Oxen.ai Blog
Welcome to the Oxen.ai blog 🐂
The team at Oxen.ai is dedicated to helping AI practictioners go from research to production. To help enable this, we host a research paper club on Fridays called ArXiv Dives, where we go over state of the art research and how you can apply it to your own work.
Take a look at our Arxiv Dives, Practical ML Dives as well as a treasure trove of content on how to go from raw datasets to production ready AI/ML systems. We cover everything from prompt engineering, fine-tuning, computer vision, natural language understanding, generative ai, data engineering, to best practices when versioning your data. So, dive in and explore – we're excited to share our journey and learnings with you 🚀
The goal of this paper is to see if we can create a self-improving feedback loop to achieve “superhuman agents”. Current language models are bottlenecked by labeled data from human...

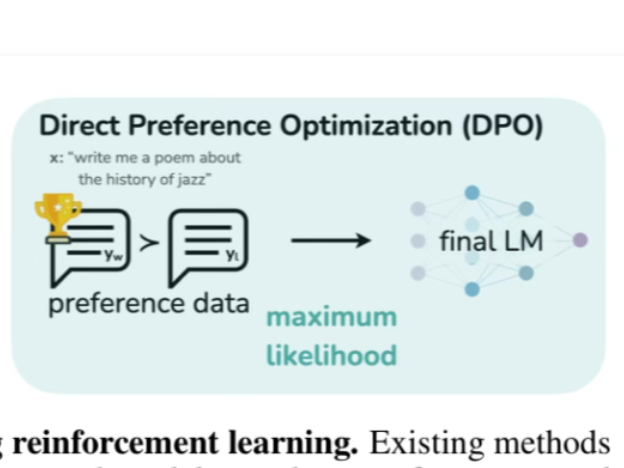
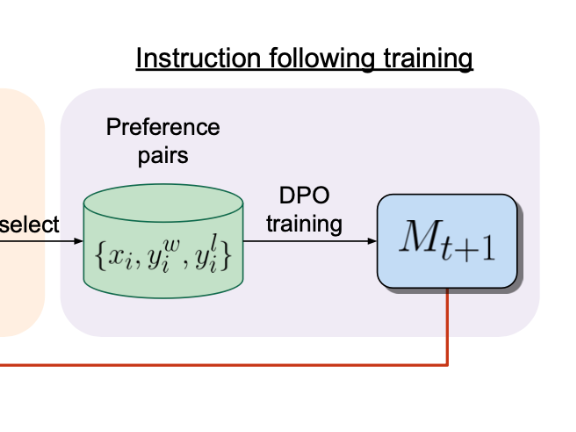
This paper provides a simple and stable alternative to RLHF for aligning Large Language Models with human preferences called "Direct Preference Optimization" (DPO). They reformulat...
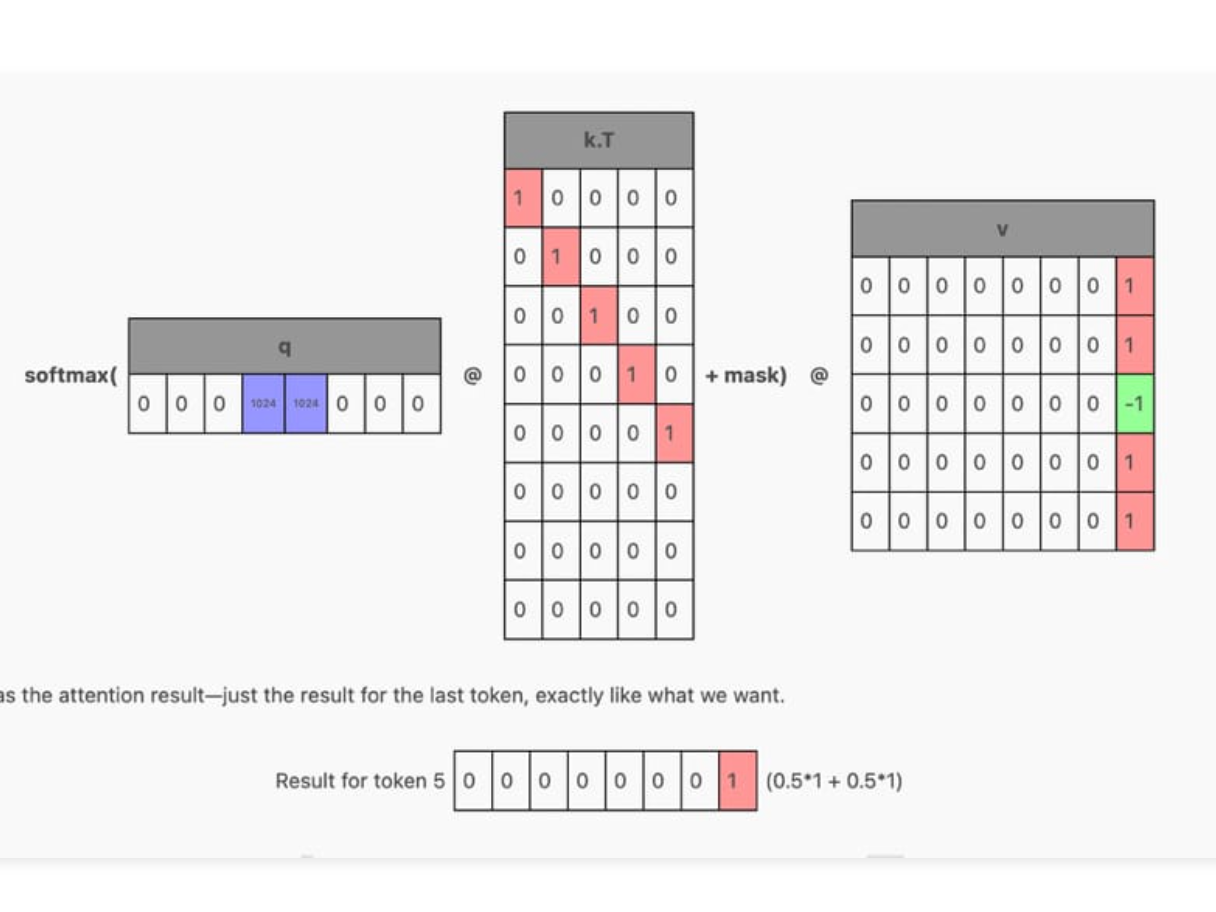
This paper introduces the concept of an Attention Sink which helps Large Language Models (LLMs) maintain the coherence of text into the millions of tokens while also maintaining a ...

Mixtral 8x7B is an open source mixture of experts large language model released by the team at Mistral.ai that outperforms Llama-2 70B and GPT-3.5 on a variety natural language und...

What is LLaVA? LLaVA is a Multi-Modal model that connects a Vision Encoder and an LLM for general purpose visual and language understanding. Paper: https://arxiv.org/abs/2304.084...
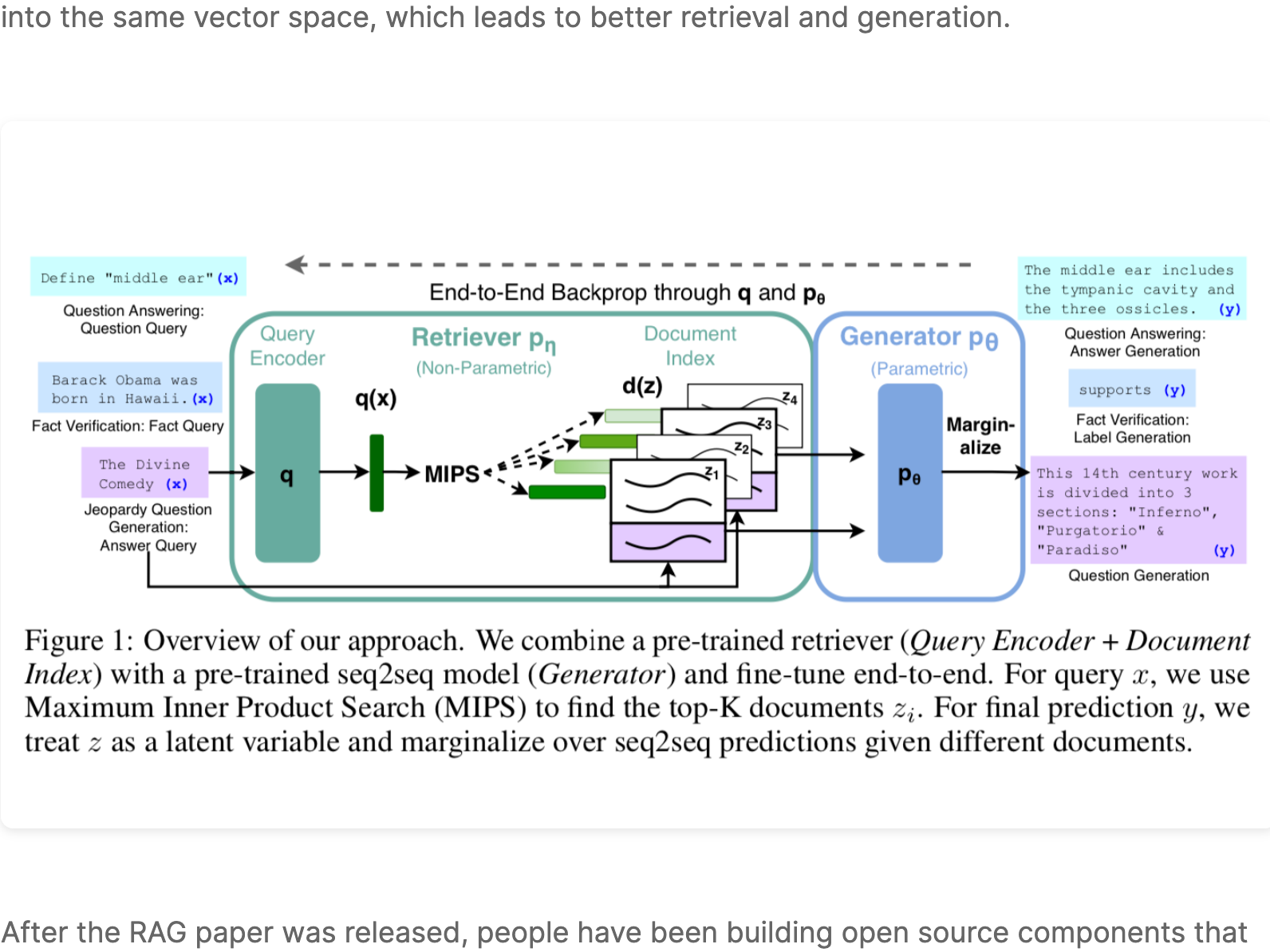
RAG was introduced by the Facebook AI Research (FAIR) team in May of 2020 as an end-to-end way to include document search into a sequence-to-sequence neural network architecture. ...
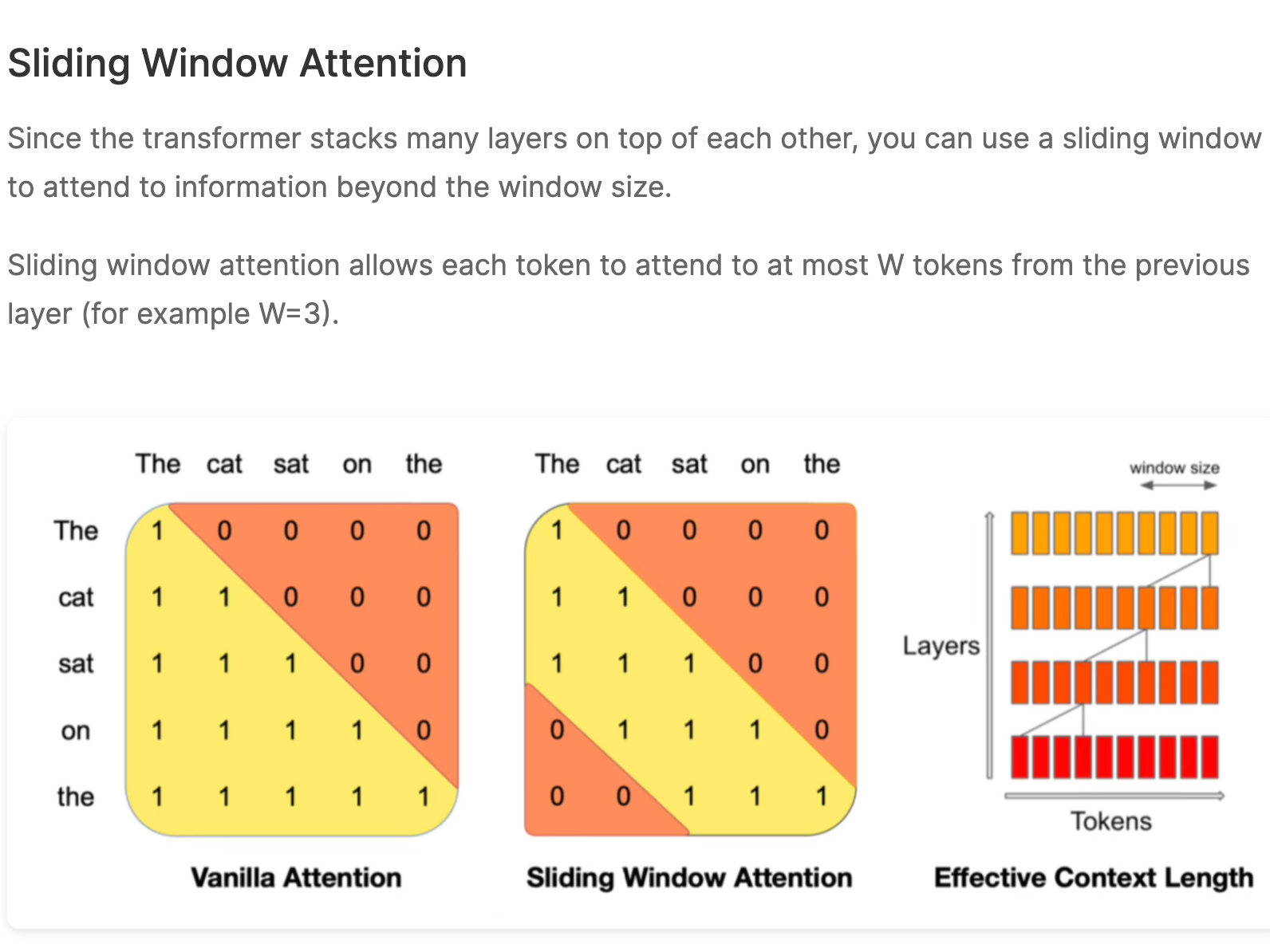
What is Mistral 7B? Mistral 7B is an open weights large language model by Mistral.ai that was build for performance and efficiency. It outshines models that are twice it's size, i...

What is Mamba 🐍? There is a lot of hype about Mamba being a fast alternative to the Transformer architecture. The paper released in December of 2023 claims 5x faster throughput w...

What is Mamba 🐍? Mamba at it's core is a recurrent neural network architecture, that outperforms Transformers with faster inference and improved handling of long sequences of len...
Welcome to Practical ML Dives, a series spin off of Arxiv Dives. In Arxiv Dives, we cover state of the art research papers, and dive into the gnitty gritty details of how AI model...