arXiv Dive: How Meta Trained Llama 3.1


Llama 3.1 is a set of Open Weights Foundation models released by Meta, which marks the first time an open model has caught up to GPT-4, Anthropic, or other closed models in the ecosystem. Released on July 23rd, 2024, the 92-page behemoth of a paper Llama 3.1 Herd of Models shows an in-depth view of how they trained the model.
In this blog, we will focus on the most interesting parts of the paper: the data, the pre-training, and the newly coined post-training. If you'd like to watch along, we presented the blog in our arXiv Dive above.
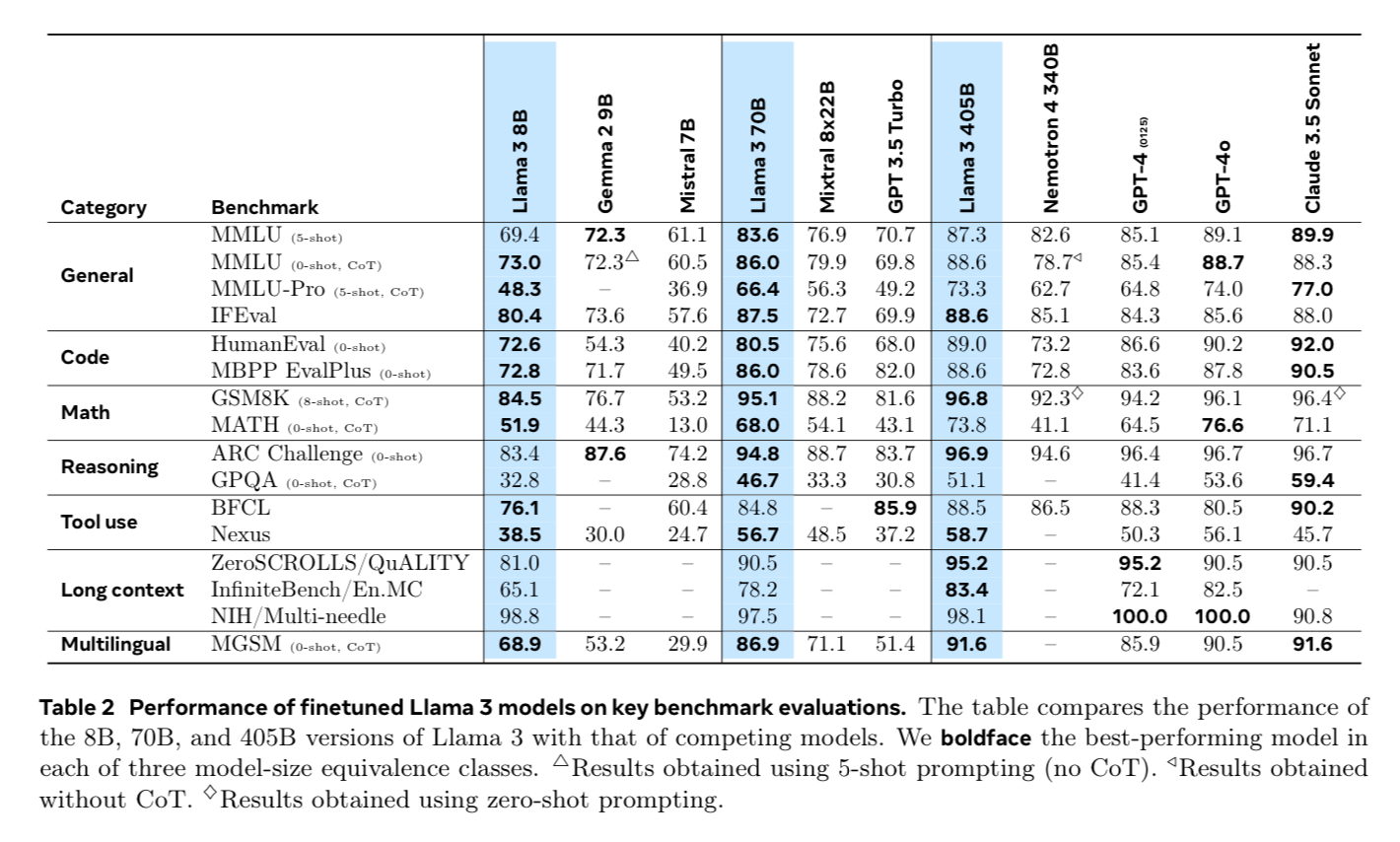
The Architecture
What’s super interesting about this paper is that they keep the model relatively constant. It’s the same old dense transformer we’ve seen over and over again, with one or two tricks to get the context length to 128k.
This paper is 99% how they scaled and iterated on the data, to improve the same old model architecture they had for Llama 1 and Llama 2.
We love this approach and paper because Oxen.ai was designed to do just this. We provide tools to help you iterate on the data half of the problem when it comes to AI.
If you are not familiar with Oxen.ai think of us like a git+github like experience, but optimized for the size, shape, and scale of data that you would never dream of putting in git. Just like how Meta iterated on the data to improve their Llama 3.1 models, you can use Oxen.ai to version, update, and iterate on your data between you and your team while building out state-of-the-art models in your own domain.
Today, we are going to dive into the nitty-gritty details of the pre-training and post-training steps that turned a vanilla Llama model into the state-of-the-art Llama 3.1 that anyone in the community can download and run (assuming you have the right hardware).
They release 6 new models in different model sizes:

Llama 405b at BF16 precision cannot fit on a single machine with 8 Nvidia H100s, so you need to split it on 16 GPUs on two machines.
H100 = 80GB RAM
405*2 = 810GB
8*80 = 640GB
Hence we need two. Fun fact - you can now rent clusters like this from services like lambda labs, but they aren’t cheap.
Three Levers to Improve Llama 2
They say there are 3 levers they pulled while developing high-quality foundation models:
Data, Scale, and Minimizing Complexity
I would also argue that the data and complexity levers can be pulled by anyone tinkering with AI. It’s more likely that you’re doing post-training and tuning a specific model from one of these base models.
Data
They worked hard on improving the quantity and quality of the data used for pre-training and post-training. When it comes to pre-training they were careful to filter, balance, and mix the proper text. There was a total of 15 trillion multi-lingual tokens. If on average a token is 8 bytes this means they have 120TB of data going into pre-training. During post-training, they had more rigorous quality insurance and a very interesting loop of synthetic data, reward models, and rejection sampling.
Scale
As we said above, we now have 120TB of data we need the model to crank through. They used a reported 3.8x10^25 FLOPS, which is 50x more than the previous Llama 2. Meta has a cluster of 16k H100 GPUs.
Some people have estimated with the current cost of GPUs that this means the training run cost upwards of 500 million dollars. I did the back-of-the-envelope math for Llama 2 costing 20 million dollars so it might even be close to 1 billion all said and done. If there’s ever a project you want to make sure your data is cleaned and ready to go before kicking off a half-billion-dollar training run.
Managing Complexity
They try to minimize complexity to scale the model development process. This means a standard transformer, supervised fine-tuning, rejection sampling, direct preference optimization (DPO), and no other fancy bells and whistles that can be notoriously hard to optimize. In other words, they used the KISS method (Keep It Stupid Simple).
Pre-Training vs Post-Training
Pre-training is the step of generating a massive corpus of text into tokens, and simply training the model to predict the next word. The pre-training dataset was 15T tokens of multilingual data including a mix of data from German, French, Italian, Portuguese, Hindi, Spanish, and Thai. The pre-training gets you to a model that can complete sentences and act like a parrot that has reasonable grammar. Post-training is where you teach the model to follow instructions, behave like an assistant, use tools, and align with your values. This is the first paper I’ve seen use the terminology "post-training", but it makes sense. There are many steps in post-training that they apply so that’s why they come up with a more generic term.
Pre-Training Data
There are a few steps when creating the pre-training dataset.
- Filtering
- Cleaning
- De-duplication
- Data Mixology
During filtering, they implement filters designed to remove text that contains PII or text that has adult or otherwise unsafe content. They use fast classifiers (using the fastText library) trained to classify if a piece of text would be likely referenced by Wikipedia or not. They also used more compute-intensive Roberta-based classifiers to further filter and generate quality scores for every document. This would be a pretty compute-intensive job just to filter down the data.
Next, they clean the text and HTML to make sure they have non-truncated HTML documents. They wrote their own HTML parser that optimized for the precision of removing boilerplate and recall of keeping content.
They then de-duplicate the data at the URL level, document level, and line level.

They also wrote some heuristics to filter other low-quality documents, such as ones that repeated themselves, contained dirty words, or super uncommon words. I wonder why they filtered out documents containing excessive numbers of outlier words because you definitely want rare words. Maybe it’s just if the sentence is all rare tokens, it is probably garbage.
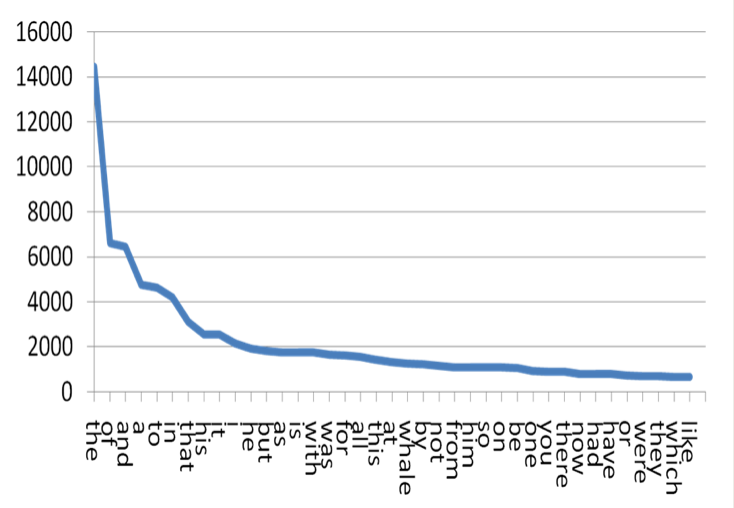
Words in the English language follow a logarithmic curve for how often they are used. Interesting scientific words or people’s last names are going to be at the bottom of the curve, and less likely to be seen in the training data.
Code and reasoning data had a different pipeline for cleaning. First, they decide if the web page has this type of data. Then, they employ custom extraction pipelines to preserve the content. For multilingual data, they also use a fastText classifier to determine the text’s language (176-way classification) and perform document-level and line-level deduplication per language. This classification also helps them balance the mixes of data later.
Data Mixology - They have another classifier that classifies text into “types of information contained on the web”. Then downsample over-represented categories, such as arts and entertainment. The “final data mix” contains roughly 50% of tokens in general knowledge, 25% in mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
The full pre-training recipe includes
- Initial pre-training (which we just went over)
- Long-context pre-training
- Annealing
Long-context pre-training
In long-context pre-training, they incrementally increased the context length over 6 different lengths and included longer context data. They then trained it until it recovered original performance from short context evaluations and solved needle-in-the-haystack queries with as close to 100% accuracy as possible. They only trained long context on 800B final training tokens.
Annealing
Annealing here means that for the last 40M tokens, they linearly annealed the learning rate to 0, making sure to only use the “highest quality” data at the end. They then averaged all the model checkpoints to produce the final pre-trained model.
Post-Training
This is where I think it gets interesting for the rest of us. You probably aren’t training on 15T tokens unless you have hundreds of millions of dollars in the bank.
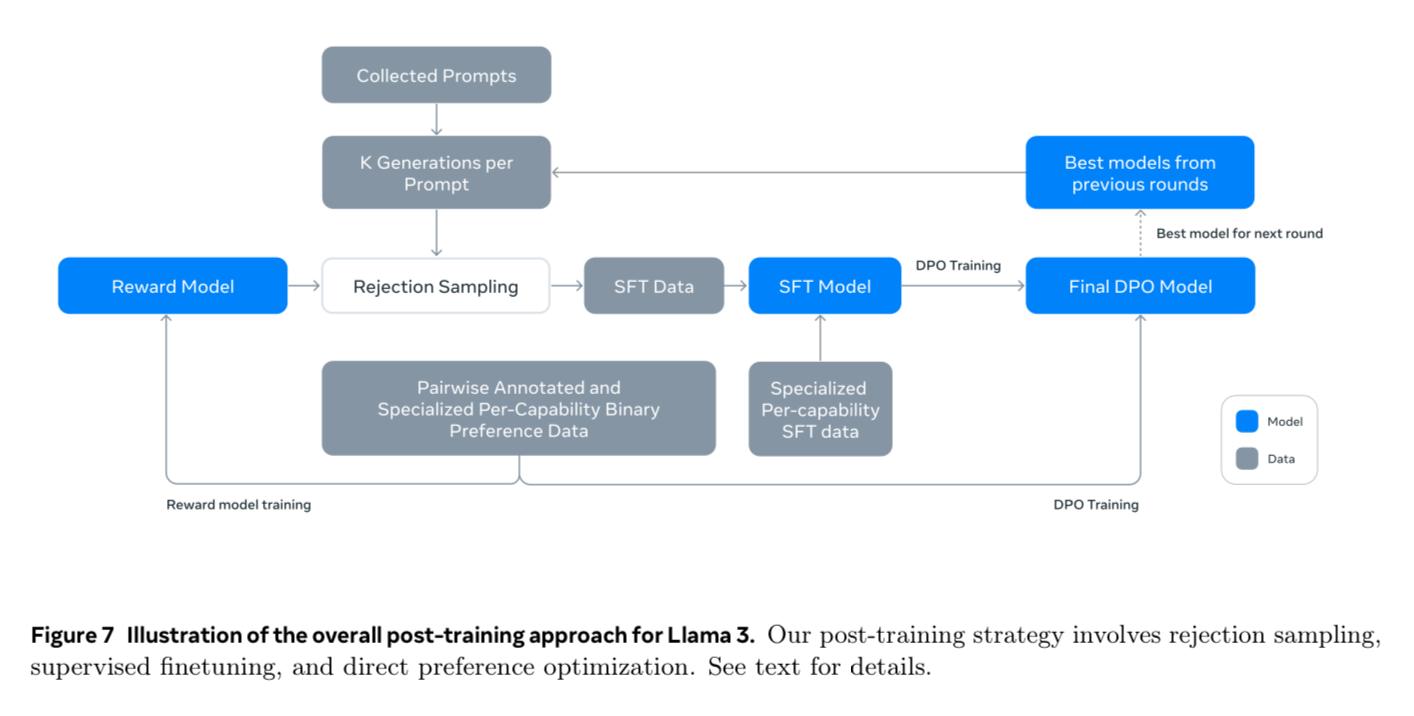
This diagram reminds me a lot of the Self-Rewarding Language Models paper that we did at the start of the year. If you aren’t familiar with that technique I’d recommend you check it out - we did a deep dive on the paper and Raul from our Oxen community wrote some code to try to reproduce the pipeline with smaller models. Here is the link: https://www.oxen.ai/blog/arxiv-dives-self-rewarding-language-models
Meta using this technique is not surprising since it was a team at Meta that released the paper. They apply 6 rounds of the above techniques and in each round, they collect new preference data annotations and supervised fine-tuning (SFT) data, sampling synthetic data from the latest models.
Let’s dive into different parts of the diagram.
Reward Model and Language Model
There are two main models we concern ourselves with in this post-training loop.
- Reward Models
- Language Models
First, they collect a bunch of human-annotated data. This includes many user-generated prompts, as well as human-annotated preference pairs to train the initial reward model. They make a slight tweak here, where they add an additional category of data.
edited > chosen > rejected
The edited responses are all “chosen” responses that have been further edited for improvement. This is now a standalone “reward model” that can reject or keep synthetic data in our pipeline. Then, they fine-tune a language model using SFT and further align the checkpoints using DPO. This entire loop is for Llama 405B whenever talking about Llama 3.
Let’s dive deeper into each type of data.
Preference Data
This data is “given a prompt and multiple responses, which response do we like better?” They ask the human annotators to rate the strength of their preference from significantly better, better, slightly better, or marginally better. They also encourage annotators to further improve the prompt to create the “edited” category (which is even better than “chosen”)
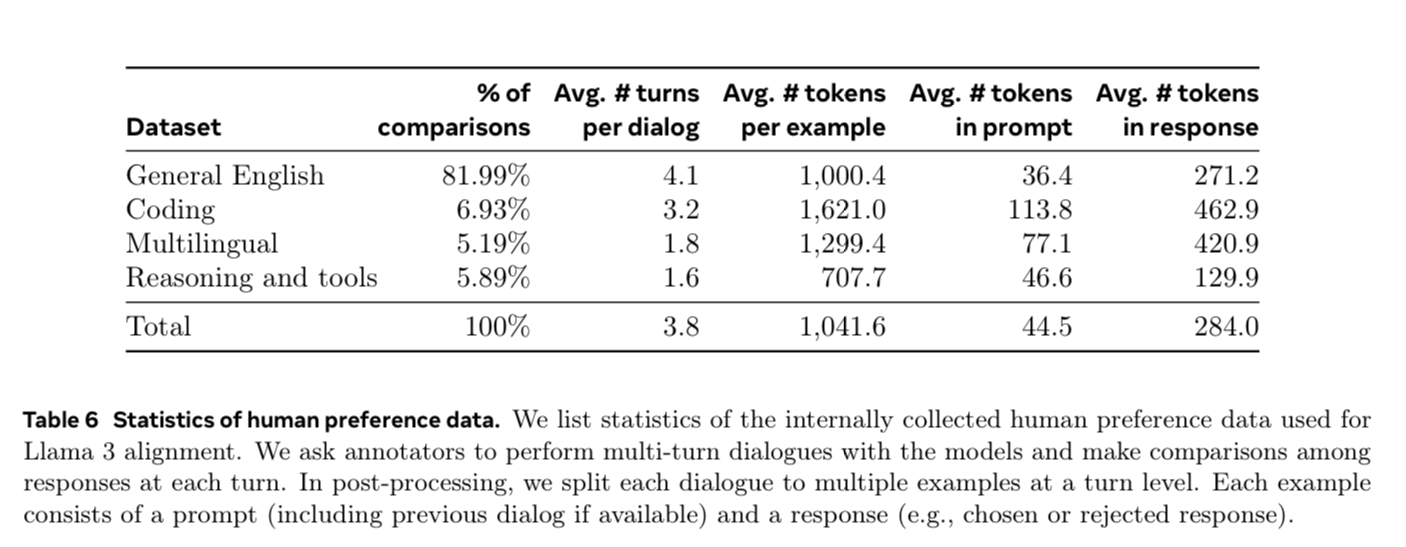
I wish they gave raw data point counts instead of ratios but alas, maybe that is the secret sauce. More is probably better...but how much more? For reward modeling and DPO, they use samples that are labeled as “significantly better” or “better” than the rejected counterpart and discard samples with similar responses.
Again. A lot of classification.
SFT Data
This data consists of data from the human-annotated collection with rejection-sampled responses, as well as synthetic data targeting specific capabilities. For each prompt they collect during human annotation - they sample 10-30 responses from the latest chat model. Then they use the reward model to select the best candidate. In later rounds of post-training, they also introduce system prompts to steer the responses to conform with a desirable tone, style, or formatting. This only works in later iterations after it has learned to follow instructions in the first place.
Synthetic Data Quality
Since a lot of the training data is model-generated, it requires careful cleaning and quality control. First, they apply a set of rule-based filters to reject obvious bad text from the earlier iterations of models (such as excessive use of emojis or exclamation points). I thought this part was quite entertaining. They identify tonal issues such as overly-apologetic tones (I’m sorry, I apologize) and carefully balance these as well.

Fun anecdote - I remember running Oxen community member Cameron’s “impossible questions” through GPT-4o and seeing how often it repeated itself at the start.
They also used model-based techniques to remove low-quality synthetic data. They fine-tune Llama 3 8b to classify topics into different buckets. Then they generate a quality score based on Llama 3 to rate each sample on point scales. After the responses are graded they select samples that are marked as high quality from either the Reward Model or the Llama-based filters. An additional priority is given to difficult examples that would be complex for the model to solve. Finally, they semantically deduplicate the data by clustering complete dialogues using RoBERTa and then sort them by quality score x difficulty score. All this to say is it is quite the extensive pipeline to make sure you have high-quality synthetic data! Classify, rank, cluster, and repeat until you are “confident” this sample can be fed back into the model.
Let’s return to the chart above to see if we can follow along now.
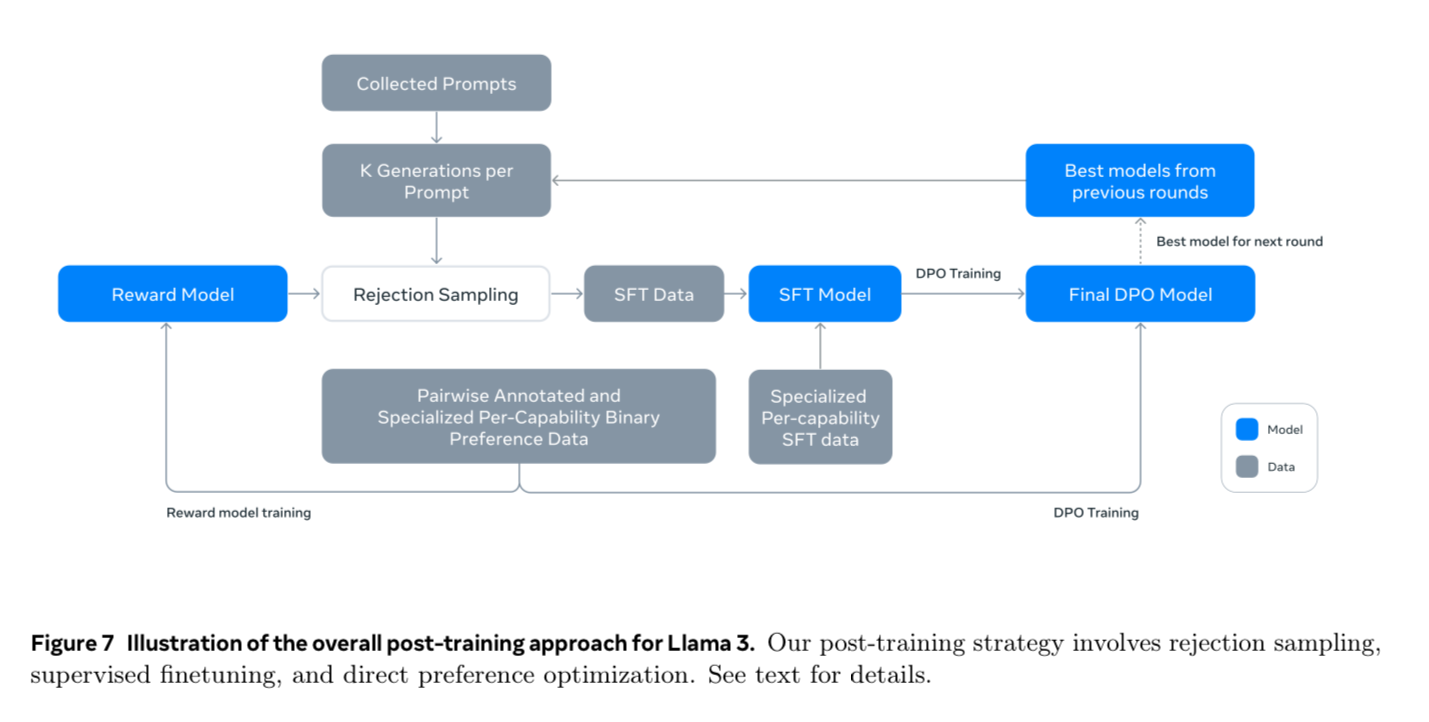
- Collect human-generated prompts
- Sample 10-30 responses per prompt
- Reject samples with a Reward Model (or human annotation for the first round?)
- Use this data to SFT the model
- They generate specialized data for different capabilities here
- Train the model with DPO
- Generate more preference data to feed into a new reward model. I think they train a new reward model each time?
Repeat with the new models!
Capabilities
You’ll notice that above during SFT and pairwise annotated boxes, they say “per-capability”.
There are some clear use cases and capabilities that are emerging for LLMs, so they prioritize generating data from these distributions.

Honestly, these were the most practical and tactical parts of the paper in my opinion, get out your popcorn.
- Code
- Multilinguality
- Math & Reasoning
- Long Context
- Tool Use
- Factuality
- Steerability
I almost feel like each one of these deserves a Dive on its own, and they probably had a whole team working on each. I’ll go over the code, then I’m curious if you all would want to do deeper dives or practical dives on synthetic data generation techniques similar to this. If so...let us know in our community discord!
Code
For code, they prioritized Python, Java, JavaScript, C/C++, Typescript, Rust, PHP, HTML/CSS, SQL, and bash/shell. Looks like something I would look for on a software engineer's resume. First, they train a “code expert” model which is used to collect high-quality code examples that are then passed to a human to annotate. They do this by forking the main pre-trained model and continuing training on 85% code data. This continual pre-training on domain-specific data has been proven an effective technique to specialize models. Then they get into synthetic data generation for code. 2.7M synthetic examples are used during SFT just for code.
During synthetic data generation, they focused on some key areas
- Difficulty following instructions
- Code syntax errors
- Incorrect code generation
- Difficulty fixing bugs
In the paper they mentioned, “While intensive human annotation could theoretically solve these issues, synthetic data generation offers a complementary approach at a lower cost and higher scale, unconstrained by the expertise level of annotators”. This is wild to me that we are getting to the point of models being better and cheaper at checking their own work than humans. They state that the 8B and 70B models show significant performance improvements when trained on data generated by the larger 405B model - however, training Llama 405B on its own generated data was not helpful and can even downgrade performance. To address this in 405B they add “execution feedback” as a source of truth.
How they do it:
1) Generate Problem Description
They sample random code snippets from various sources and prompt the model to generate programming problems inspired by these examples.
2) Solution Generation
Prompt the model to then solve the problem in multiple programming languages.
They add general rules of good programming to the prompt to improve the generated solution quality.
3) Correctness Analysis
After generating a solution, they need to check if the solution is correct.
- Pass through parsers and linters to catch syntax errors, etc...
- They generate unit tests as well and see if they pass.
4) Error Feedback and Self-Correction
If the solution fails at any point, they prompt the model to revise it. They include any errors from linters or unit tests above.
About 20% of solutions were initially incorrect and able to be self-corrected.
5) Fine-tuning / Iterating improvement
The fine-tuning processes are then conducted over and over again like the loop we saw above.
6) Translating languages
To get better results in low-resource languages (like typescript/php) they actually use a model to translate solutions from one programming language to another.

They generate, back translate to the original code, then use llama 3 to determine how faithful the back-translated code was to the original, filtering out ones that got lost in translation.
Sections 4.3 go into more domains that they had domain-specific logic for and I think could make an interesting set of deep dives into each if you all are interested
- Code
- Multilinguality
- Math & Reasoning
- Long Context
- Tool Use
- Factuality
- Steerability
Conclusion
It’s hard to cover a 92-page paper in a single session, but hopefully, this gave you a sense of how much data work goes into pre-training and post-training of foundation models. Each step is a full engineering team in itself. If you want to get a job at Meta or any of the big labs working on foundation models, I think there are many little nooks and crannies you could fit into.
Before we wrap up, we wanted to point out that the list of contributors is like a Hollywood movie credit roll. There are three pages of this:
