ArXiv Dives:💃 Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling


Modeling sequences with infinite context length is one of the dreams of Large Language models. Some LLMs such as Transformers suffer from quadratic computational complexity, making the infinite context length problem computationally infeasible. While other models such as linear recurrent neural networks are great for speed, but lack the ability to remember details far back in it’s context.
Samba fixes these issues by combining Mamba layers with Sliding Window Attention (SWA) and Multilayer Perceptions (MLP) to create a model with hybrid of techniques.
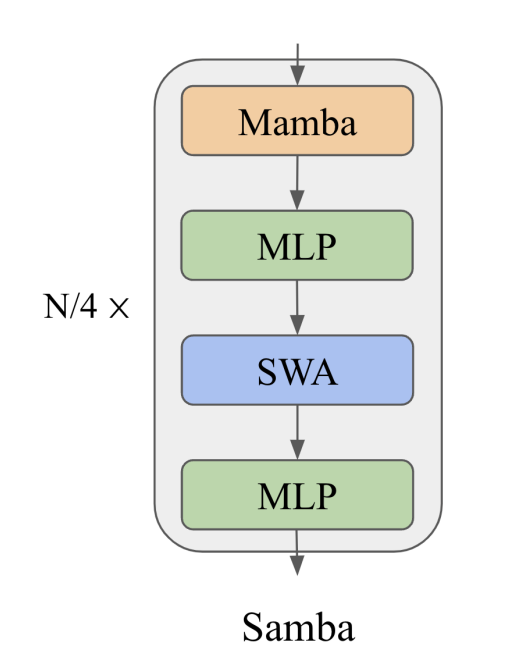
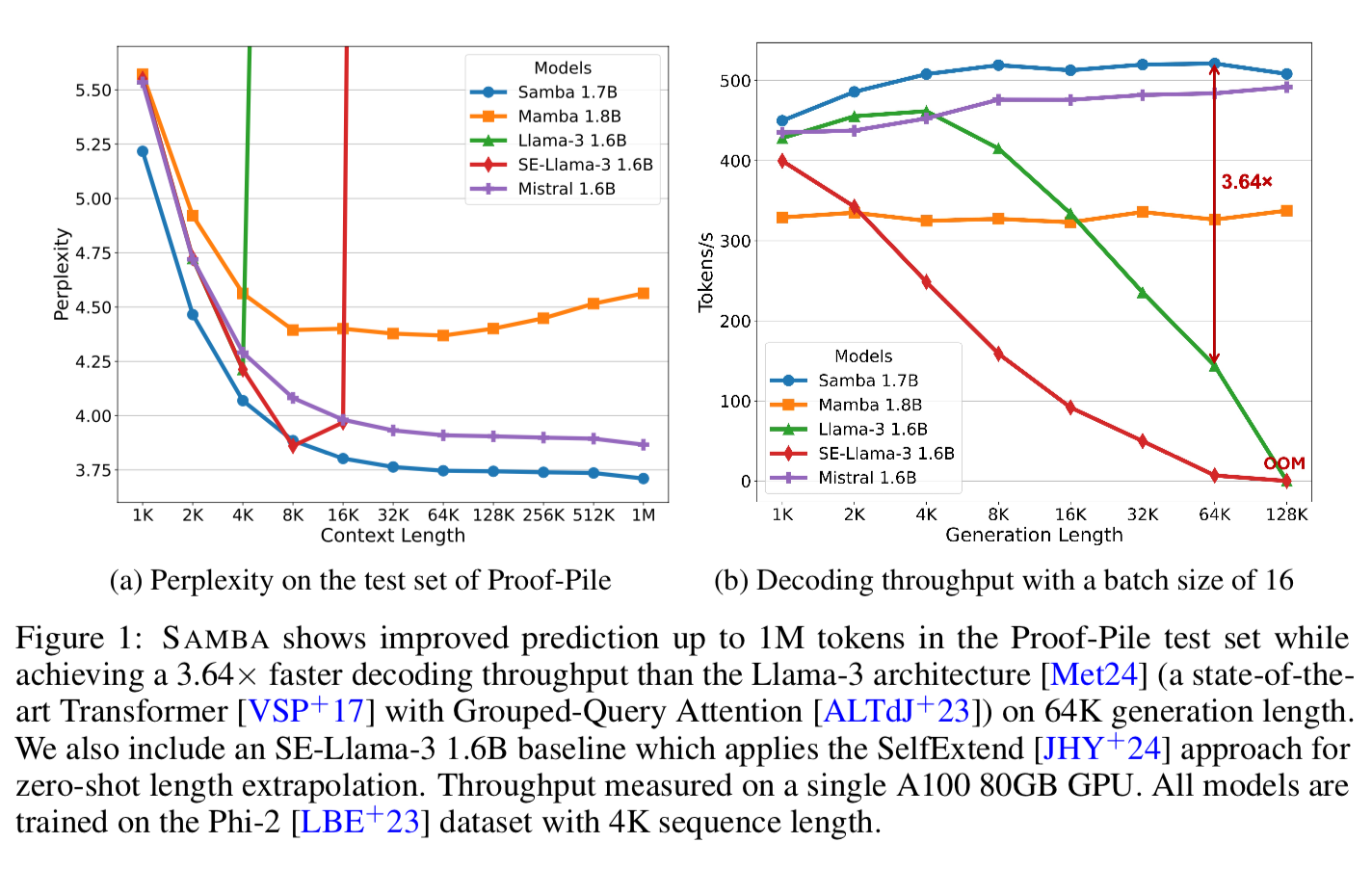
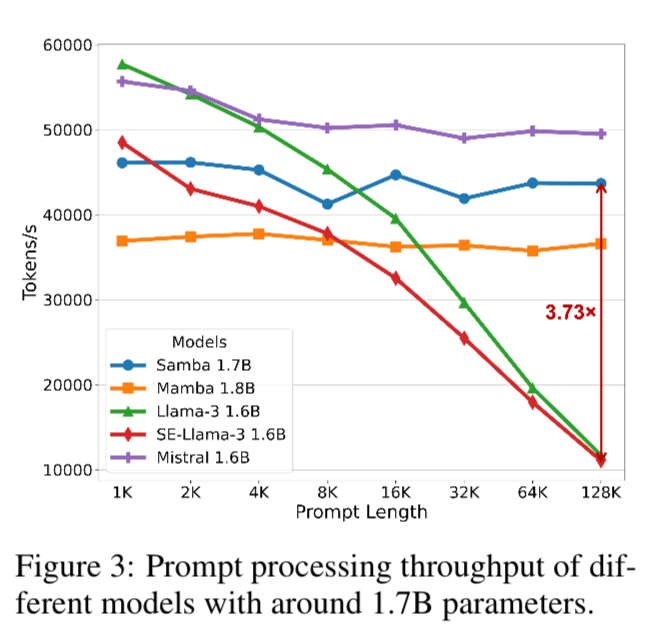
Each one of these layers are like legos or building blocks. If you understand the motivation behind each layer, you can start stacking them and combining them in interesting ways to gain performance in terms of both accuracy and throughput. They scale SAMBA up to 3.8B parameters trained on 3.2Trillion Tokens, showing that SAMBA outperforms state of the art models based on pure attention or state spaces. SAMBA has 3.73x higher throughput than transformers and can recall up to 256K tokens with perfect memory recall, while maintaining perplexity up to 1M content length.
Breaking Down the Building Blocks
The hybrid model consists of three main layers:
- Mamba Style State Spaces - great for speed, and modeling recurrent sequences
- Sliding Window Attention - precise retrieval of memory
- Multi-Layer Perceptions - factual knowledge
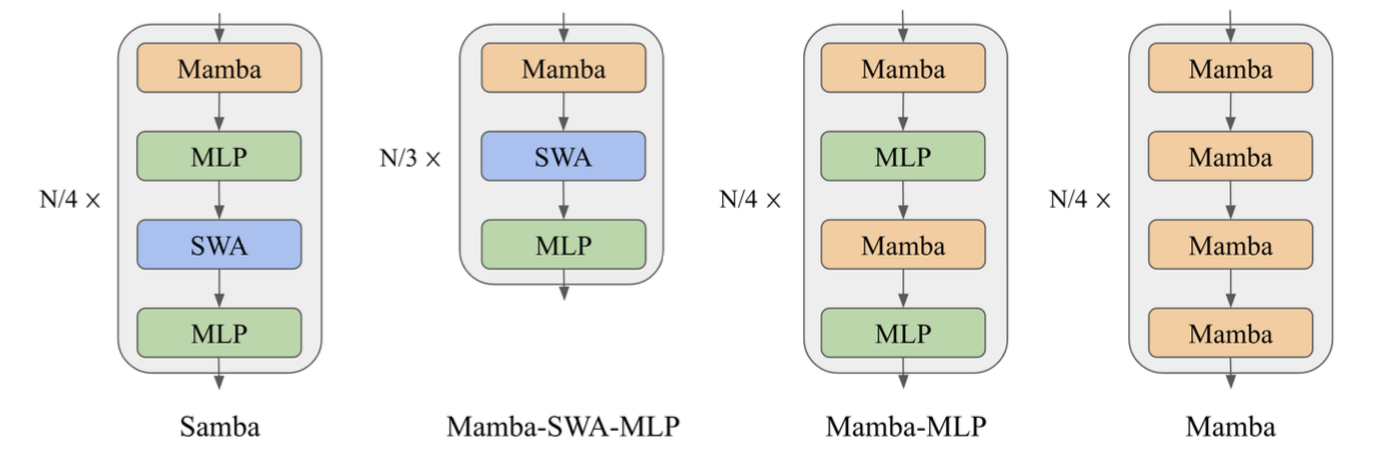
They compare 4 different configurations:
Mamba Layers
We will not dive too deep into the math here since we did in a previous dive.
https://www.oxen.ai/blog/mamba-linear-time-sequence-modeling-with-selective-state-spaces-arxiv-dives
You can think of it as an efficient recurrent network that scans one token at a time, selectively updating it’s hidden state space.
Mamba layers are heavily inspired by GRU (Gated Recurrent Units) with some optimizations to make them very fast. They are from a family of architectures called State Space Models (SSMs).
The problem with pure mamba layers is you have to cram all that information into the hidden state and selectively decide what to keep or discard.
Sliding Window Attention
They add SWA to help process longer range dependencies that get lost in the hidden state.
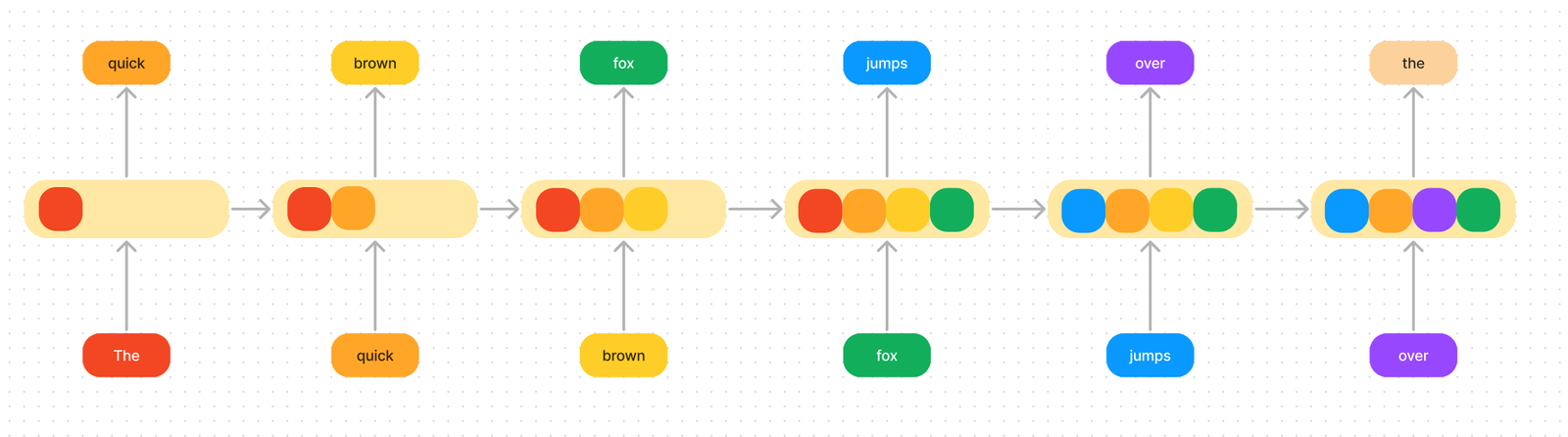
If you remember from our Mistral Dive SWA looks like this:
https://www.oxen.ai/blog/arxiv-dive-how-to-mistral-7b-works
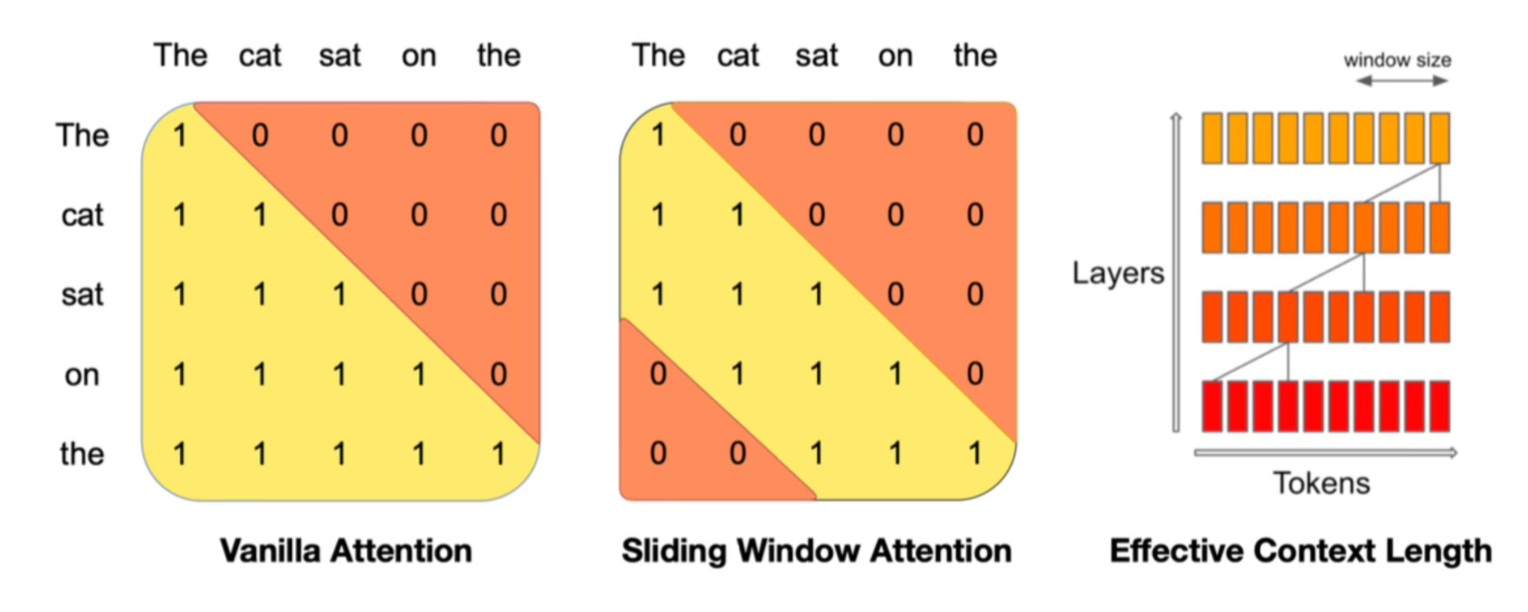
For example in the diagram above, if the window size was 3 and the sentence was "The cat sat on the mat and watched the dog."
- first layer sees “the cat sat”
- second layer sees “on the mat”
- third layer sees “and watched the”
- …. etc
Tokens outside the sliding window can still influence the next word prediction. In each layer the information can move forward by W tokens, so if you have k layers, information can move forward by k*W.
W=3
K=12
Each token could attend in theory to 36 previous tokens. This technique helps alleviate some of the quadratic nature of vanilla attention.
In SAMBA they use a window size of 2048 + RoPE for relative position encodings within the sliding window.
Mamba captures low-rank information about the sequences through recurrent compression. This leaves the attention layers in SAMBA to theoretically only need to focus on information retrieval.
Multi-Layer Perceptions
They use MLPs with SwiGLU activations for all the models in this paper. They argue that these are architecture’s primary mechanism for non-linear transformation and recall of factual knowledge.
Experiments
They train 4 models with different parameter sizes.
421M
1.3B
1.7B
3.8B
They also train a baseline Mamba, Llama-3 and Mistral to compare against.
Let’s take a second to look at the results 👀
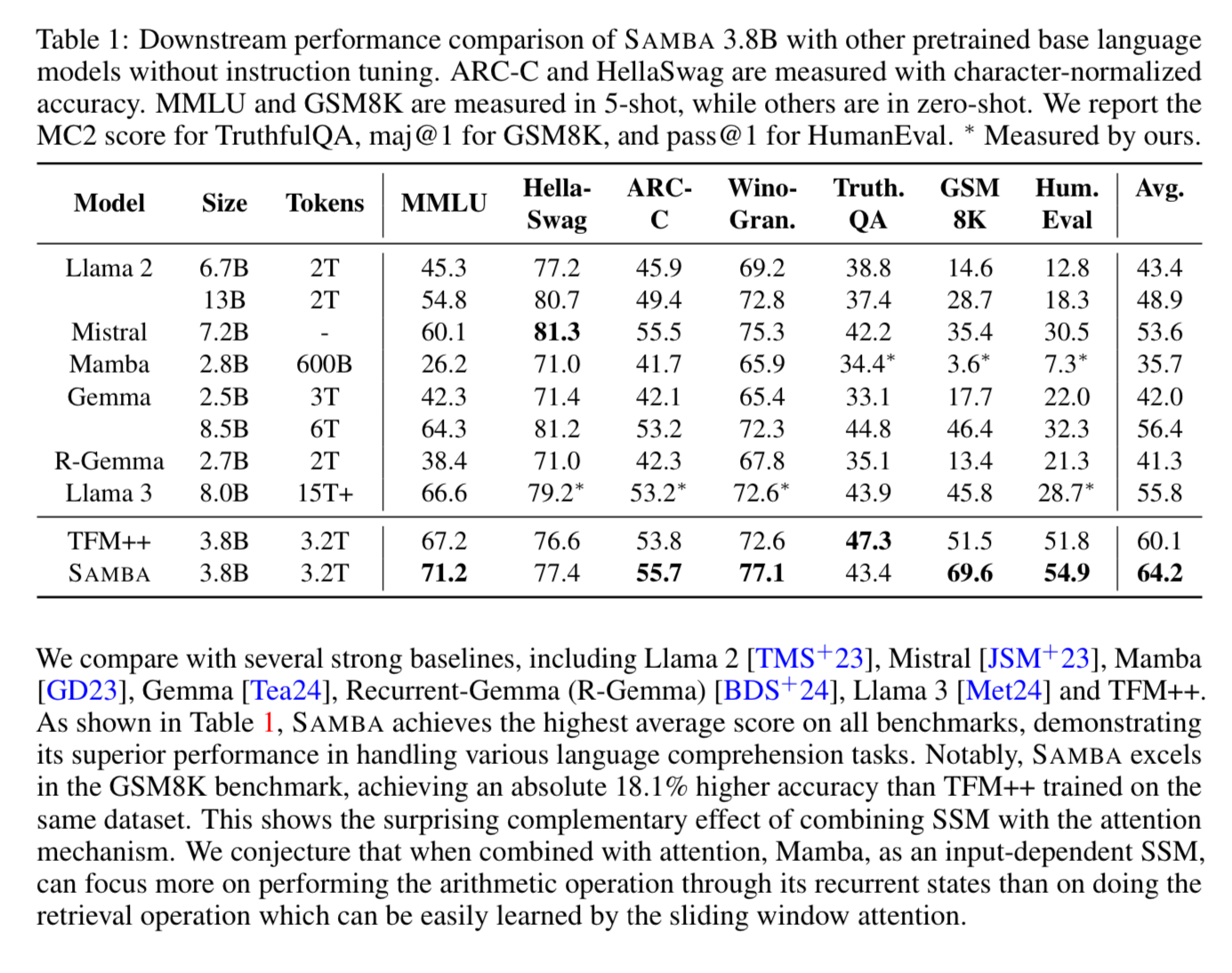
SAMBA 3.8B out performs Llama-3 8B on many tasks.
Training dataset of the same dataset used by Phi3 with 3.2T tokens.
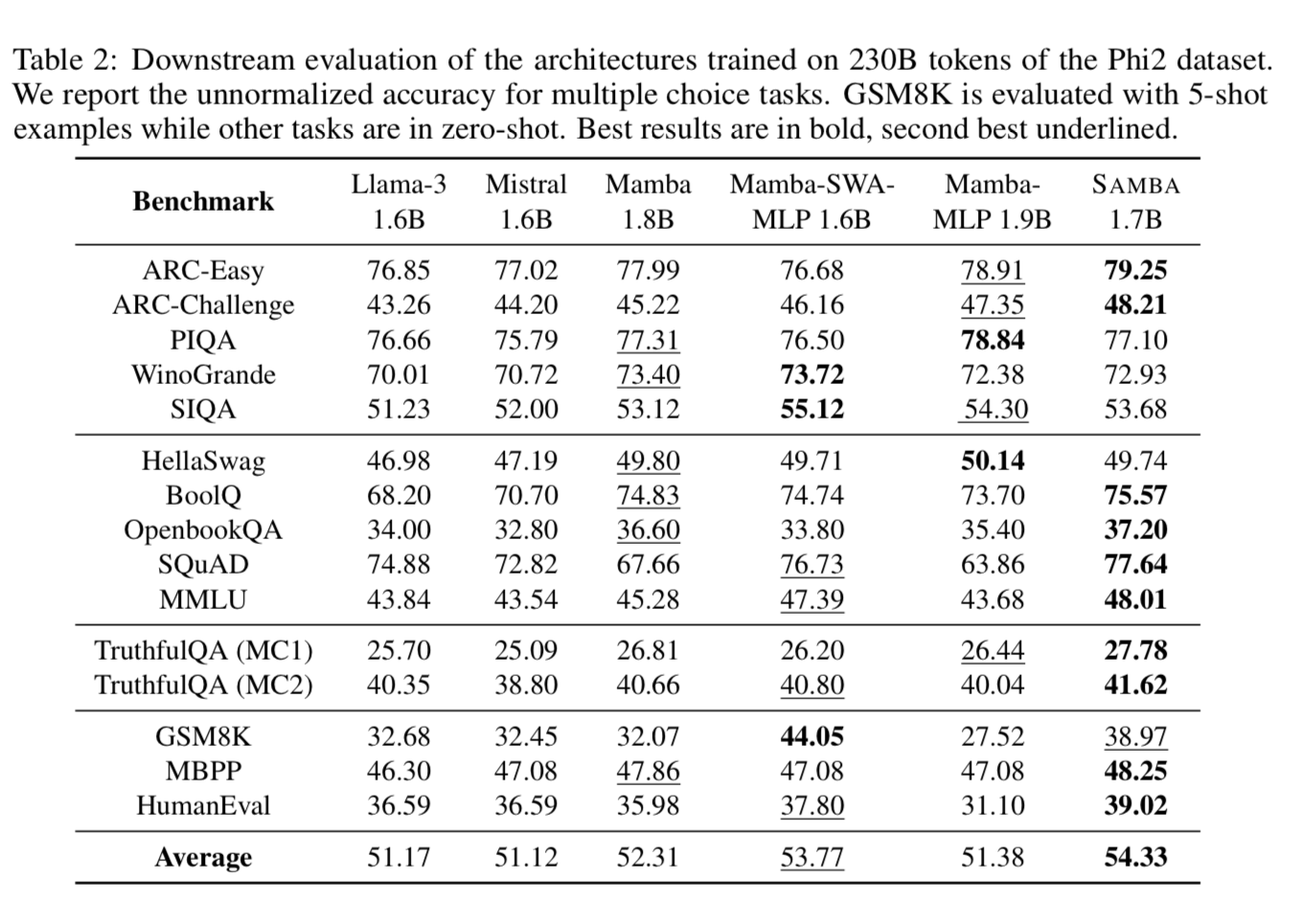
They also did a smaller training run on 230B tokens of the Phi2 Dataset for more apples to apples comparisons 🍎. The chart above they did not normalize for the number of training tokens.
Exploring Attention vs Linear Recurrence
There are other forms of linear recurrence that they benchmark against.
- Llama-2-SWA
- Sliding RetNet (Multi-Scale Retention Layers)
- Sliding GLA (Gated Linear Attention)
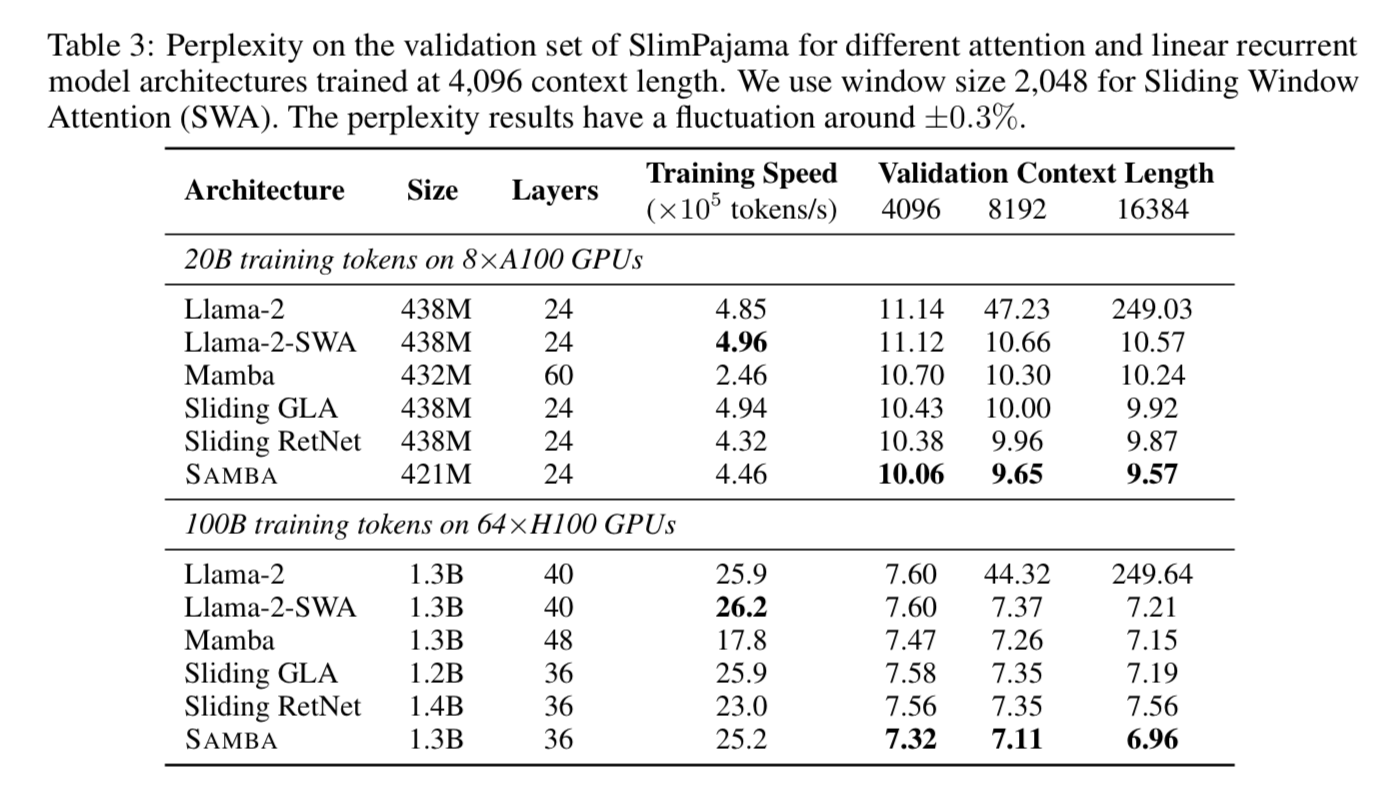
You can see that SAMBA is competitive in training speed, while winning on perplexity at context lengths of 4096, 8192, 16384.
SAMBA has stable throughput compared to models with attention. You’ll notice Mistral has higher throughput, but that’s because it just uses SWA.
That being said, SAMBA outperforms Mistral on Passkey Retrieval up to 256k context length.
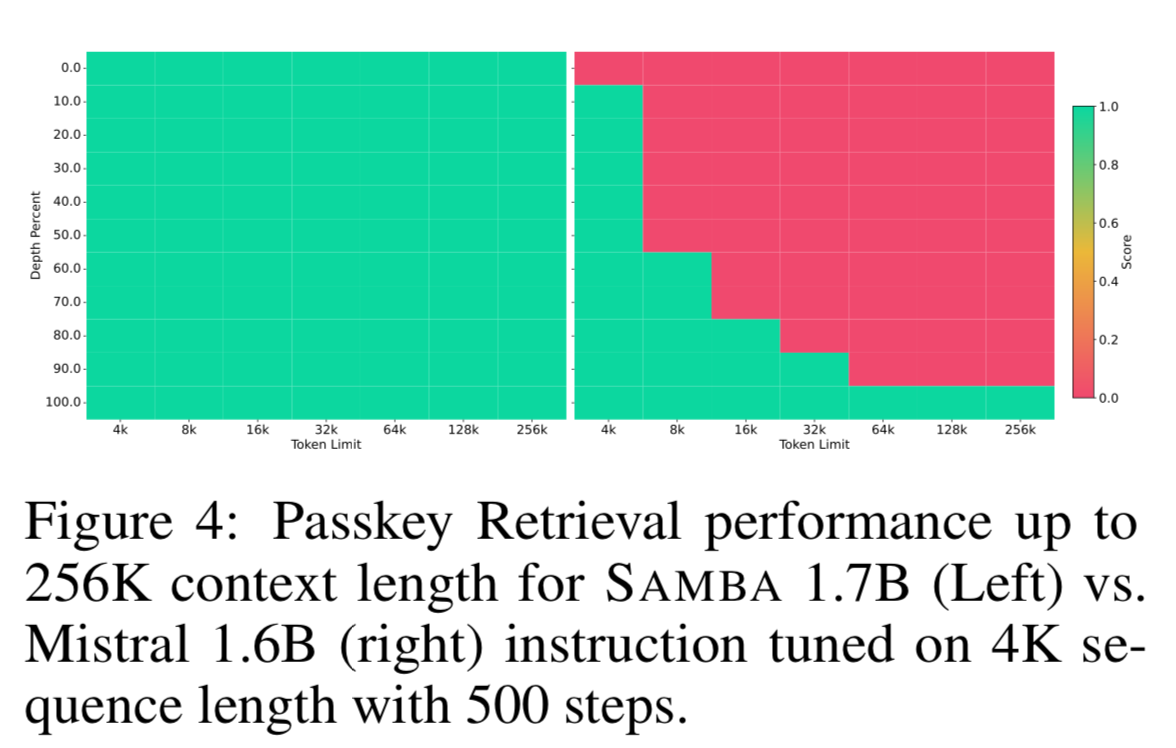
Passkey retrieval is a task that requires a language model to retrieve a five-digit random number (passkey) in a long meaningless text sequence.
Conclusion
The combination of building blocks within SAMBA give it a nice balance of throughput vs context length vs language modeling. It outperforms both pure attention-based and SSM-based models on a wide variety of benchmarks. It’s super promising for long context retrieval tasks, and I’m excited to see where the researchers take it next!