The Prompt Report Part 2: Plan and Solve, Tree of Thought, and Decomposition Prompting

In the last blog, we went over prompting techniques 1-3 of The Prompt Report. This arXiv Dive, we were lucky to have the authors of the paper join us to go through some of the more advanced techniques. To watch the whole conversation and see the authors answers to our questions, dive into the video below.
First off, The Prompt Report is an excellent survey of the prompting landscape and I have been going down rabbit hole after rabbit hole. To be honest, I come from a traditional machine-learning background, so had been dismissing prompting a bit. This paper changed my mind. It is fascinating and definitely deserves to be a field of study on its own.
Second off, I just want to shout out to the Oxen.ai team. All the work I am about to show today couldn’t have been done without them. We are rolling out the ability to run arbitrary models on datasets for evaluation, synthetic data and labeling use cases.
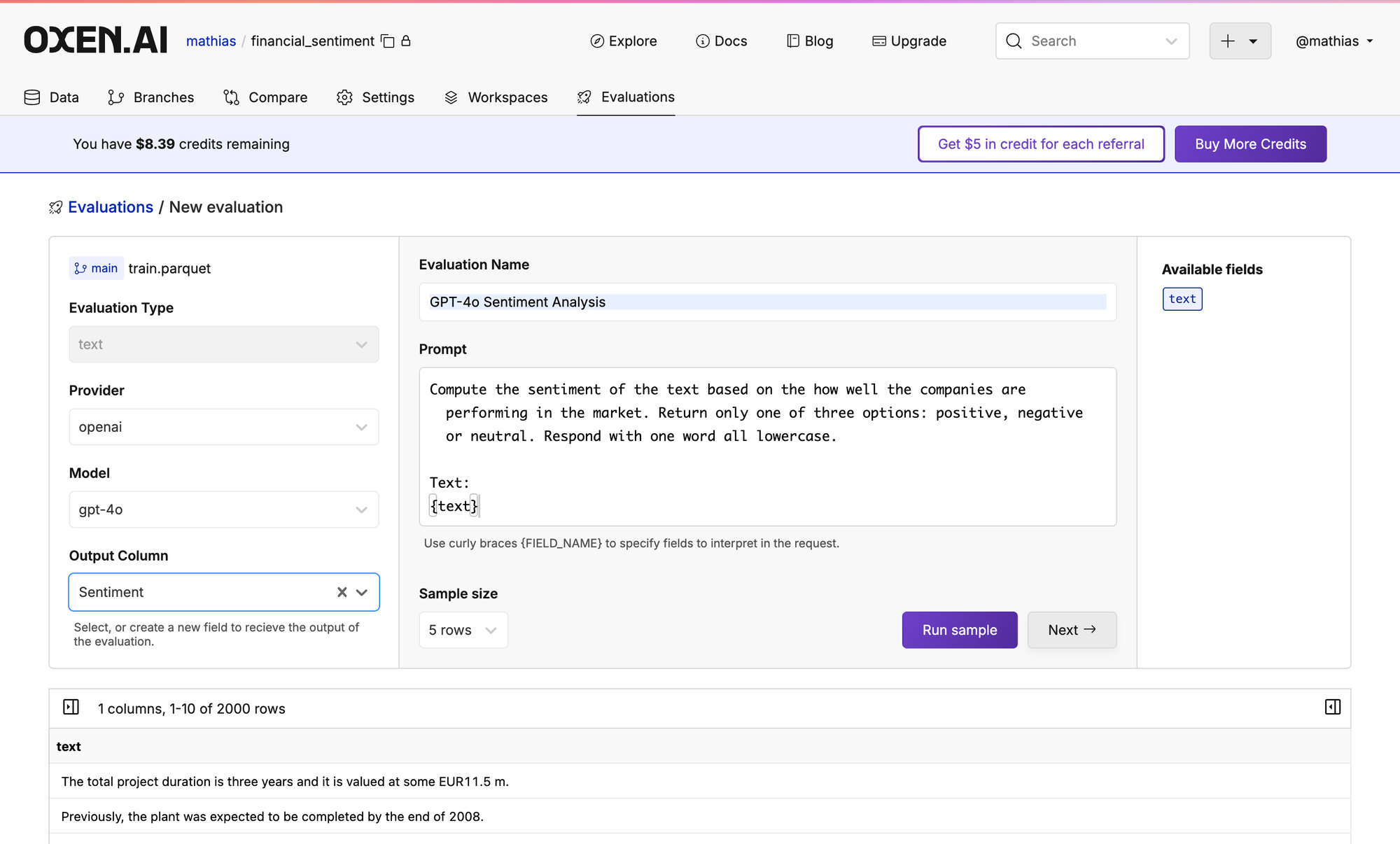
The tool that you’ll see today really helps with this part of the paper. You’ll see how easy it is to use as we go through some examples and it’s free to try, we give $10 of free compute credits, so hammer it, let us know what you think, and let us know what creative prompt and problems you solve with it in our discord.
Last week we covered the first half of the taxonomy that is laid out in the paper.
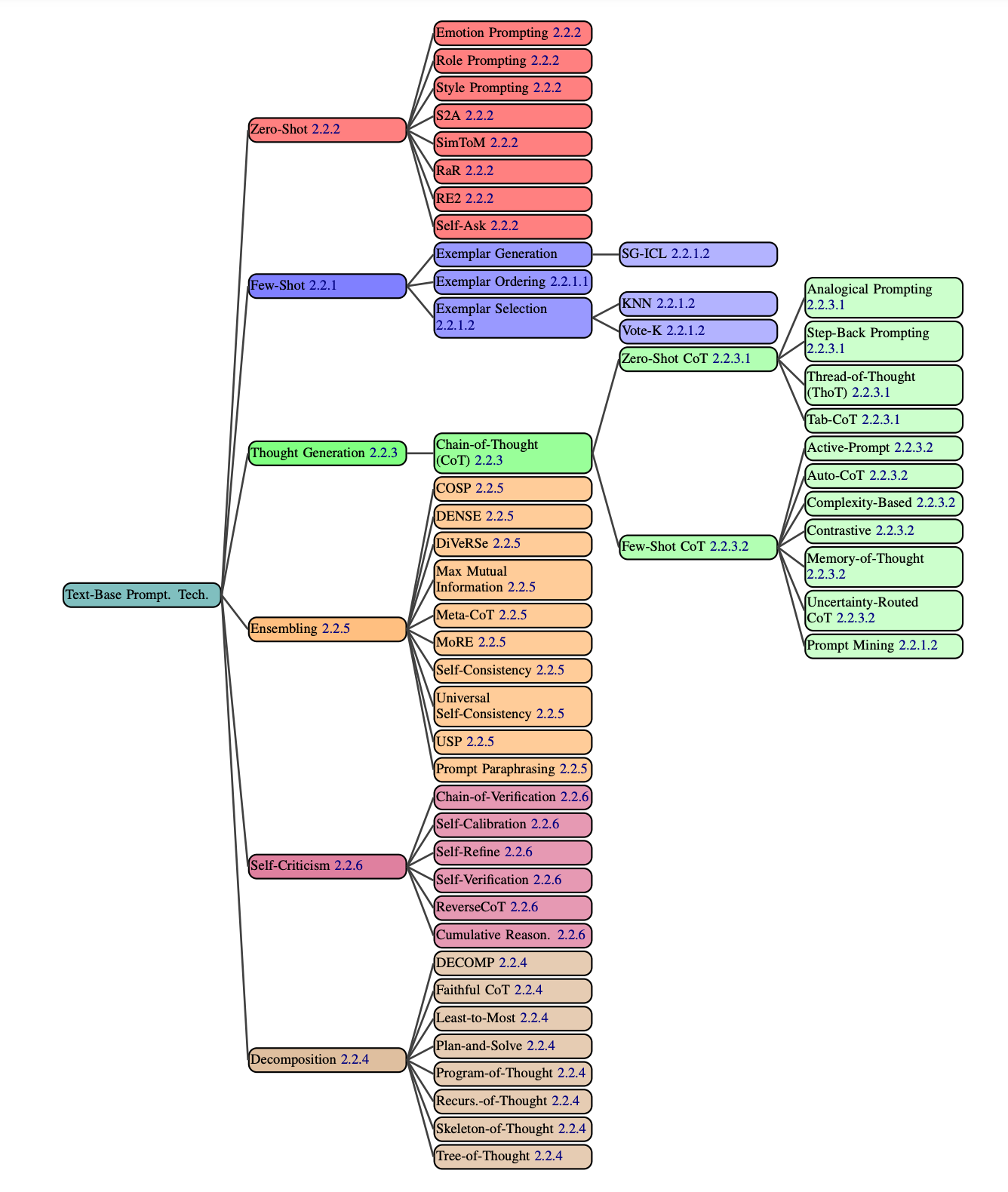
Each one of these nodes is a paper in itself, so they will be like mini arXiv Dive snacks that we can work through. This paper is great in the way it builds up from simple prompting techniques to more complex ones. The ones we are going to go over today are a gold mine for synthetic data and testing the ability of LLMs to reason.
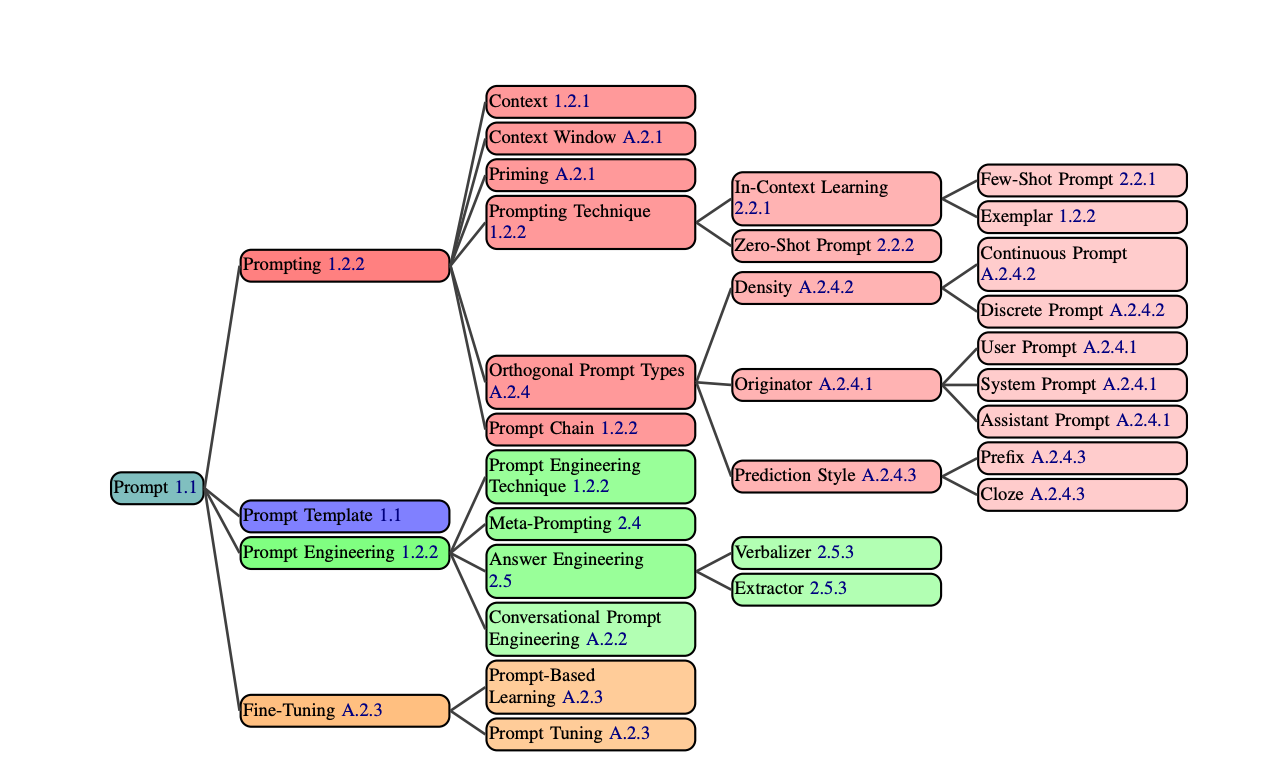
Within the 58 categories, there are 6 top-level categories.
- ✅ Zero-Shot
- ✅ Few-Shot
- ✅ Thought Generation
- Decomposition
- Ensembling
- Self-Criticism
As I said, the methods today will be a synthetic data generation gold mine ⚱️👑. If we can prompt these models to reason, judge their own reasoning, and then filter down the responses to correct answers, then we can use this data for training the next iteration of models.
This is most likely what OpenAI is doing with O1, and they are “hiding” the reasoning tokens from us so that we cannot just use it as training data for our own models. One of the core tenets of arXiv Dives is “Anyone can build it”. Especially with open-source models like Llama coming out, you can use some of the larger models + these prompting techniques to get high quality synthetic data and train your own variants.
I went through and tried to find some concrete examples from each sub paper so that we can try and discuss.
Thought Generation
Last week we left off with some “Thought Generation” examples such as “Chain of Thought” reasoning. You’ll see this abbreviated as CoT in a lot of the following papers because they often reference this technique as a baseline to compare against.
Even if you look at the outputs for gpt-4o it is clear that the model has been trained to “think step by step.” One of the sub papers mentioned a dataset called “SCAN” that has a bunch of directional reasoning problems.
Given a set of instructions as follows:
walk opposite right thrice after run opposite right
So I prompted the LLM to take the instructions and predict which direction the person is facing.

The tokens it generated included “Chain of Thought” reasoning that the model was clearly trained to output.

Today, you’ll see how we can use models to generate data like this, and then let your imagination run wild for how you could use these types of prompts in real world applications or for synthetic data to train reasoning capabilities into smaller models.
Decomposition
A common way that humans solve complex problems is by decomposing them into simpler sub-problems.
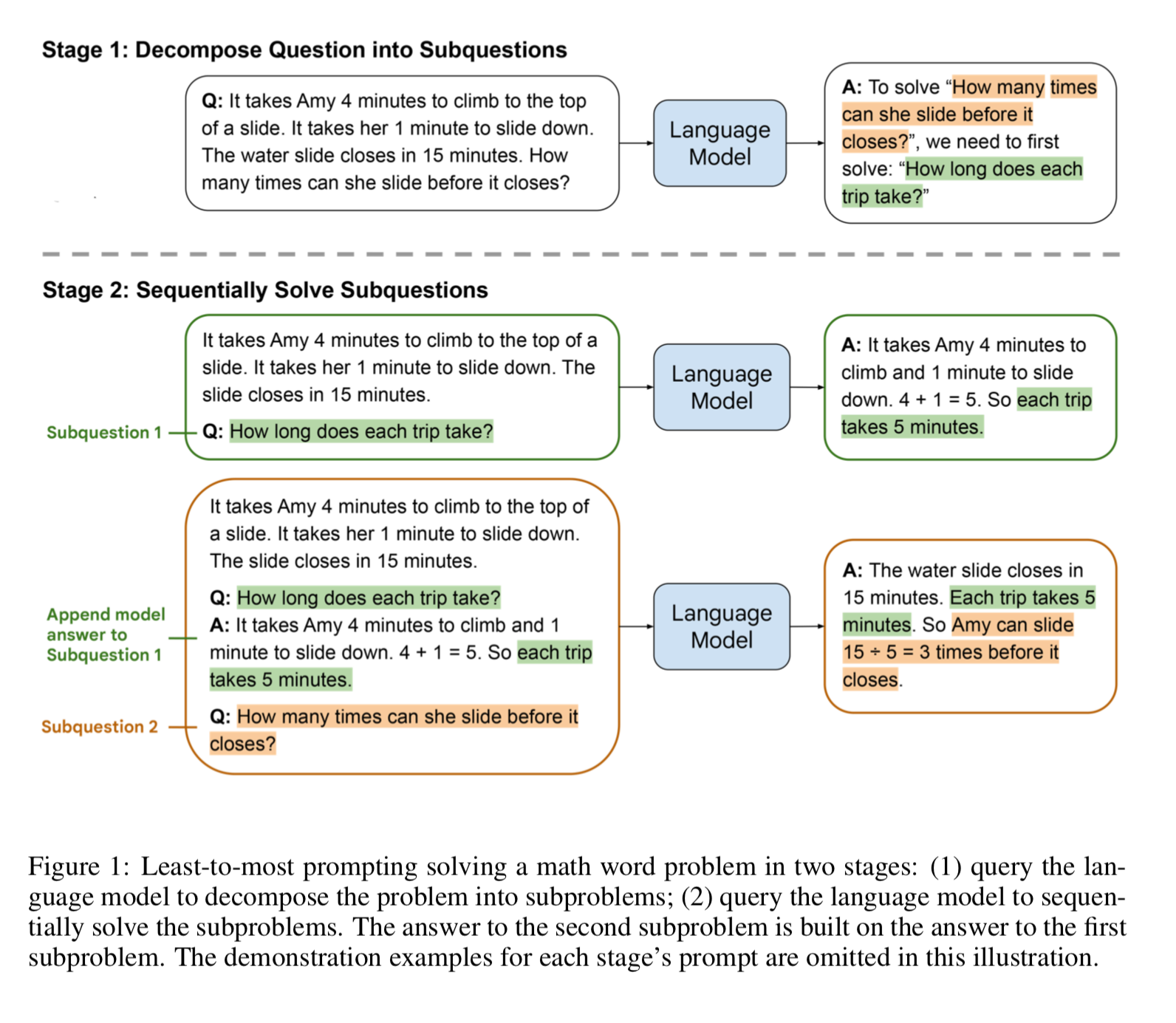
Least-to-Most Prompting
This technique first has the model generate sub questions, based on the user input. Then answers the sub question one by one.
SCAN Dataset:
https://github.com/brendenlake/SCAN

There are some example prompts at the end of the paper.

Here is the full one I grabbed from the paper:
Here are some results we can look at:
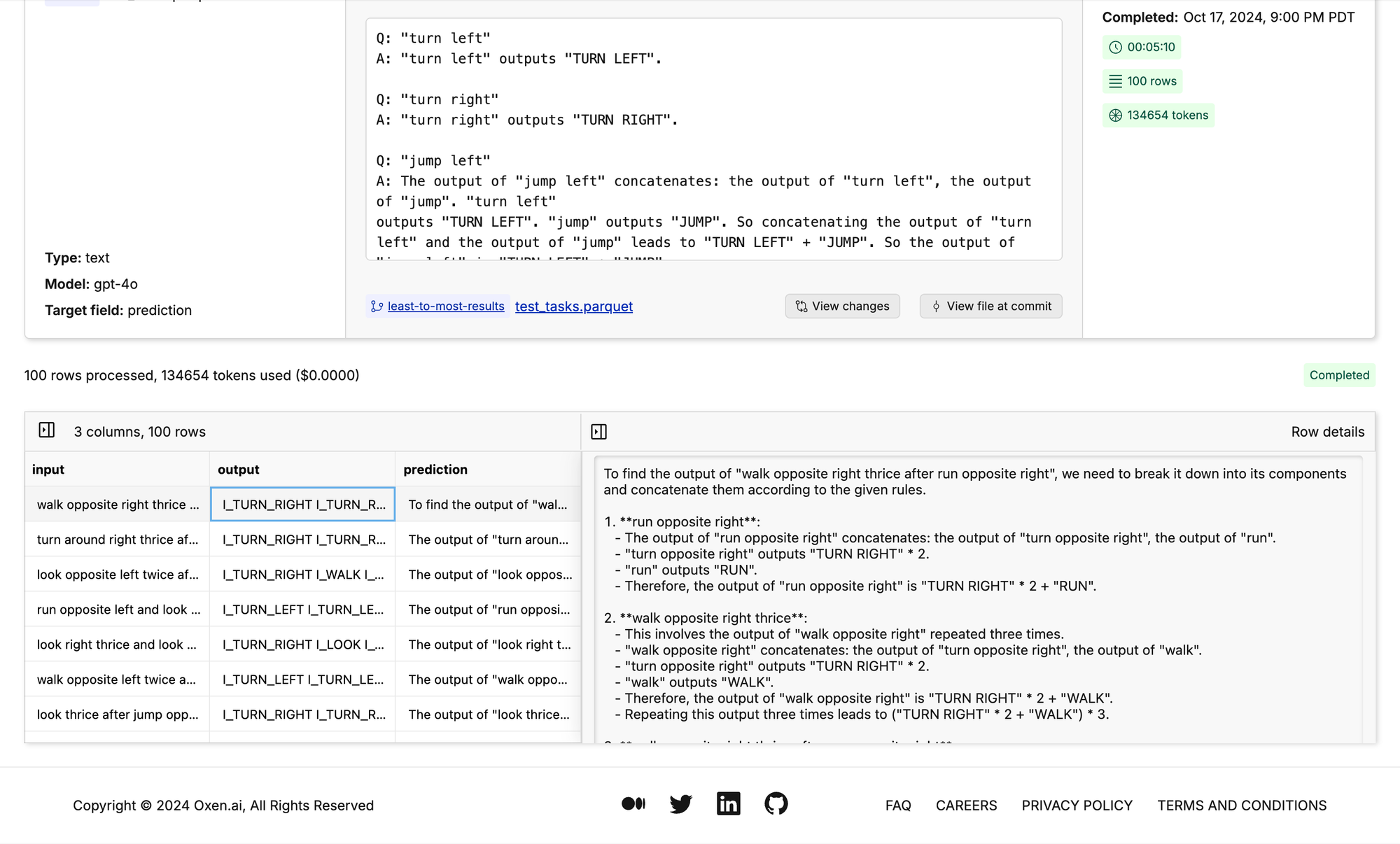
Decomposed Prompting w/Tools
You may need external tools to solve certain problems. In order to get the LLM to use the tools you may want to give few-shot examples of when do use certain tools. Then use multiple LLM calls to call different functions and combine the responses.
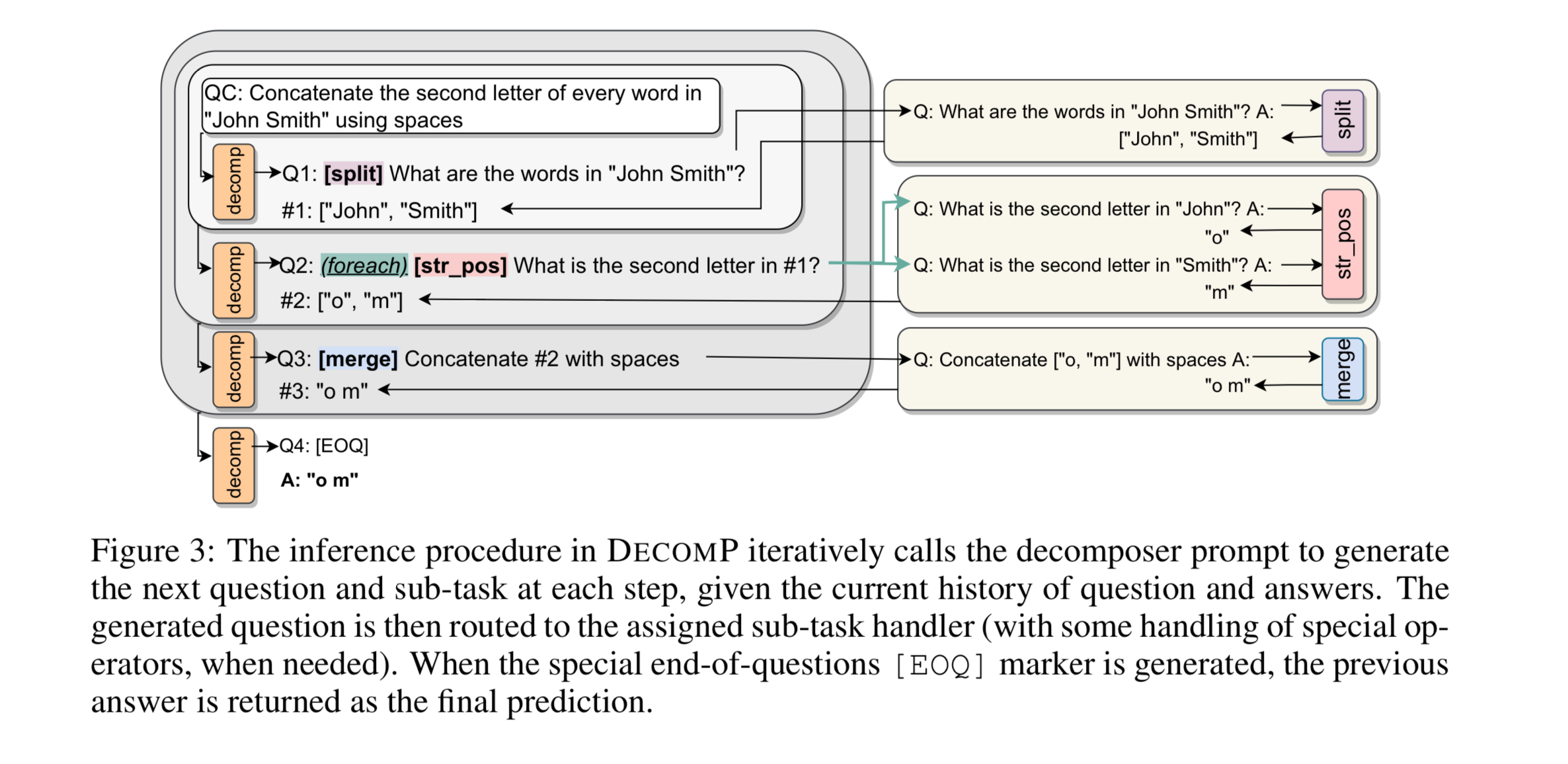

The decomposition steps can even be tools that you want to call

Example Prompt:
Example Results:
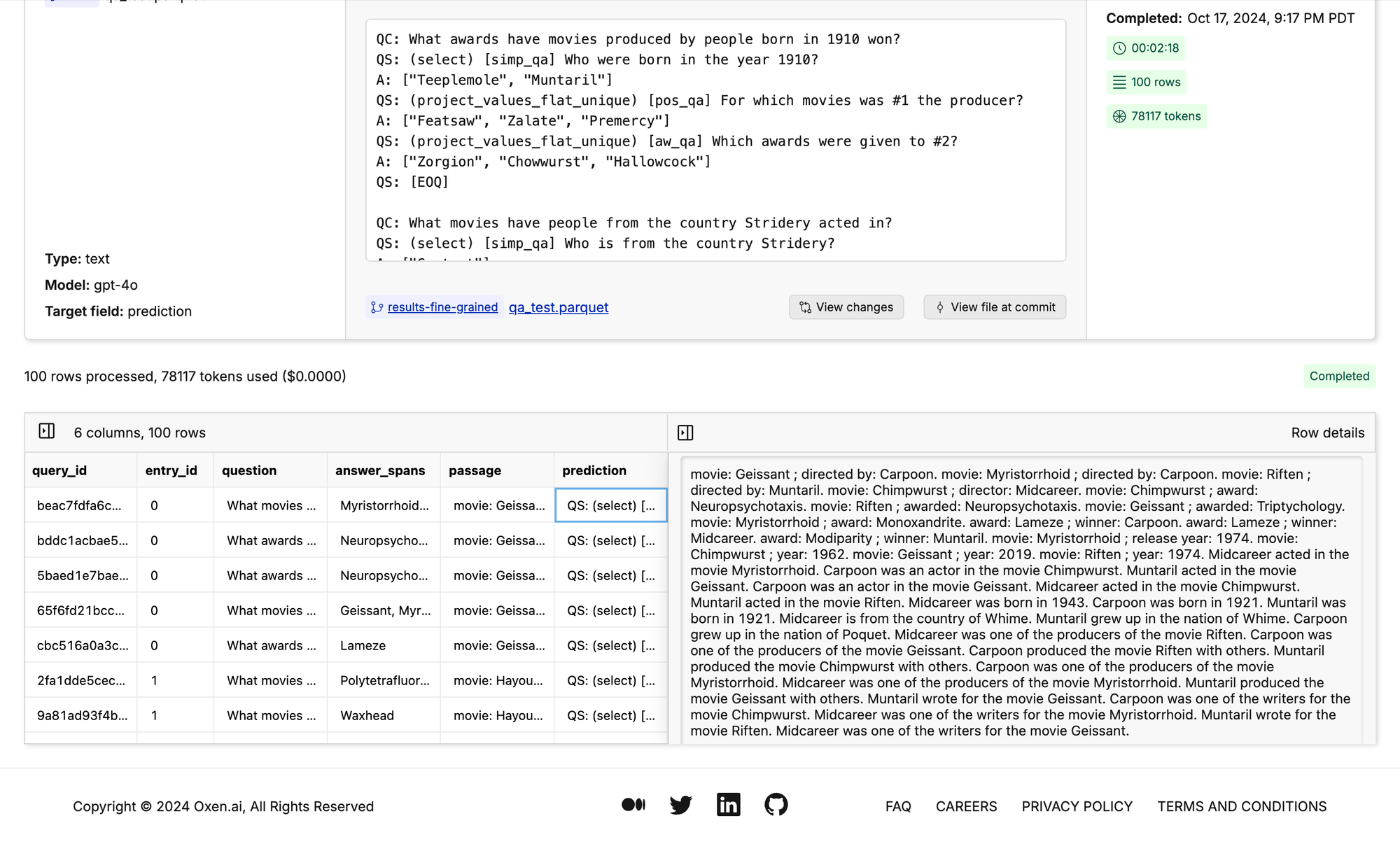
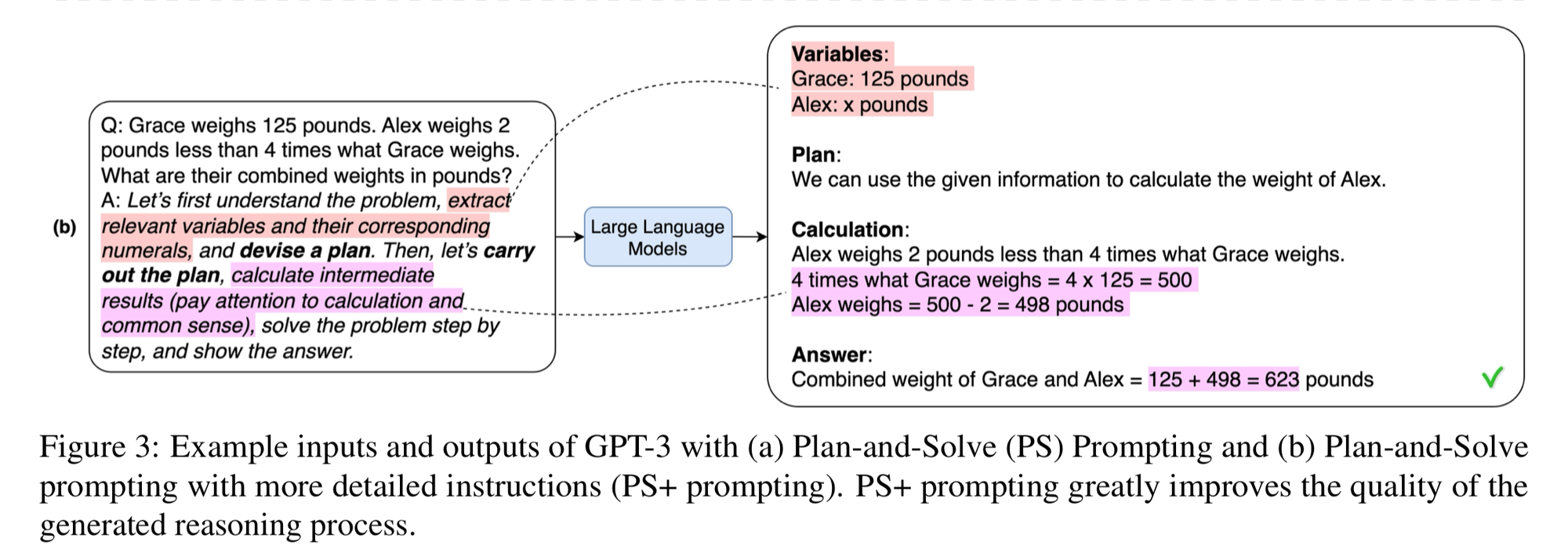
Plan-and-Solve Prompting
This technique asks the LLM to “create a plan” before solving. This is a little more descriptive than your generic chain of thought prompting.

“Let’s first understand the problem and devise a plan to solve it. Then carry out the plan and solve the problem step by step.”
You can give the model additional instructions like “extract the relevant variables”
Last week we looked at GSM8k and realized that these models are pretty overfit to this dataset. Almost every prompt we tried we were getting 95+% accuracy. Right after we looked at some of the examples Apple came out with a spicy paper, that seemed to agree.
I saw that gretle.ai generated a dataset with some similar techniques, so I grabbed 100 rows to do some vibe checks.
Let’s try out the prompt above on some data:
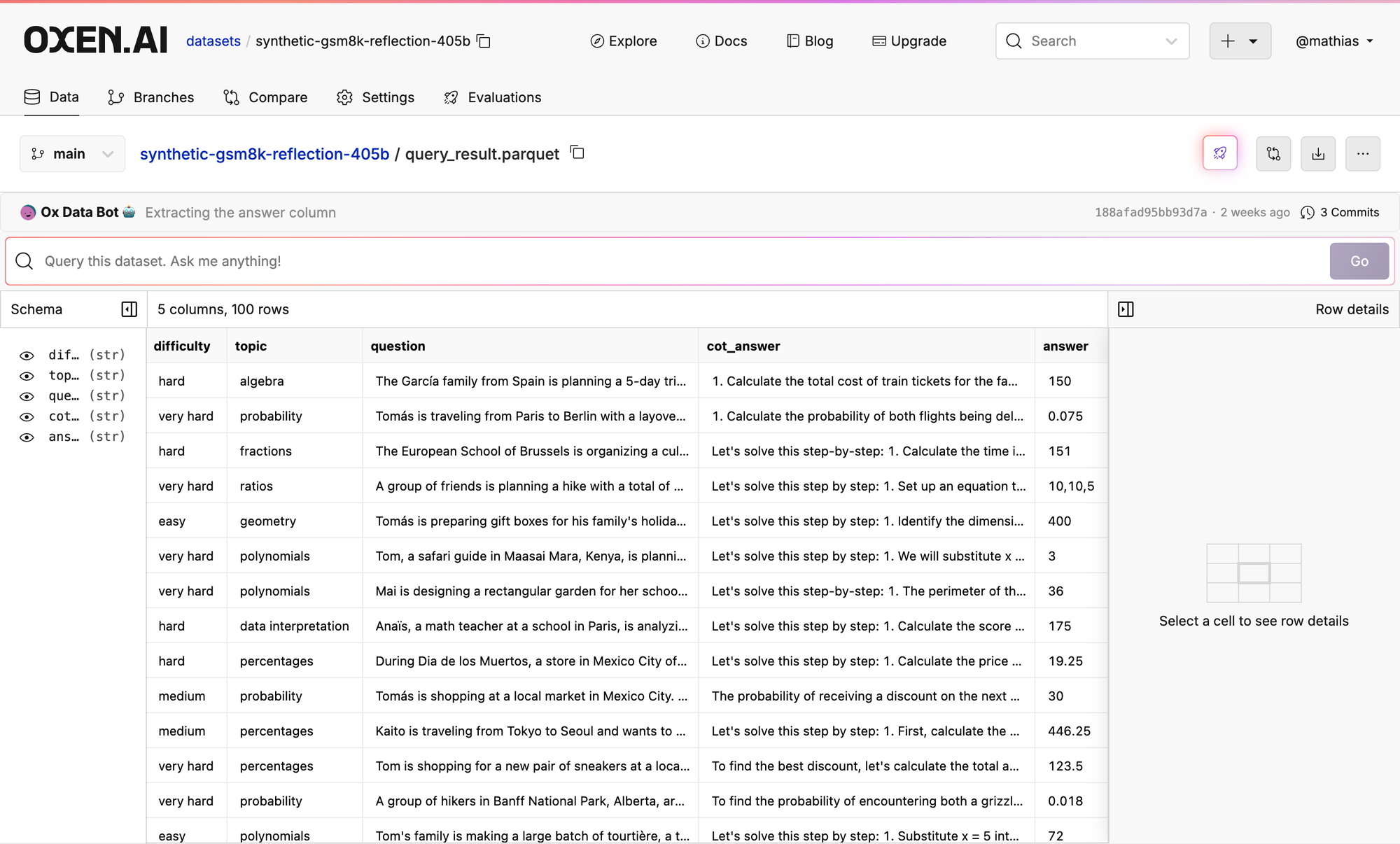
The first prompt we tried got 75% accuracy on the 100 examples
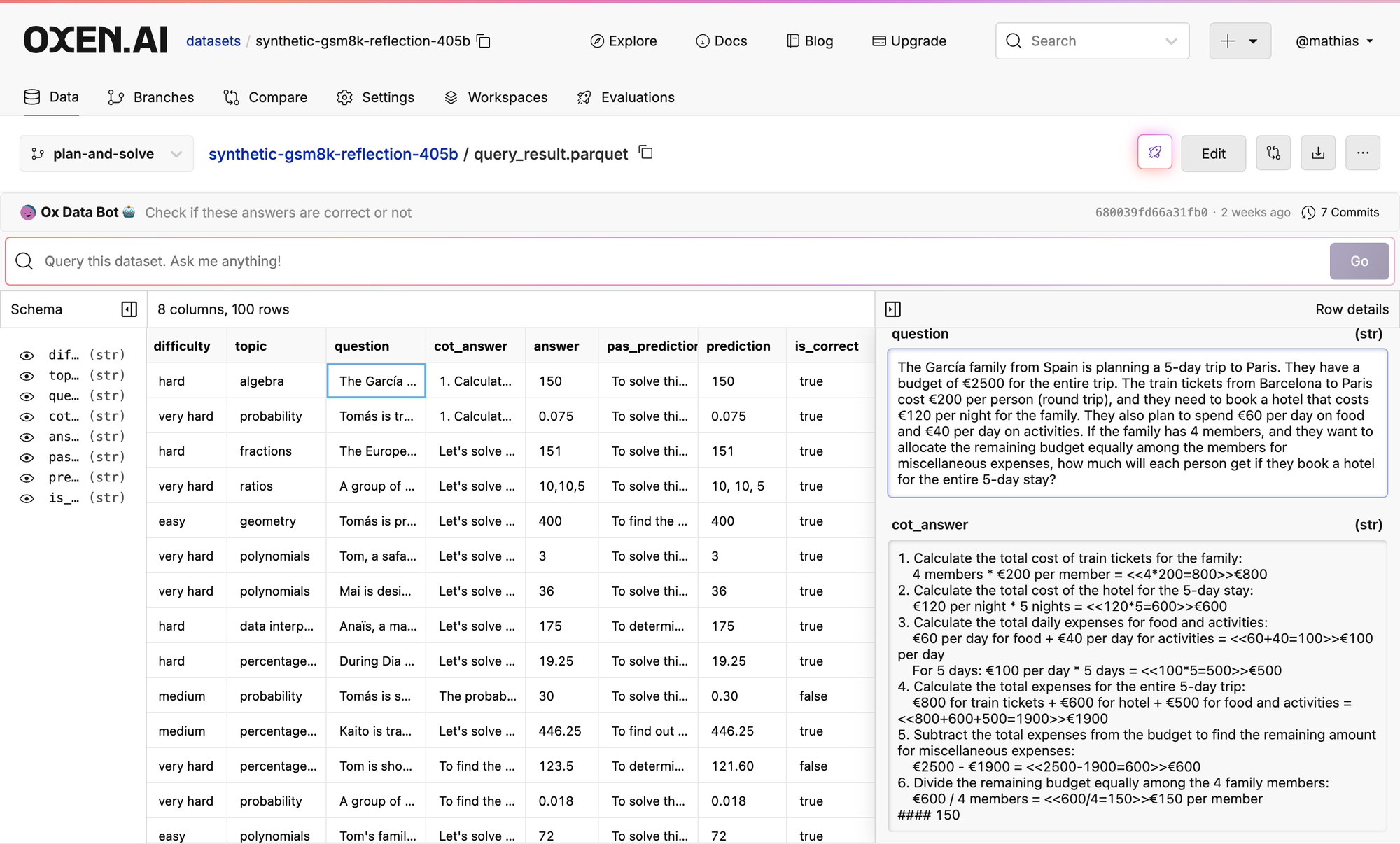
The second was 76% accuracy on the same 100 examples 🤷♂️
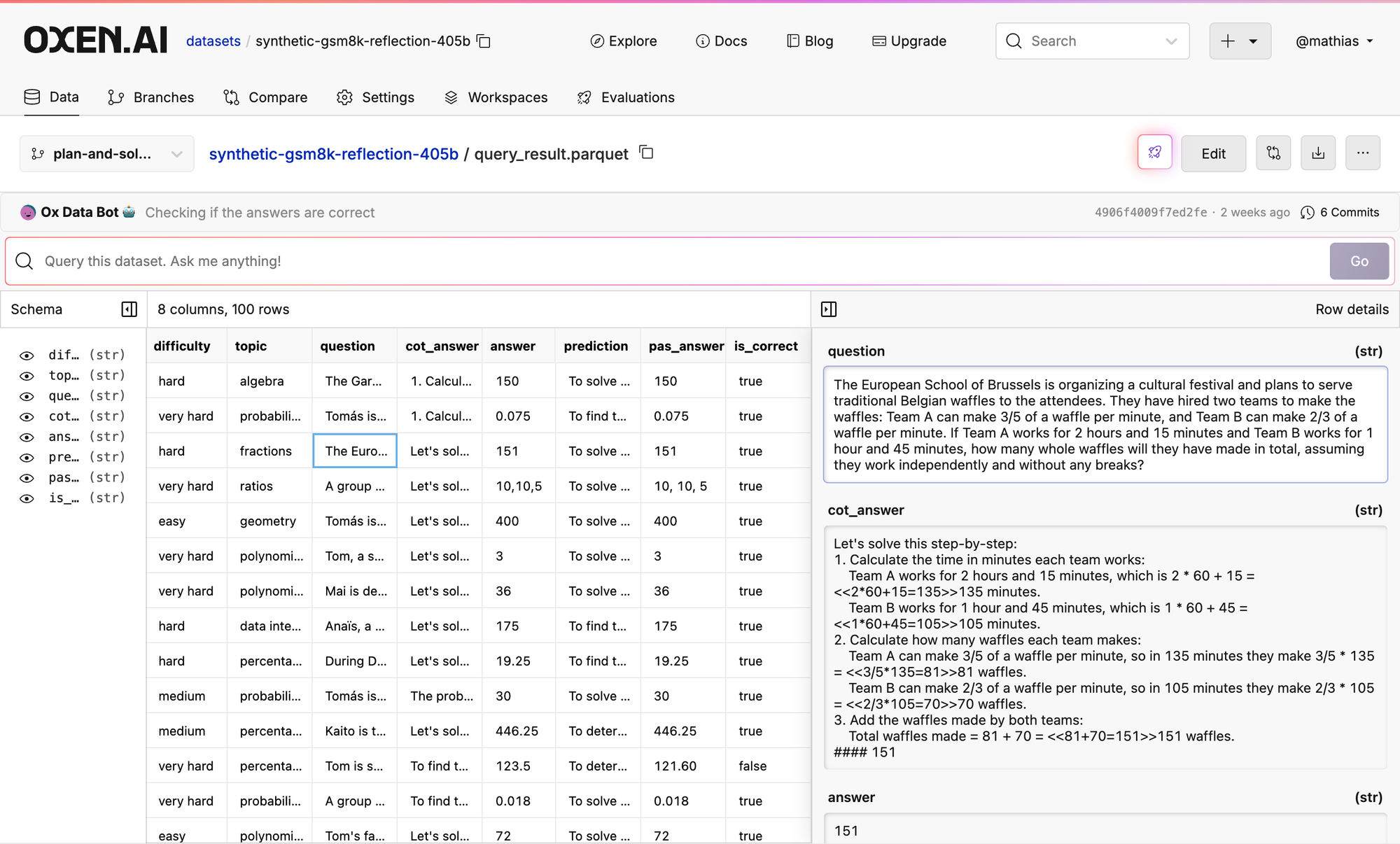
It is starting to become pretty fun to run these experiments in Oxen.ai, I would highly recommend you test it out.
Tree-of-Thought
This was probably one of the more impactful prompting techniques of 2023. This paper argues that you can use LLMs to think more like System Two thinking in the Daniel Kahneman sense of system 1 vs system 2 thinking.
Tree-of-thought creates multiple possible steps then uses a tree-like search to evaluate progress at each step. It then decides which steps to continue with, and keeps creating more thoughts with the happy paths.
 princeton-nlp
princeton-nlpStill use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
— Shunyu Yao (@ShunyuYao12) May 19, 2023
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.https://t.co/V6hjbUNjbt pic.twitter.com/IaZZdVeaTW
There are tasks that are hard to solve with straight chain of thought prompting.
Why? LLMs predict the next token one at a time, if you make a mistake, you can’t backtrack or fix it.

Tree of Thought can solve these problems 10x better than just a simple I/O prompt.
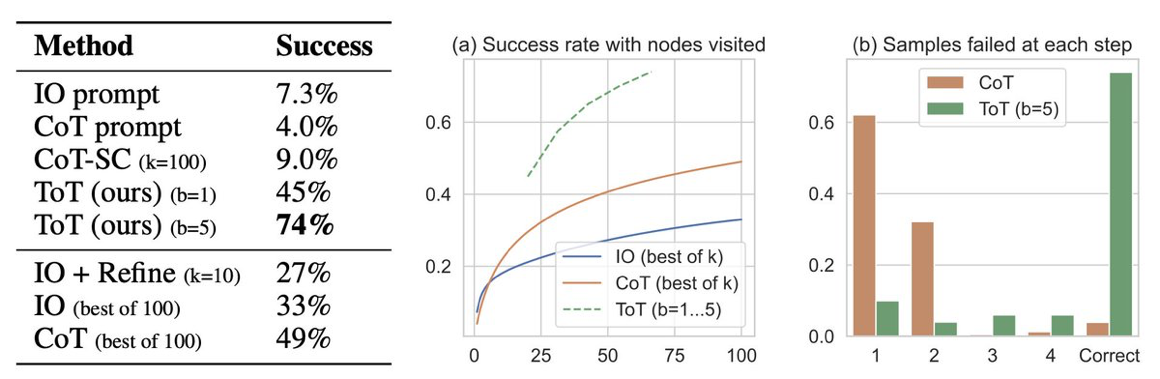
This one is going to be a little mind bending so stick with us.
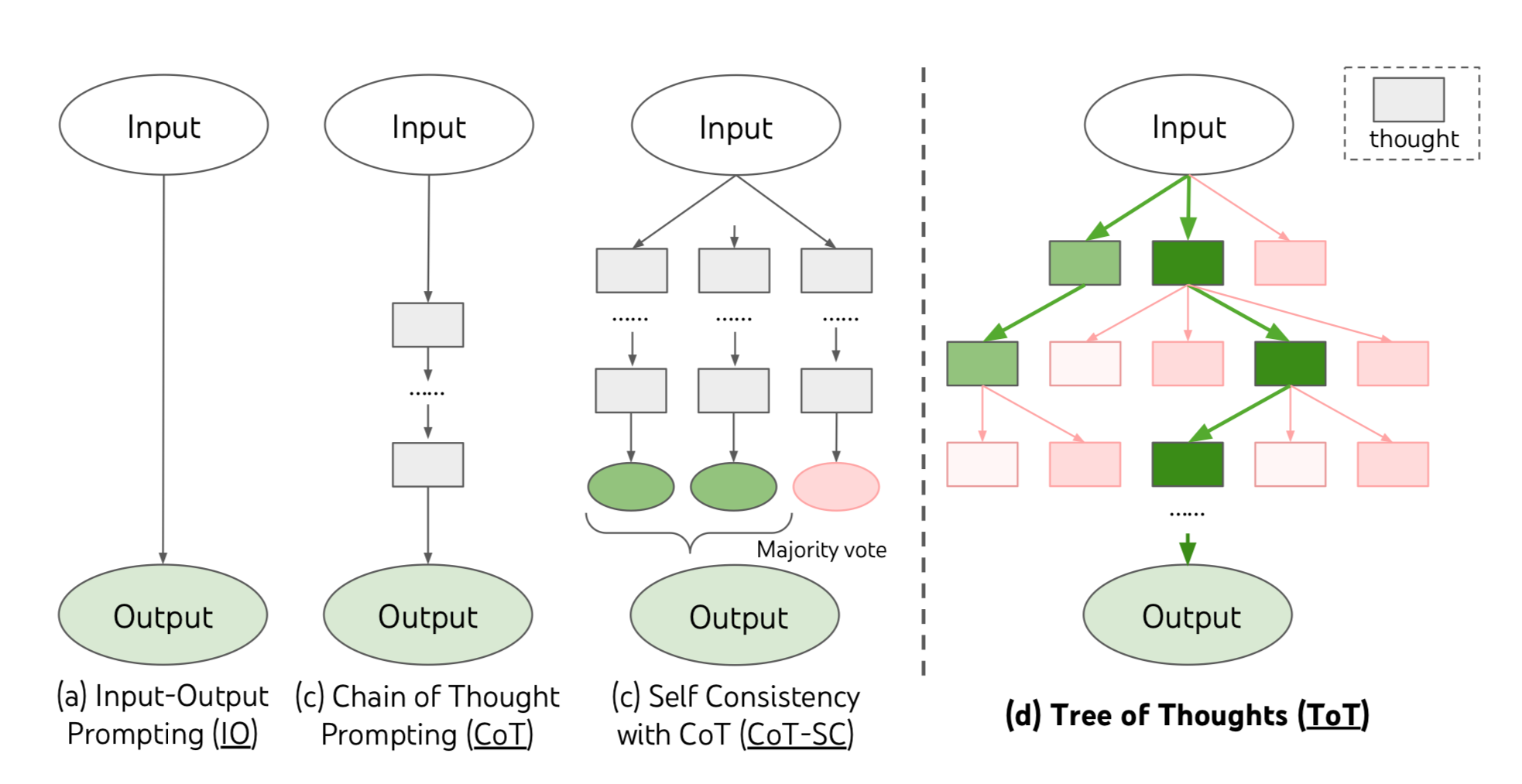
- Generate diverse “thoughts” of different ways to tackle the problem
- For each thought, evaluate if you are on the right track
- Use standard tree search like breadth first or depth first search to get to an output.
Thought Generation Prompt
Use numbers and basic arithmetic operations (+ - * /) to obtain 24.
Each step, you are only allowed to choose two of the remaining numbers
to obtain a new number.
Input: 4 4 6 8
Steps:
4 + 8 = 12 (left: 4 6 12)
6 - 4 = 2 (left: 2 12)
2 * 12 = 24 (left: 24)
Answer: (6 - 4) * (4 + 8) = 24
Input: 2 9 10 12
Steps:
12 * 2 = 24 (left: 9 10 24)
10 - 9 = 1 (left: 1 24)
24 * 1 = 24 (left: 24)
Answer: (12 * 2) * (10 - 9) = 24
Input: 4 9 10 13
Steps:
13 - 10 = 3 (left: 3 4 9)
9 - 3 = 6 (left: 4 6)
4 * 6 = 24 (left: 24)
Answer: 4 * (9 - (13 - 10)) = 24
Input: 1 4 8 8
Steps:
8 / 4 = 2 (left: 1 2 8)
1 + 2 = 3 (left: 3 8)
3 * 8 = 24 (left: 24)
Answer: (1 + 8 / 4) * 8 = 24
Input: 5 5 5 9
Steps:
5 + 5 = 10 (left: 5 9 10)
10 + 5 = 15 (left: 9 15)
15 + 9 = 24 (left: 24)
Answer: ((5 + 5) + 5) + 9 = 24
Input: {input}
Steps:
Evaluator Prompt:
Evaluate if given numbers can reach 24 (sure/likely/impossible)
10 14
10 + 14 = 24
sure
11 12
11 + 12 = 23
12 - 11 = 1
11 * 12 = 132
11 / 12 = 0.91
impossible
4 4 10
4 + 4 + 10 = 8 + 10 = 18
4 * 10 - 4 = 40 - 4 = 36
(10 - 4) * 4 = 6 * 4 = 24
sure
4 9 11
9 + 11 + 4 = 20 + 4 = 24
sure
5 7 8
5 + 7 + 8 = 12 + 8 = 20
(8 - 5) * 7 = 3 * 7 = 21
I cannot obtain 24 now, but numbers are within a reasonable range
likely
5 6 6
5 + 6 + 6 = 17
(6 - 5) * 6 = 1 * 6 = 6
I cannot obtain 24 now, but numbers are within a reasonable range
likely
10 10 11
10 + 10 + 11 = 31
(11 - 10) * 10 = 10
10 10 10 are all too big
impossible
1 3 3
1 * 3 * 3 = 9
(1 + 3) * 3 = 12
1 3 3 are all too small
impossible
{input}
I tried this 5-Shot prompt last night, and that’s when I about decided it was time to go to bed…
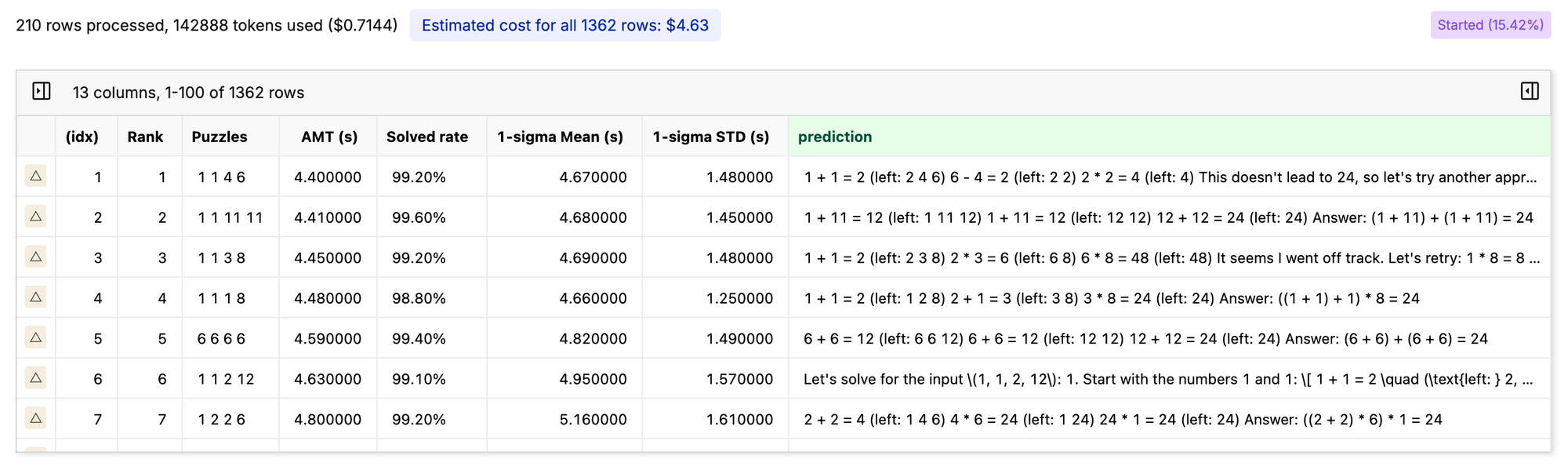
Would I say this was the most effective use of ~$5?
Yes...I had fun 😅
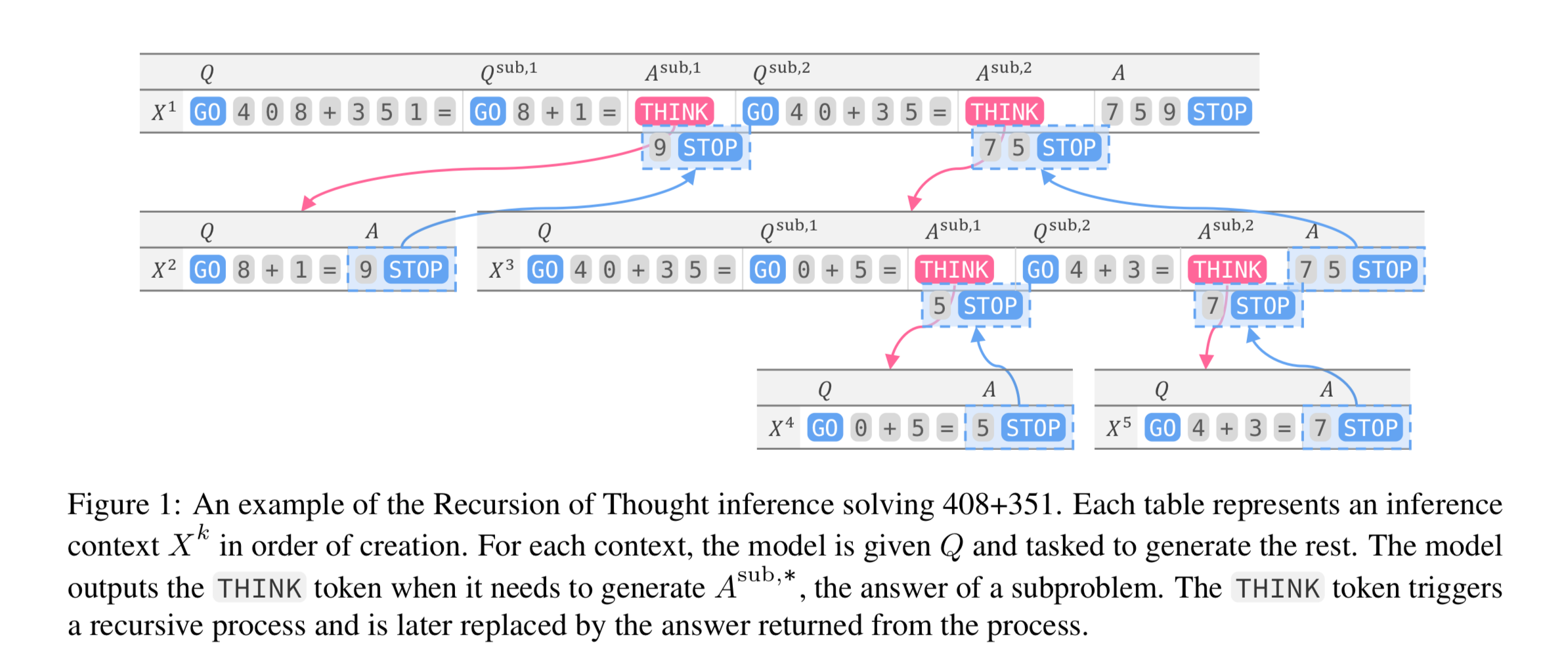
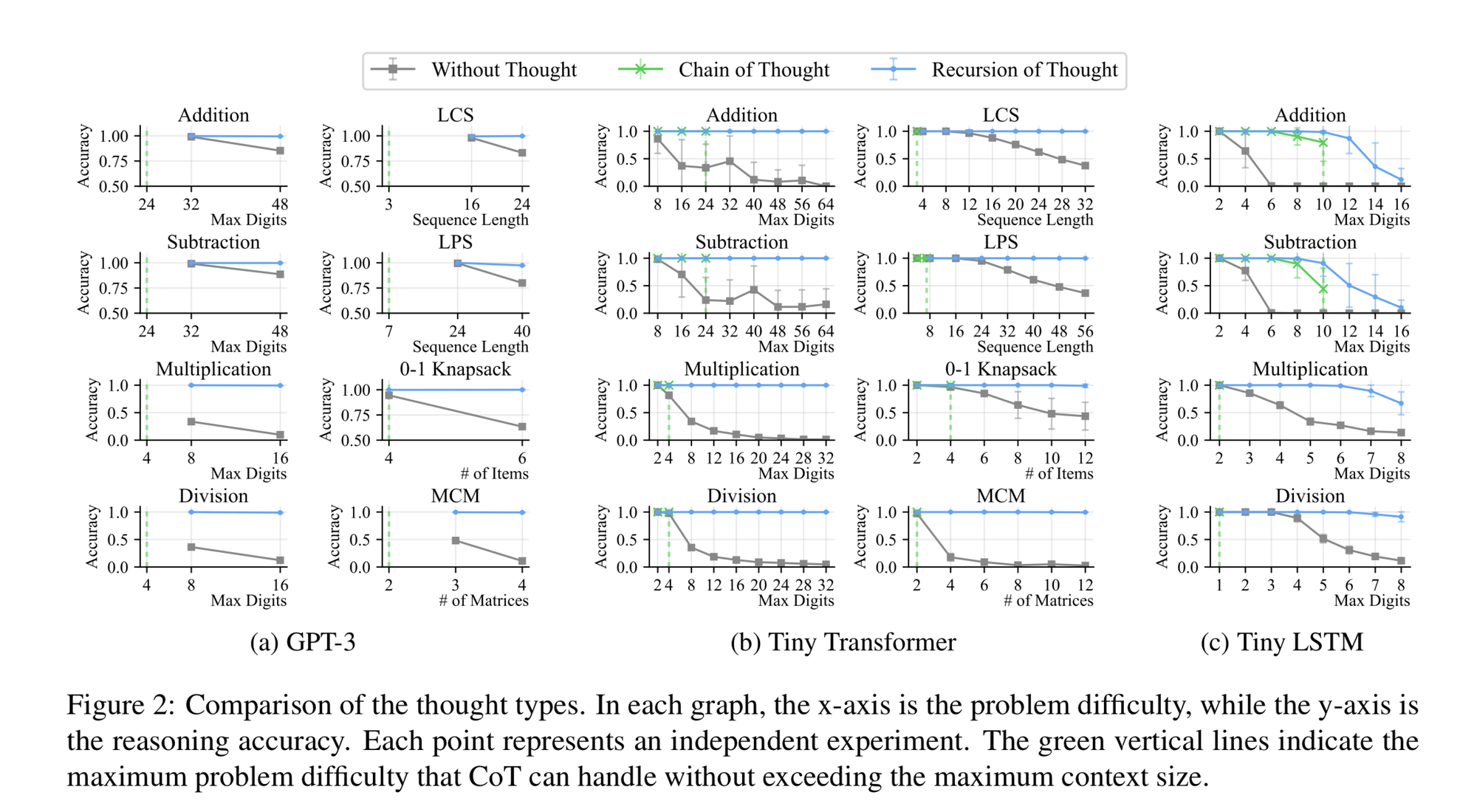
Recursion of Thought
soochan-leeThe idea here is similar to Chain of Thought, but every time you get to a “complicated problem” in the middle of the reasoning chain, it can send this problem to another prompt+LLM call.
Program of Thought (PoT)
Use an LLM that specializes in coding (this paper used Codex) and have it output the reasoning steps as programming code like python. Then execute the code to get the correct answer.

Over pure chain of thought, program of thought generates much higher accuracies
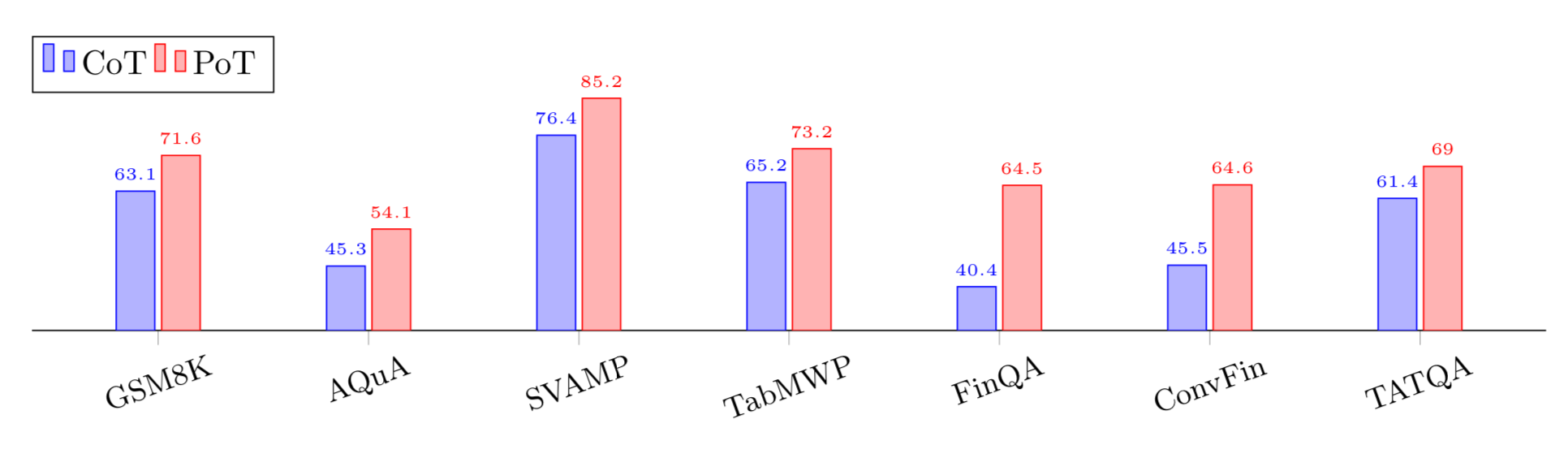
TODO: Look up FinQA, ConvFin and TATQA datasets
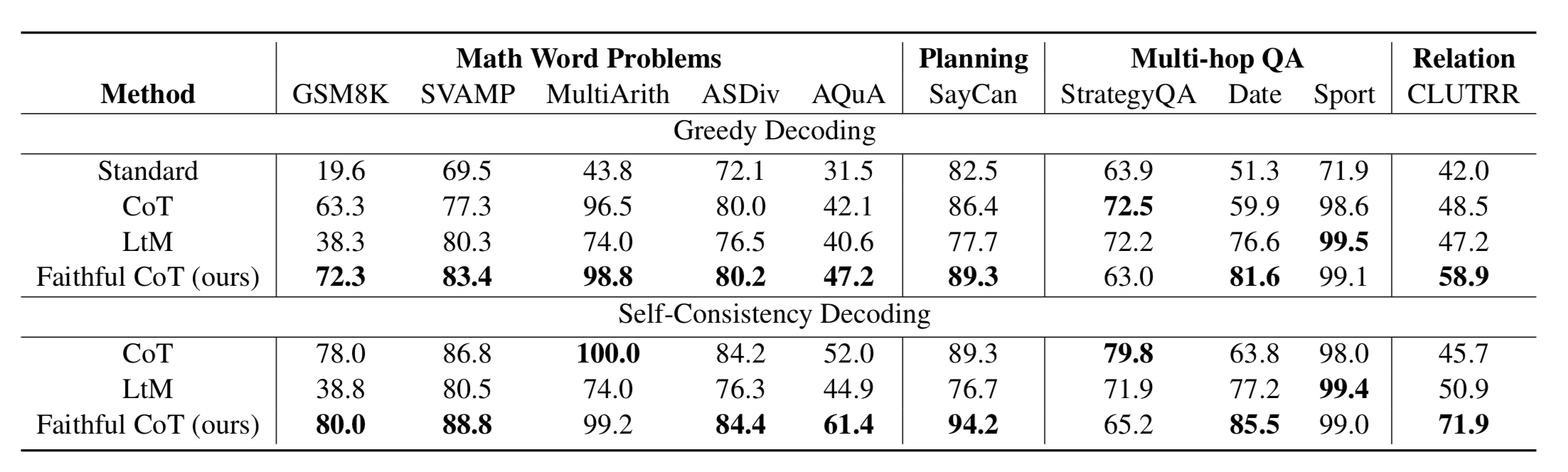
Faithful Chain-of-Thought
https://arxiv.org/pdf/2301.13379
veronica320This is like a combination of PoT and CoT that uses python + natural language reasoning, but it uses different types of “symbolic languages” like python depending on the task.
 veronica320
veronica320Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
To answer this question, write a Python program to answer the following subquestions:
-
How many trees are there in the end? (independent, support: ["there will be 21 trees"])
trees_end = 21 -
How many trees are there in the beginning? (independent, support: ["There are 15 trees"])
trees_begin = 15 -
How many trees did the grove workers plant today? (depends on 1 and 2, support: [])
trees_today = trees_end - trees_begin -
Final Answer: How many trees did the grove workers plant today? (depends on 3, support: [])
answer = trees_today
... repeat this type of reasoning
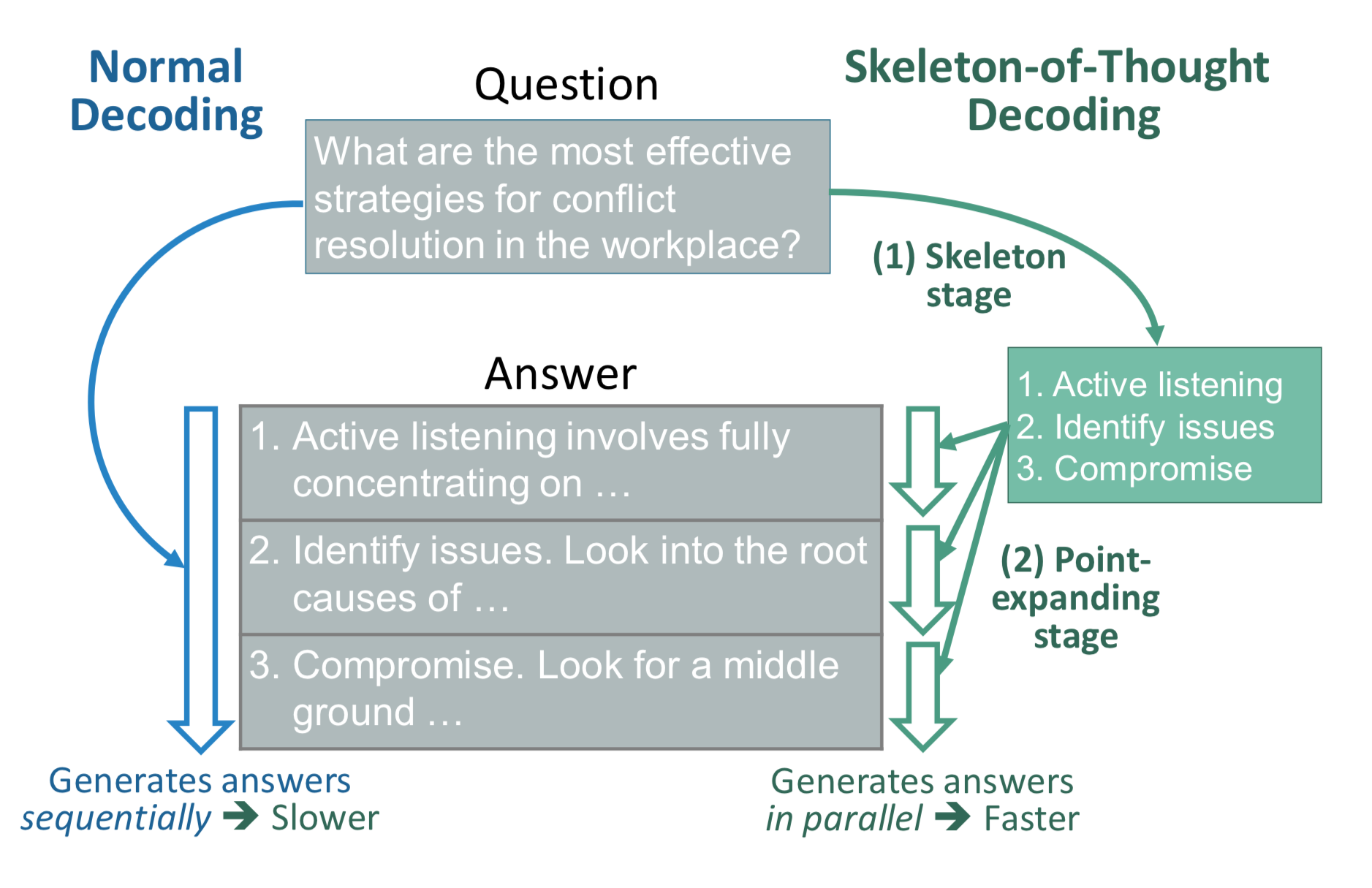
Skeleton-of-Thought
imagination-researchThis focuses on speed and parallel processing. Given a problem, create a template of sub-problems to be solved, then in parallel, go solve all the sub-problems, combined them, and get a final response.

Pretty much write a paper called X-of-Thought and you will get into this section.
Ensembling
This is another classic machine learning technique where you use multiple techniques, models, or prompts to solve a problem, then aggregate the responses into a final output. The easiest aggregation method is just voting and taking the majority.
Demonstration Ensembling (DENSE)
mukhalConclusion
It was fascinating to read the Prompt Report and get to talk to Sander Schulhoff during the live dive. While originally, prompting only seemed like a solution for non-technical people, seeing these prompt techniques in practice have changed my approach to solving ML problems. I look forward to see the next developments in prompting and using it more in my workflow, tell us what you think!
Also make sure to claim your $10 free credit for Oxen's new model evaluation feature and let us know how your evaluations are going!