompt Report. This arXiv Dive, we were lucky to have the authors of the paper join us to go through some of the more...
For this blog we are switching it up a bit. In past Arxiv Dives, we have gone deep into the underlying model architectures and techniques that make large language models and other ...

Flux made quite a splash with its release on August 1st, 2024 as the new state of the art generative image model outperforming SDXL, SDXL-Turbo, Pixart, and DALL-E. While the model...

![How Well Can Llama 3.1 8B Detect Political Spam? [4/4]](https://ghost.oxen.ai/content/images/2024/09/DALL-E-2024-09-13-20.39.28---A-stylized--futuristic-llama-holding-an-American-flag-in-its-mouth--with-sharp--bold-lines-and-glowing--laser-like-eyes.-The-llama-has-a-sleek-fur-tex-1.webp)
It only took about 11 minutes to fine-tuned Llama 3.1 8B on our political spam synthetic dataset using ReFT. While this is extremely fast, beating out our previous record of 14 min...

![Fine-Tuning Llama 3.1 8B in Under 12 Minutes [3/4]](https://ghost.oxen.ai/content/images/2024/09/DALL-E-2024-09-03-11.22.45---A-stylized-llama-with-vibrant-red-and-blue-fur--shooting-laser-beams-from-its-eyes.-The-llama-s-eyes-glow-intensely--with-one-eye-emitting-a-red-laser-copy.jpg)
Meta has recently released Llama 3.1, including their 405 billion parameter model which is the most capable open model to date and the first open model on the same level as GPT 4. ...