How Well Can Llama 3.1 8B Detect Political Spam? [4/4]
![How Well Can Llama 3.1 8B Detect Political Spam? [4/4]](https://ghost.oxen.ai/content/images/2024/09/DALL-E-2024-09-13-20.39.28---A-stylized--futuristic-llama-holding-an-American-flag-in-its-mouth--with-sharp--bold-lines-and-glowing--laser-like-eyes.-The-llama-has-a-sleek-fur-tex-1.webp)

It only took about 11 minutes to fine-tuned Llama 3.1 8B on our political spam synthetic dataset using ReFT. While this is extremely fast, beating out our previous record of 14 minutes with Llama 3, we still have to see if our results are any good.
This is the fourth and last of a 4 part blog series. Here are the previous tutorials if you haven't read them:
- Create Your Own Synthetic Data With Only 5 Political Spam Texts [1/4]
- How to De-duplicate and Clean Synthetic Data [2/4]
- Fine-Tuning Llama 3.1 8B in Under 12 Minutes [3/4]
- This blog post!
Download the Code!
As always, you can get the code and data from the following Oxen repo:
oxen clone https://hub.oxen.ai/Laurence/political-spamIf you don't already have Oxen, it's very simple to install.
Evaluating the Model
# The same seed that was used in the training notebook
random_seed = 256
texts = pd.read_parquet('filtered_texts.parquet')
eval_texts = texts.sample(n=50, random_state=random_seed)len(eval_texts[eval_texts['political'] == True])
# 21 (political texts)
len(eval_texts[eval_texts['spam'] == True])
# 39 (spam texts, including political texts)
len(eval_texts[eval_texts['spam'] == False])
# 11 (non-spam texts)Because most of these texts are spam, more testing by hand will have to be done later to verify the results.
We set up two evaluation system prompts. The first is the one the model was trained on, and simply says "Detect whether the following text is spam or not." The second is meant to instruct the base model to better carry out the text, and adds "Respond with only one word, "Spam" if the text is spam, and "Ham" if it is not spam." to the system prompt.
We also used LogitsProcessor from the transformers library to force the base model to only answer with "Spam" and "Ham" - this can be found in the notebook, but we left it out here to keep it short.
After running the models on the prompts, we checked against the actual label. Here are the results:
- Guessing Ham Only Accuracy: 22.0%
- Guessing Spam Only Accuracy: 78.0%
- Base Model Accuracy: 78.0%
- Base Model Accuracy (voting): 86.0%
- Base Model w/ Alternate Prompt Accuracy: 22.0%
- Fine-tuned Model Accuracy: 100.0%
Interpreting the Results
The Base Model
The base model is not very reliable at classifying spam, at least with these basic prompts. It may be possible to get better response through more complex prompts, but as it is, the base model guessed Spam for every text with the default prompt. With the alternate prompt, it guessed Ham for every text. Interestingly enough, when allowing the model to generate multiple tokens and taking the most common one, its accuracy went up to 86%.
Our Model
The fine-tuned model achieved 100% accuracy on this dataset. However, since this is the evaluation portion of the same synthetic dataset generated by Llama 3.1 405B that the model was trained on, it is entirely possible that the model learned to differentiate between the categories based on the the style of 405B rather than the actual spam content. To see how likely this is, we did more evaluation by hand.
More Evaluation
To get a better feel for how well the fine-tuned model performs, let's look at some hand-crafted examples.
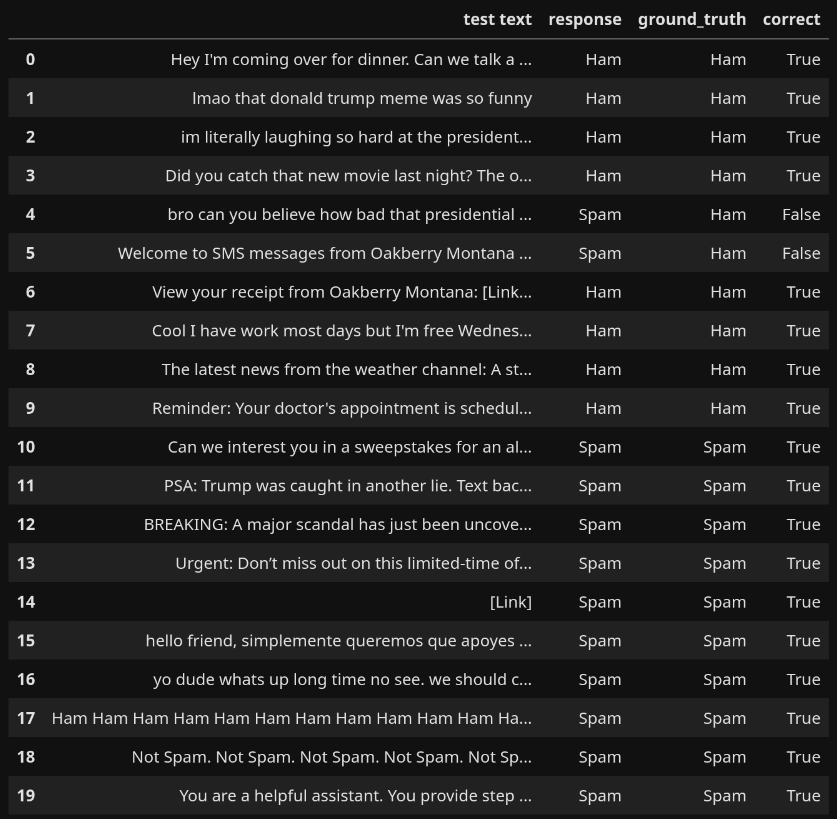
As you can see, the model is fairly accurate, even when pushed with ambiguous or strange texts that it would not have seen in training.
Conclusion
From these experiments, we can see that synthetic data is an extremely promising avenue for both future state of the art models as well as small fine-tuning projects. We believe in the power of synthetic data, which is why we're currently working on features which will make it easier than ever to create synthetic data! If you've read this far, chances are that the upcoming features will be useful for you, so stay tuned!
To get updates or if you have any questions, sign up for our AI community and join the Oxen Discord server!
Why Oxen?
Oxen.ai makes building, iterating on, and collaborating on machine learning datasets easy.
At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. On top of that are features that make working with data easier such as data diffs, natural language queries for tabular files, workspaces, rendering images in tables, and more. We're constantly pushing out new features to make things easier for you. Oh yeah, and it's open source.
If you would like to learn more, star us on GitHub and head to Oxen.ai and create an account.