ArXiv Dives: How ReFT works

ArXiv Dives is a series of live meetups that take place on Fridays with the Oxen.ai community. We believe that it is not only important to read the papers, but dive into the code that comes along with them to truly understand the implications, impact, and be able to apply the learnings to your own work.
This Friday we were lucky to have the lead author of the paper Zhengxuan Wu (Zen) joining our live discussion. He does a fantastic job describing the benefits orthonormal constraints in the LoReFT model vs the DiReFT model, as well why this technique is more parameter efficient. There are many hidden gems and tips and tricks they thought of during training and inference during this session.
The following post are notes from our live conversion, feel free to follow along with the video below.
Paper & Code
This paper introduces a method called Representation Fine Tuning (ReFT) that operates on a frozen base model, but intervenes with hidden representations in order to learn task specific representations.
It is relatively straight forward to integrate ReFT into your own fine-tuning regiment with their open source library and examples.
 stanfordnlp
stanfordnlpOne of the big advantages of using ReFT is the pure fine-tuning speed. It takes 18 minutes to train our Llama-2 Chat 7B on 1K examples using a single A100 40G GPU with ≈1MB parameters on disk. Other techniques like LoRA can take hours with a similar setup. We'll dive into the details of how this performance increase is gained later in this post.
Introduction
ReFT is a part of a family of methods called Parameter Efficient Fine Tuning (PeFTs), but instead of updating and operating on the weights themselves, it keeps the weights frozen, and steers the “representations”.
What’s interesting about this paper is that it claims to both be 15x-65x more parameter efficient than LoRA, while delivering better results on common sense reasoning tasks. One thing to note is that in this case the reduced number of parameters actually affects training time more than inference time here, but we will get into why later.
This dive builds on ideas explored in many of our previous dives and we are going to have a few callbacks to dives such as: Transformers, LoRA, and Scaling Monosemanticity. I would recommend you check out those previous dives if you want to go deeper into the fundamentals we have already covered.
Background
Large language models are powerful tools, but may not be suited for every task out of the gate. When building models in the real world, there are always going to be instances where the model messes up. Either giving the incorrect answer because it did not know, or the world around it changed so the fact is no longer true.
IE: What team does LeBron James play for?
As we’ve seen on many previous dives, fine-tuning is one of the many ways to customize a language model to add new information, behaviors, or functionality.
Fine tuning the entire set of weights in a Transformer is computationally expensive and may not be feasible with smaller consumer GPUs or hardware. In order to solve this problem, parameter efficient fine tuning (PEFTs) methods have gained popularity.
The paper mentions three existing categories of PEFTs:
- Prompting (in context learning)
- LoRA
- Adapter based methods
Prompting
The easiest and most popular is prompting. By simply prepending text to the start of generation process, we “prime” the LLM into generating subsequent tokens. This keeps the LLM weights frozen, but updates the outputs based on the prefix. You can think of this as a mini form of fine-tuning where the context gives the LLM enough information to change it's response.
LoRA
LoRA has become a popular method for fine-tuning. The trick is that you can avoid training the weights of the entire model by simply training a small low rank matrix on the side of the network that you can merge back in to the original weights.
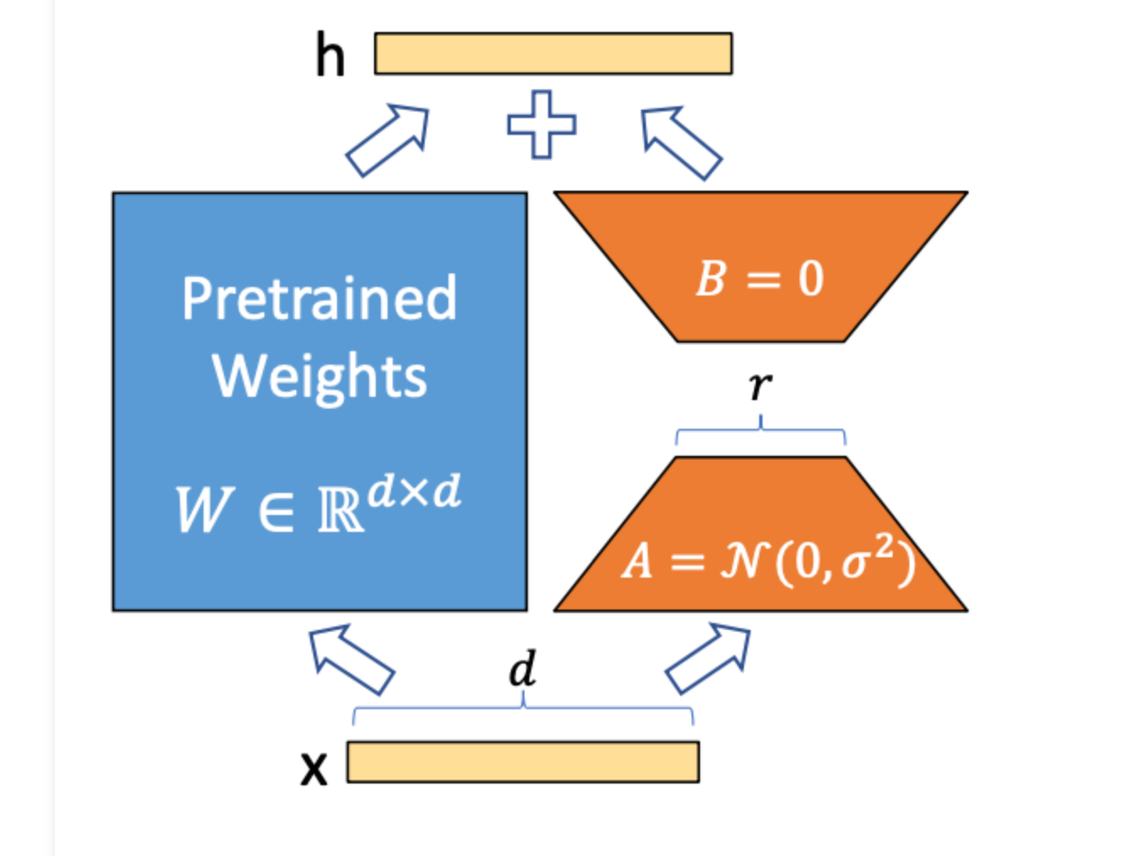
This has the benefit of no additional overhead during inference time and is relatively efficient to train.
Adapter-Based Methods
These methods add additional layers either at the end or inbetween layers that are learnable. These add additional inference overhead, and cannot be folded cleanly into the existing weights.
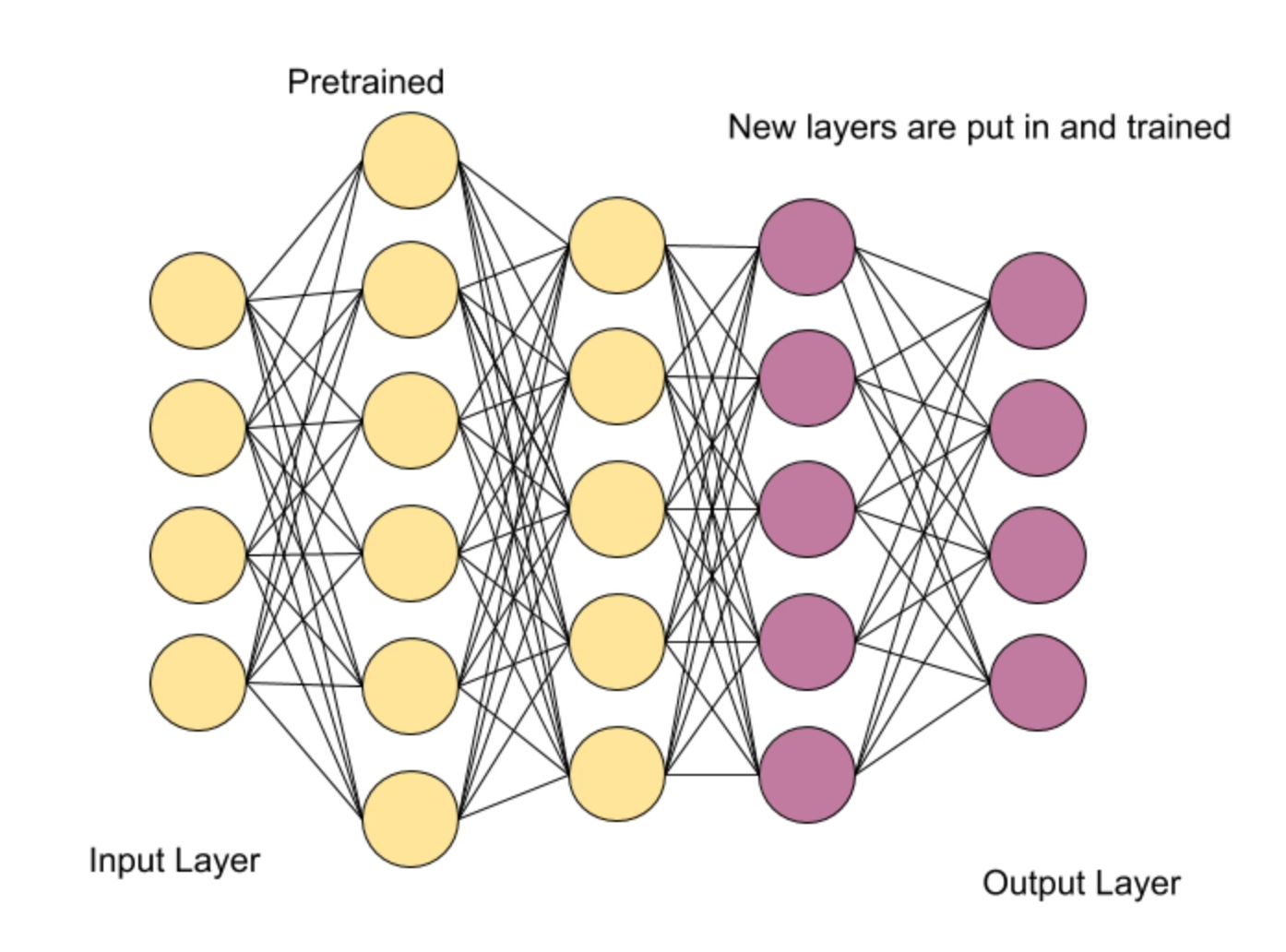
Image Source: https://www.danrose.ai/blog/transfer-learning-from-a-business-perspective
ReFT is closest to the Adapter based method, where it adds additional parameters or "interventions" around the intermediate representations of the model.
Enter ReFT
In the paper they state this work is inspired by work on intervention-based model interpretability. A great example of intervention based interpretability is a paper we covered month or so ago: Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.
Anthropic’s work into interpretability suggests that editing representations may be a more interpretable and powerful method that pure fine-tuning. What they did in the Scaling Monosemanticity paper was learn a sparse auto encoder in order to decompose representations and allow you to steer the outputs of an LLM.

For example, they could activate a specific neuron in this sparse representation and convince the model it was the Golden Gate Bridge.
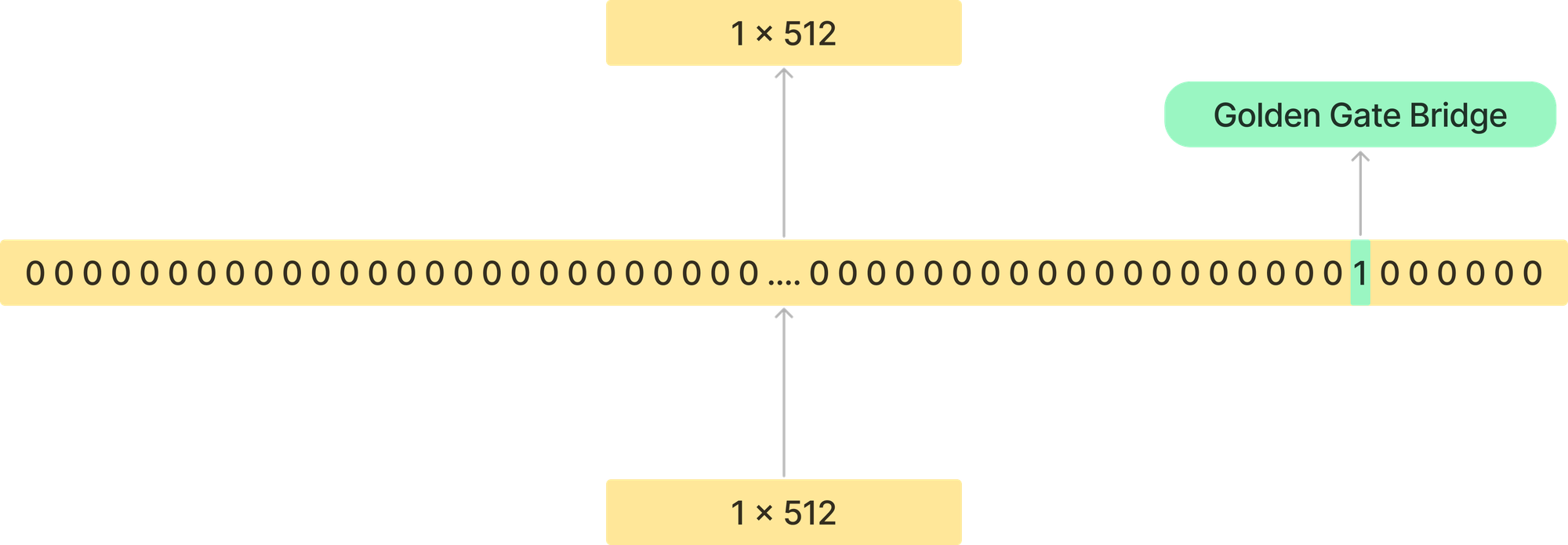
Then for the same prompt, you can get vastly different responses.

I saw a joke on twitter than was “the difference between Claude 3 and Claude 3.5 was they just turned on the smart neuron”.

The idea behind ReFT is conceptually similar. The idea is that since the “representations” encode rich semantic information, what if we just edit the representations instead of editing the weights?
What do they mean by representation?
Let’s look at a simple feed forward neural network.
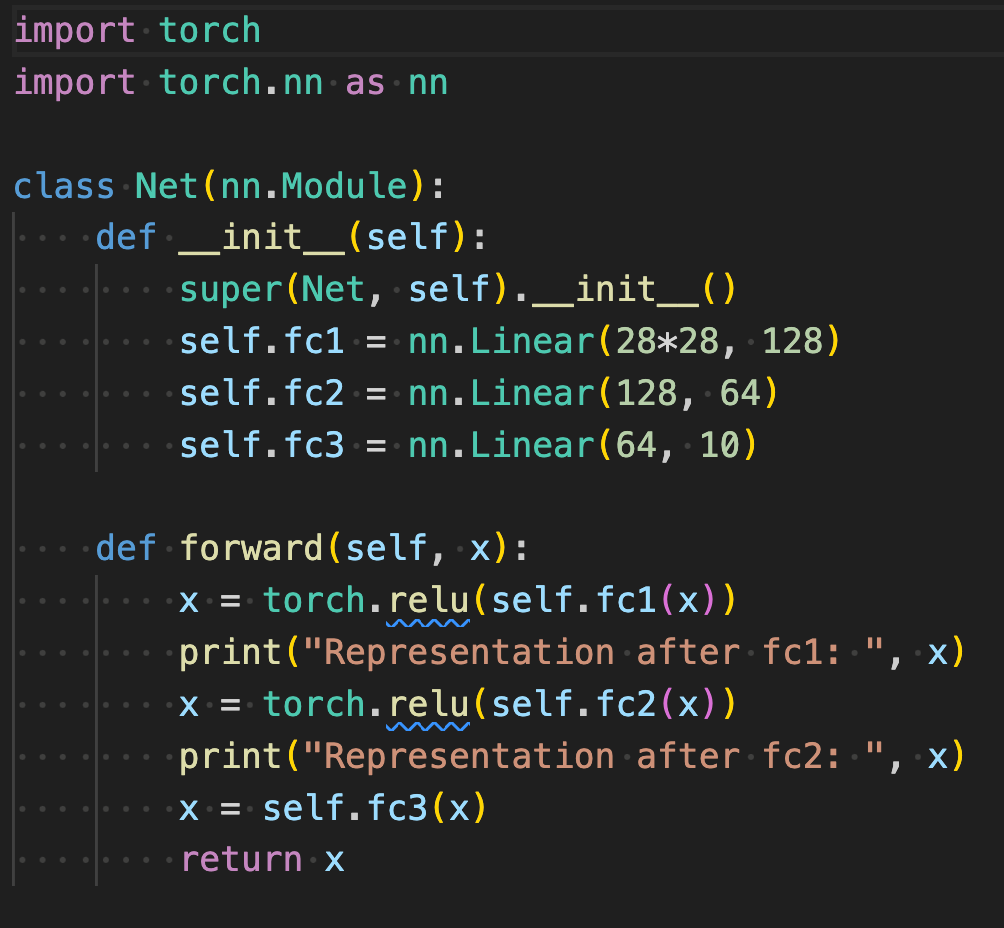
Assuming the network is taking in a 28*28 image (such as MNIST) we are printing the compressed representations of the image at different layers. Each layer is a different level of abstraction encoding different information. For example later representations may represent concepts like "cat" or "dog" where earlier ones may encode lines, edges, etc.
In this paper, they assume the model is not a simple linear neural network, but a Transformer. If you remember our Transformer diagram, tokens flow through the model as “embeddings” and they get updated as they attend to other tokens.
Let's use the word "Paris" as an example. Depending on the context, the token "Paris" may flow through the Transformer and it's representation may get changed from "Paris, France" to "Paris Hilton" affecting which token gets generated next.
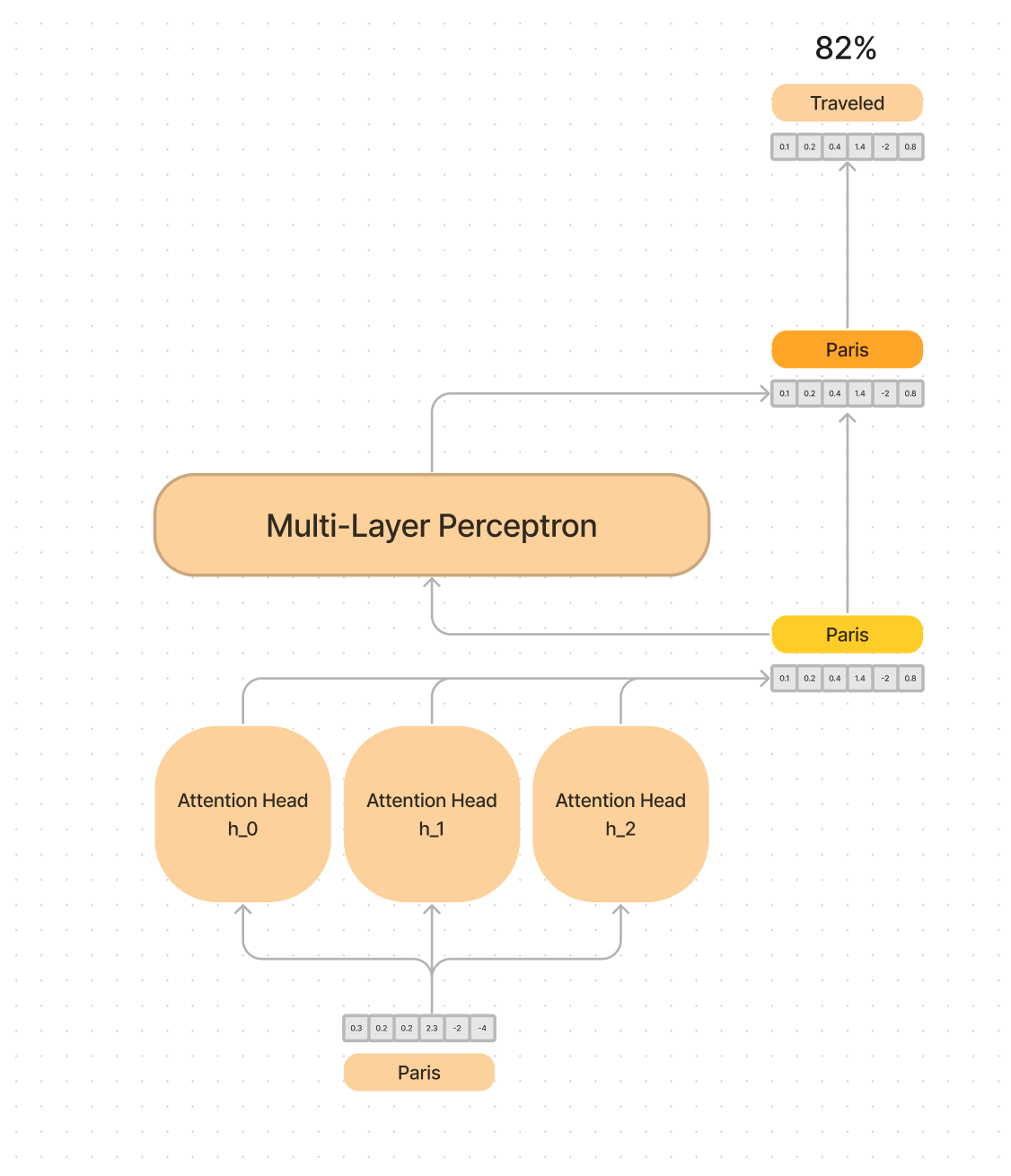
Every time token flows through a layer of a Transformer, attends to the other tokens, and gets output into the residual stream - we have a new internal “representation”.
ReFT comes in and applies what they call a “task specific intervention” to this internal representation.
What is a "task specific intervention"?
You can think of an intervention as steering the hidden representations in a direction to help with a specific task. Instead of just flipping on that “one neuron” in our Scaling Monosemanticity example above, we are learning a function to help steer the model, given a dataset.
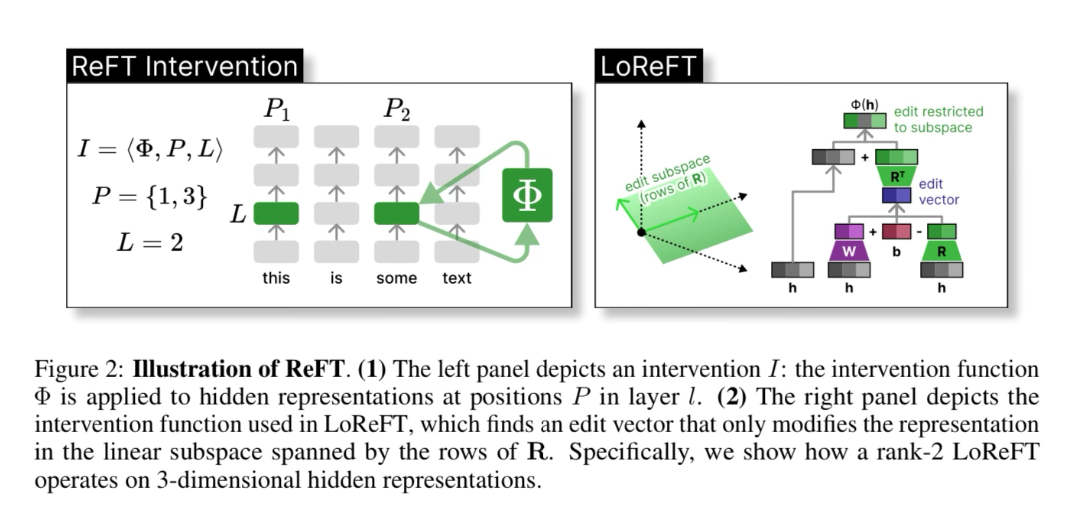
ReFT is a family of methods and more of a framework that they prove out with one particular implementation called LoReFT.
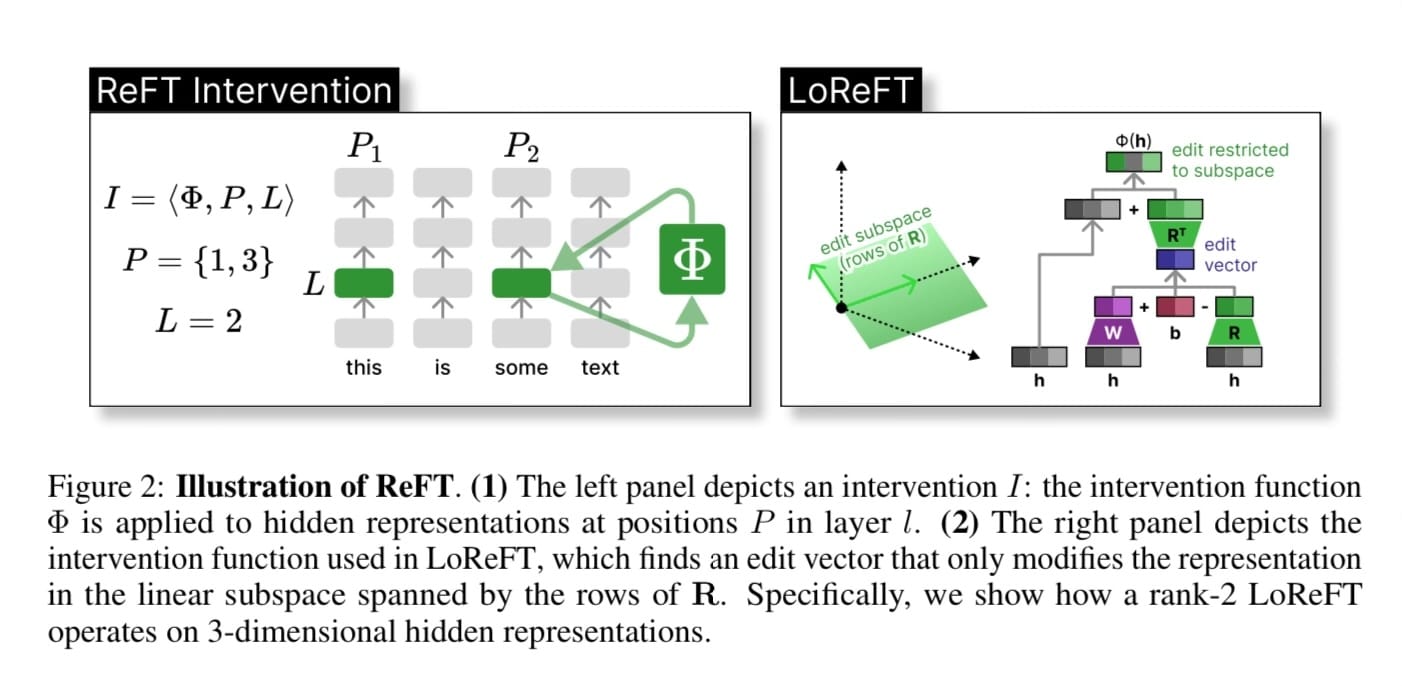
An intervention consists of three parts:
Phi = function that is learned
P = Tokens it is applied to
L = Layers it is applied to
LoReFT takes in a hidden space and learns a function Phi that makes the edit.
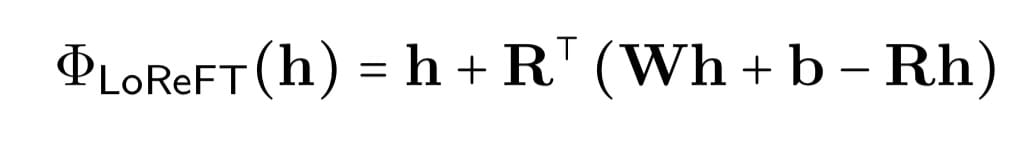
There is a nice diagram of this mathematical formula above.
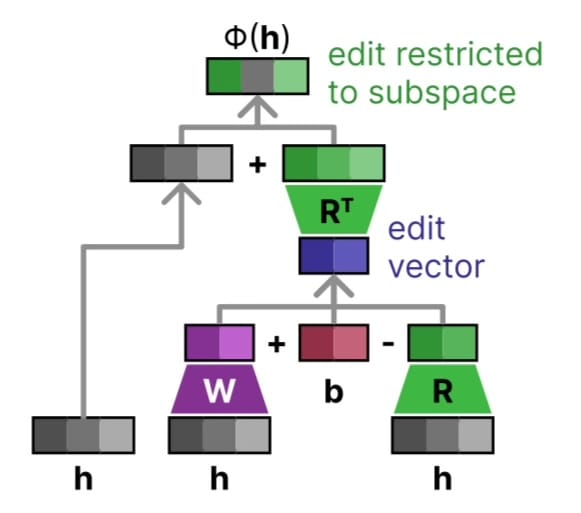
During training the task is still language modeling, but we are learning the parameters R, W, & b.
The intuition is that the Large Language Model already encodes all the information we need, we just need to guide it in the right direction in order to customize it. This intervention allows us to compress the representation into a "edit vector", then use this vector to edit and steer the representation in a certain direction. The way we steer is learned from the fine-tuning dataset.
One constraint they have in LoReFT is that the R matrix is a low-rank matrix with orthonormal rows, that collapses the hidden space down to a smaller space. They also have a version called DiReFT which removes the orthonormal constraint and reduces the training time. They say that the orthogonal constraints to the weights increase performance.
I would recommend watching the YouTube conversation for the in depth conversation and practical tips Zen provides for these orthonormal constraints. The paper also mentions a paper called "Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization" in the references for more info.
Experiments
There are a few hyper parameters to choose from here when thinking about the ReFT framework.
- Which token positions to apply the interventions to
- Which layers to intervene on
They decide to intervene on a certain number of prefix tokens and suffix tokens to fix the amount of additional compute. There is nice discussion of this in the video as well. ~TLDR intervening on the first tokens "primes" the network to be in the task specific state, and applying them at the end of the prompt also reminds the network of the task. They leave out of the middle tokens to save compute and the functionality of the existing network.
They have some nice hyper parameters search spaces documented in the appendix, as well as some suggestions in choosing them.

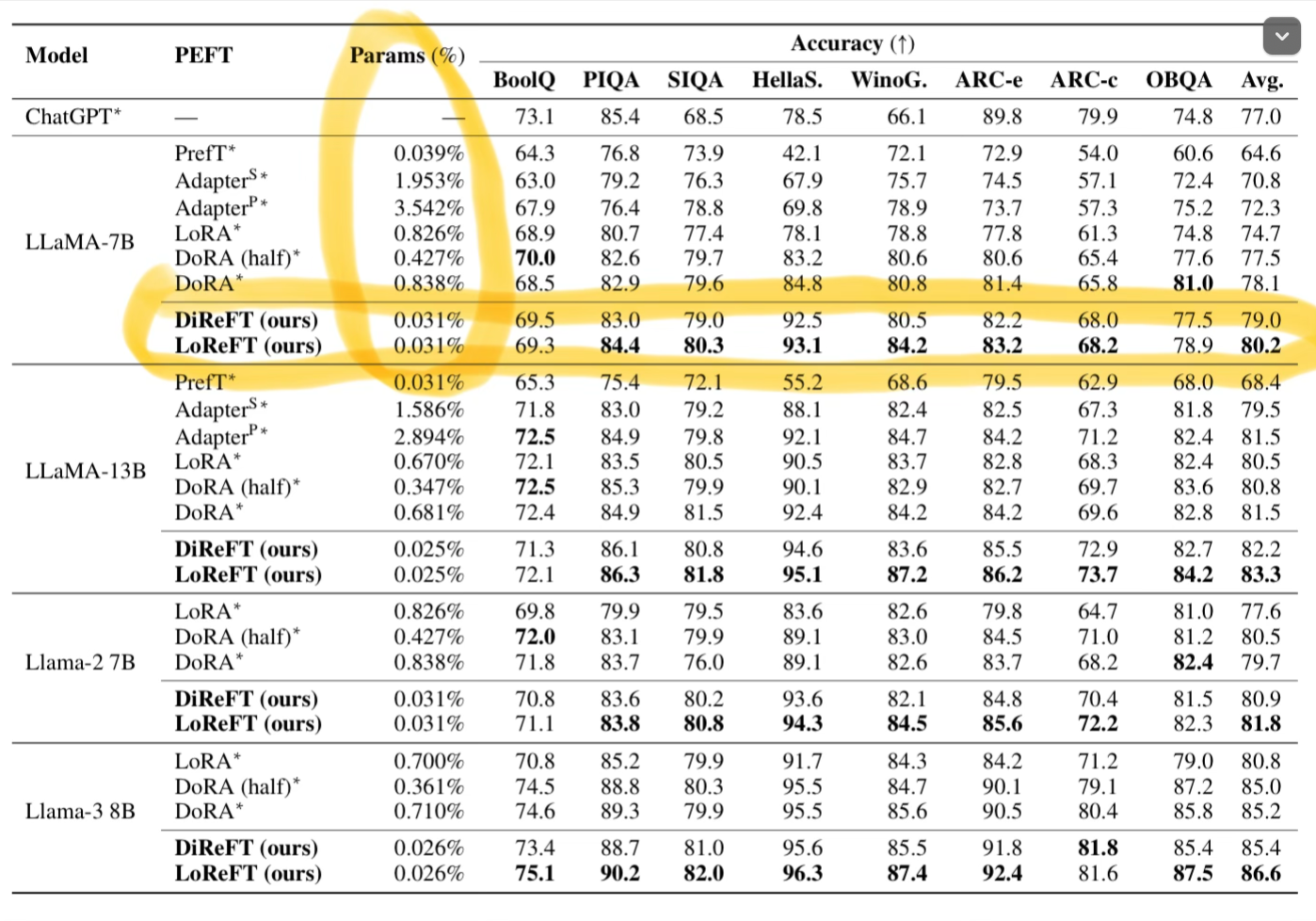
They fine tune LLama2 and Llama3 with LoReFT and look at results on 8 datasets. Notice the number of % of parameters used vs the accuracy.
Empirical Explorations
The appendix has some fun experimental and anecdotal evidence of the power of ReFT as well. I would highly recommend going through the appendix of this paper.



Conclusion
It was amazing being able to chat with Zen about his work and have the community ask questions live. What I find fascinating about this work is the overlap between interpretability and fine-tuning. This is the focus of Zen's lab going forward.
Trying out this technique on my own data, I can confirm it is extremely fast to train, but would like to do more studies into how well it encodes information as well as steers the model vs a LoRA on real world data. Look out for more tutorials diving into practical real worlds examples next.
Join the Oxen.ai Community
If you enjoy these dives feel free to subscribe to our YouTube Channel or join our Discord Community for more to come.
Building AI? Create an account on Oxen.ai to help manager the datasets that power your models. Oxen.ai is a fast, easy to use data management tool that comes with built in version control and exploratory data analysis tools.