OpenCoder: The OPEN Cookbook For Top-Tier Code LLMs


Welcome to the last arXiv Dive of 2024! Every other week we have been diving into interesting research papers in AI/ML. In this blog we’ll be diving into Open Coder, a paper and cookbook for how to build an open and reproducible code LLM which matches the top-tier coding LLMs of similar sizes, and how to generate synthetic data for your own code LLM. What’s cool about this work is not only do they release the model weights, but they release all the code and the data as well.
We’ve collected all the datasets in the paper and put them on Oxen.ai for you to fork and iterate on yourselves. We’ll be referencing some of the data later so feel free to explore beforehand if you'd like:

You can also follow along with the recording of the live arXiv Dive:
Intro
Code specific LLMs have become an integral part of developers workflows. Whether you use Cursor, GitHub Co-Pilot, or are experimenting with Agents to help with the software engineering process, there is no doubt that writing code is one of the first use cases for LLMs that has really taken off, especially in the developer community.
For simple data processing steps I find myself writing less and less code manually and just firing it over to Claude.
— Greg Schoeninger (@gregschoeninger) December 18, 2024
Still in auto-complete mode for larger codebases, but one off scripts, I write most the logic in plain english and watch the LLM do the rest for me. pic.twitter.com/oCP7Csa81i
Despite the success of closed source models performing well on coding tasks, open source has trailed behind. This is mostly because of lack of open source datasets to train open models.
This lack of transparency limits the research community and the ability for coding LLMs to run locally or on data repositories that need to be kept private and can’t be sent over API to foundation model companies. Wouldn’t be great if you could have a Coding LLM that was optimized to run locally and you could even fine tune on your own code repositories?
Enter OpenCoder ⭐️

Not only are the model weights open, but the entire data processing pipeline, pre-training datasets, post-training datasets, and intermediate checkpoints are available as well.
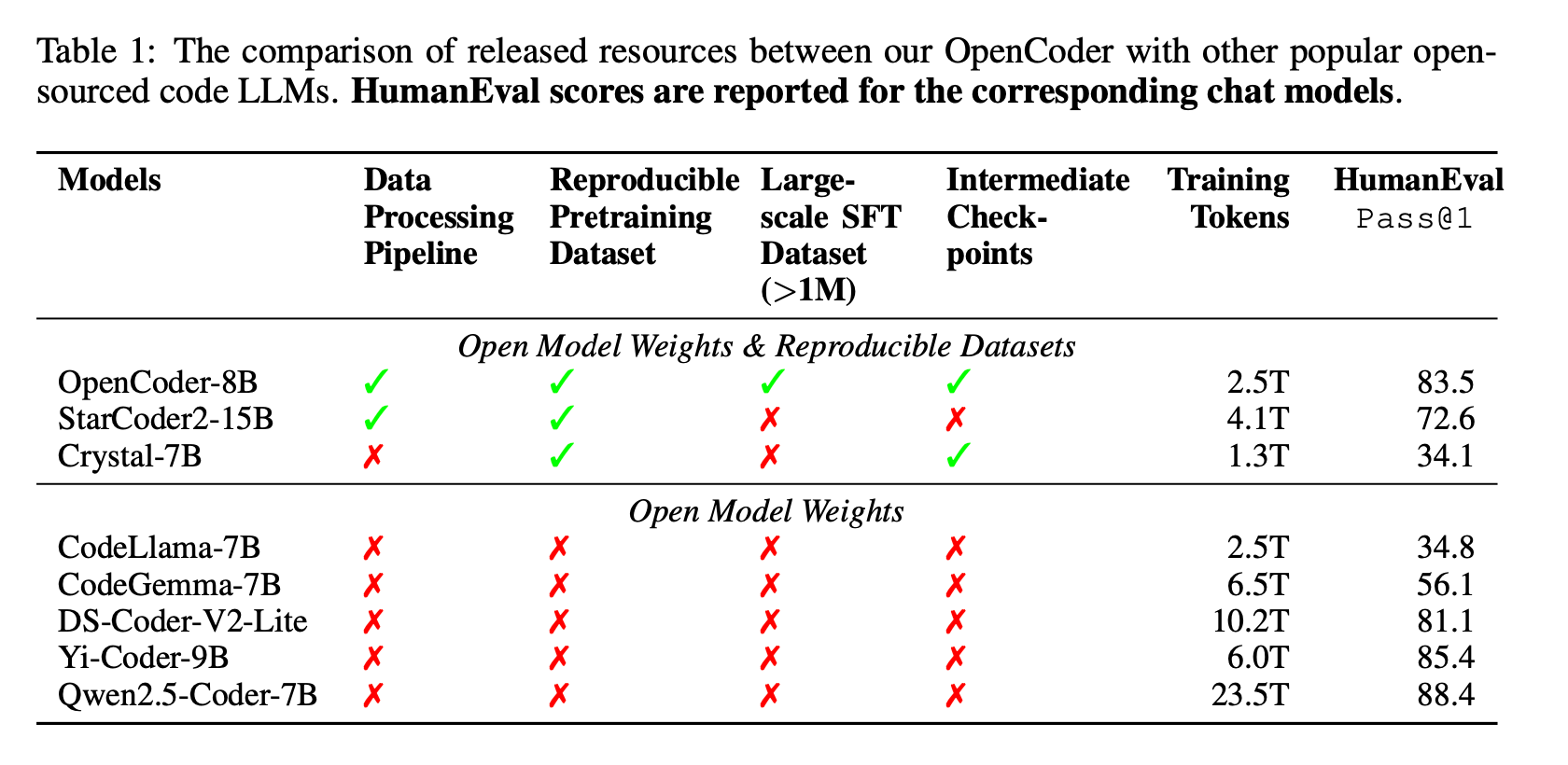
Other “Open” LLMs simply open source the weights and not the full data pipeline.
The reason I think this is most exciting is the ability for users to customize and iterate on LLMs for more advanced use cases.
For example, take this challenge:
I'll give $1M to the first open source AI that gets 90% on this sweet new contamination-free version of SWE-bench - https://t.co/o7LuYKIfhO pic.twitter.com/tOzYmxrH0E
— Andy Konwinski (@andykonwinski) December 12, 2024
If you are not familiar with this challenge, the premise is pretty cool and builds off of SWE-Bench. The idea is can you build an LLM or Agent that solves GitHub issues and make their unit tests pass.
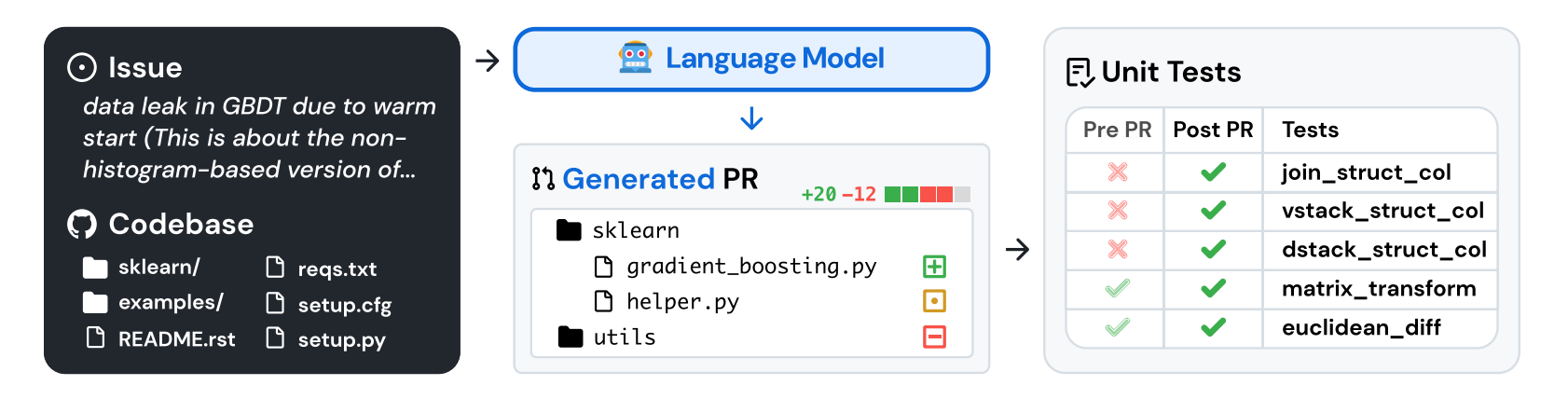
The problem with the existing SWE-Bench benchmark is data contamination. There is no guarantee that the models have not seen these issues in their pre-training data.
In order to solve this, KPrize is using “time” as a data contamination filter. They plan on collecting a new test set after the submission deadline. This means they will stop accepting submissions on March 5th, 2025, then start collecting github issues for the next three months after the submission.
Funny question I heard at his neurips talk:
Q: “How will you prevent people from gaming the system by submitting GitHub issues that their model knows how to solve?”
A: “You would have to submit actual issues to popular projects, they would have to be high value enough to get accepted, and get solved, and if you do that…hey! Win win for the Open Source community. Go ahead and good luck.”
I think you have a stark advantage to win this competition by building on top of a fully reproducible LLM. Data and all.
More Info:

OpenCoder Goals
Open Coder has 3 primary goals:
- Provide researchers with a meticulously curated and transparent strong baseline
- In-depth investigations into data curation pipelines
- Unlock more diverse customizations for Code LLMs
Data curation is integral in the process and they highlight 5 Data Curation Stages
- Pre-training data cleaning
- Deduplication
- Using GitHub stars as a signal
- Data Quality > Data Quantity
- Starting with Instruct tuning then doing code-specific tasks
Pre-training Data
A popular pre-training dataset for code is The Stack v2.

This paper argues that this dataset is not high enough quality to train top performing LLMs.
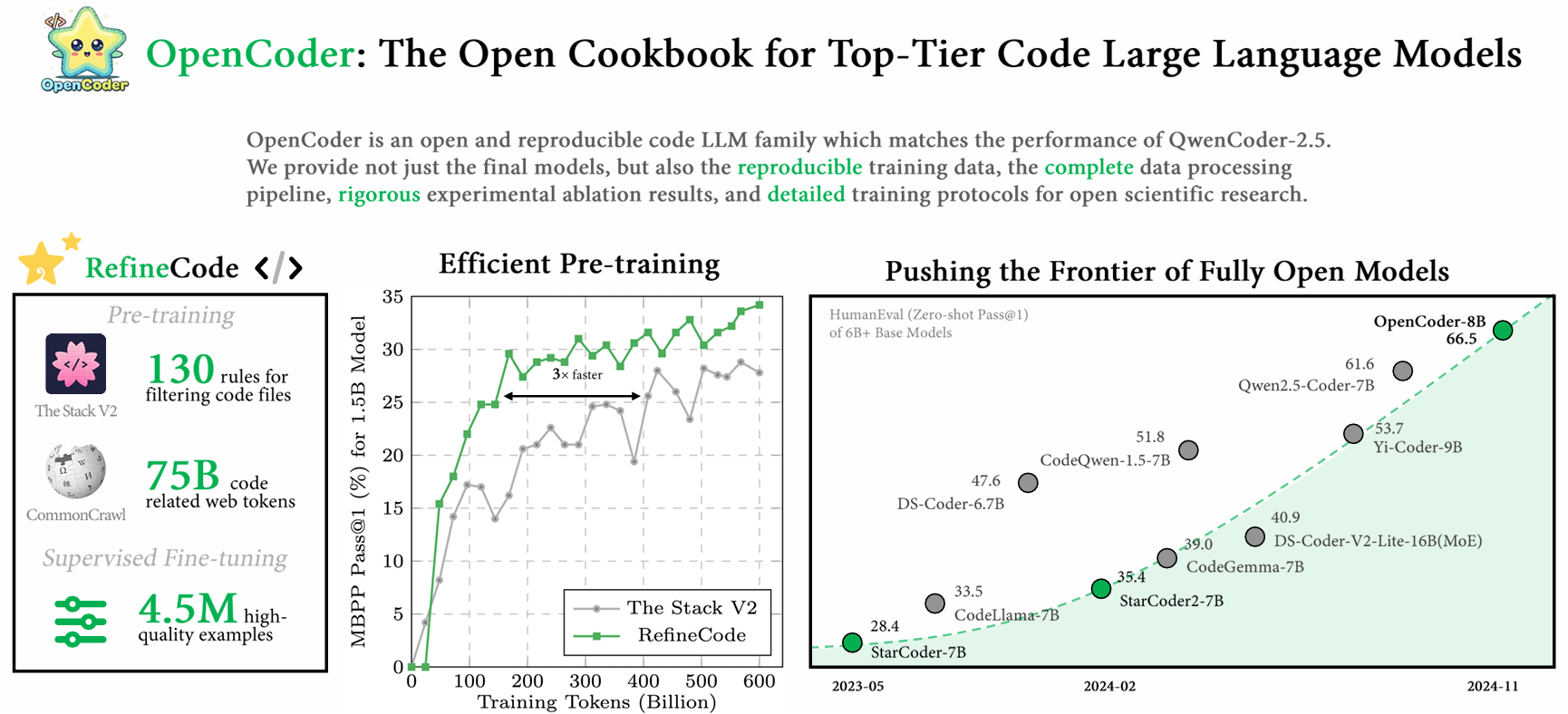
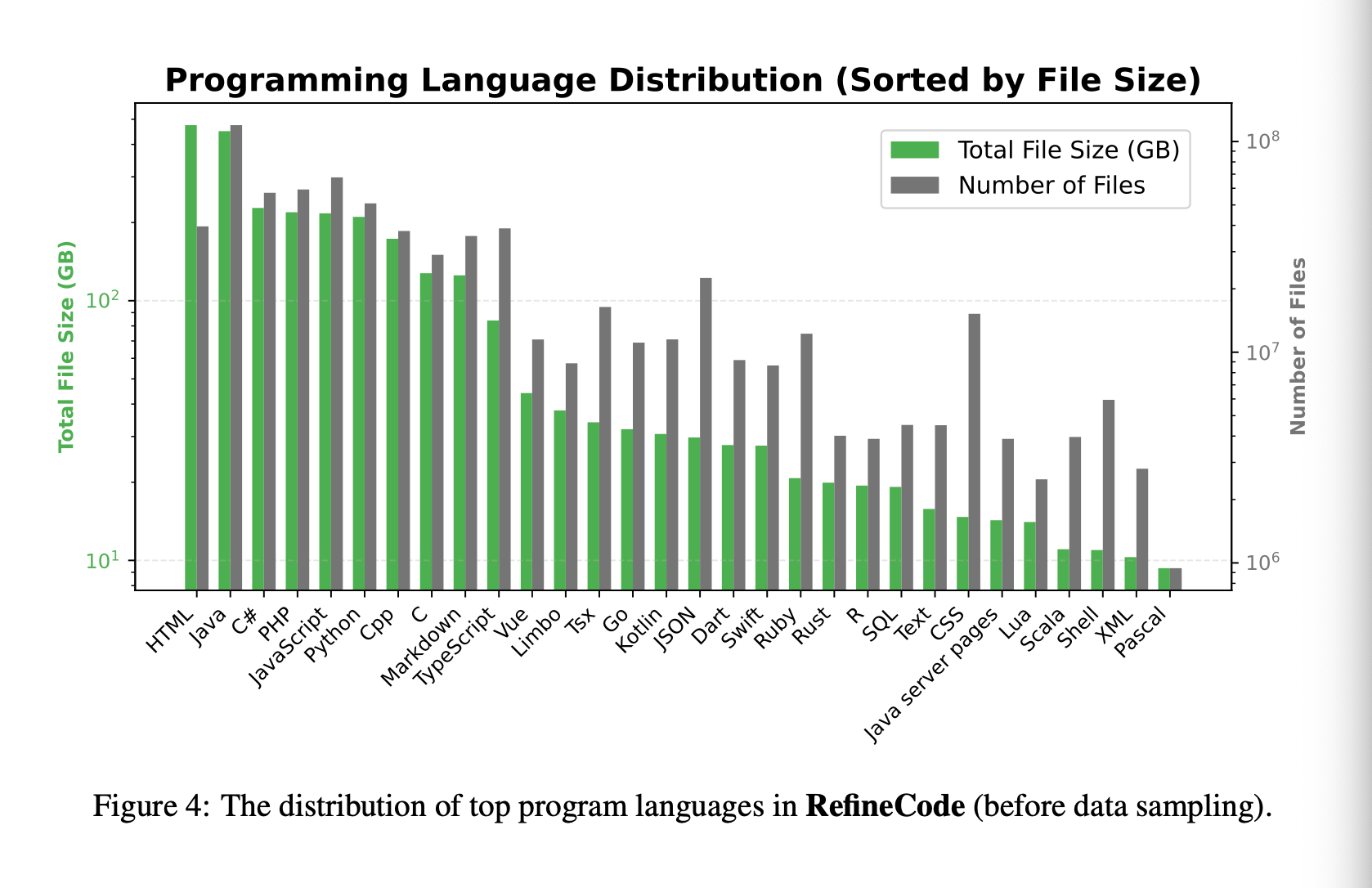
RefineCode
To address this, they present RefineCode which is a high-quality, reproducible dataset of 960 Billion Tokens across 607 programming languages. There are over 130 language specific rules with weight assignments that they use to filter the data.
Raw Code for Pre-training
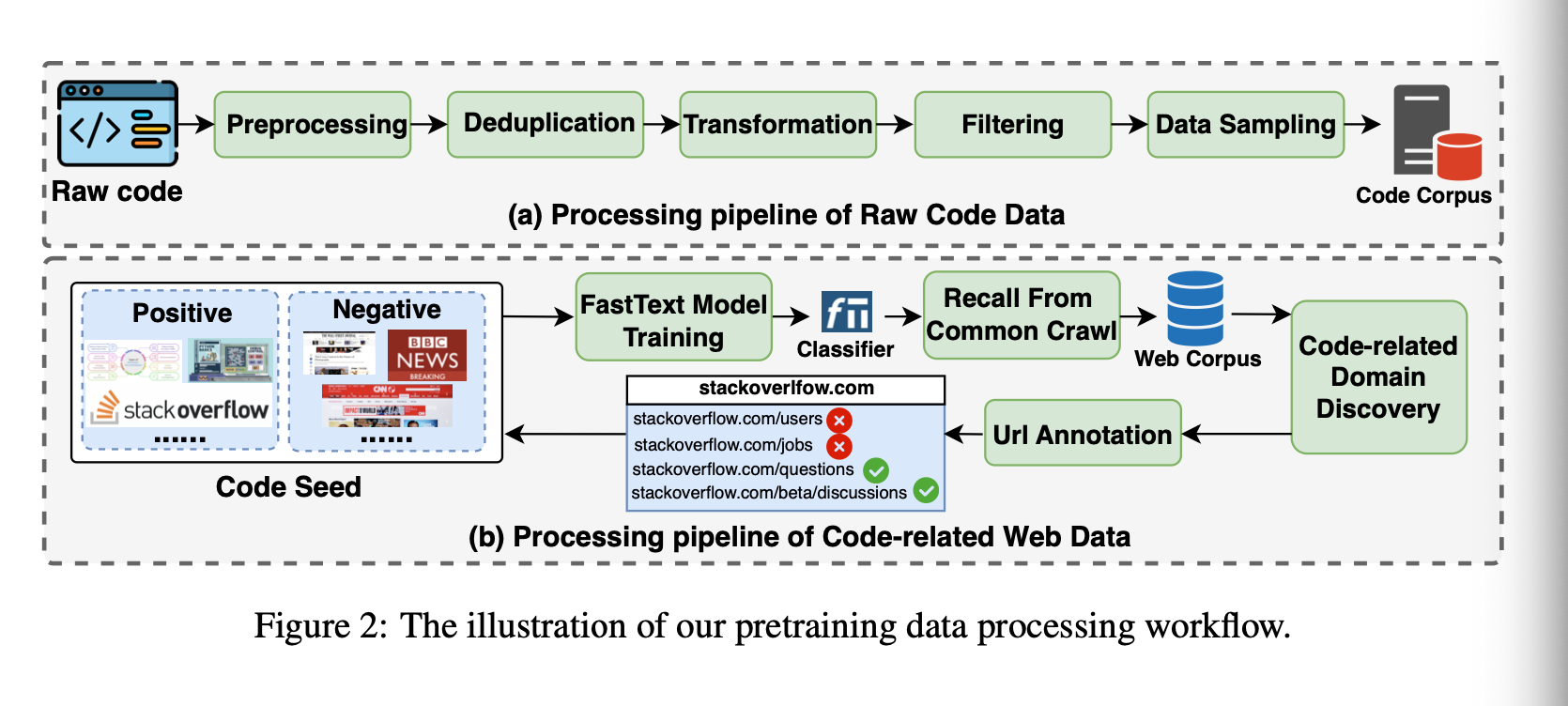
The pre-training stage is simply predicting the next token from a large corpora. This corpus was generated and curated with the following 5 steps:
- Preprocessing
- Deduplication
- Transformation
- Filtering
- Sampling
Preprocessing
To limit the data to files that are likely text files they filter out anything greater than 8MB in size. They also use linguist to determine the language.
They end up preserving 607 different programming languages.
Deduplication
There is a lot of duplicate or repetitive code on GitHub due to forking and copy/pasting of code from stack overflow etc. They wanted to prioritize deduplication as early in the pipeline as possible.
There are two ways they de-dup:
- Exact Deduplication: Nearly 75% of files are completely duplicated. For each document a SH256 hash is computed, then code files from the highest star count + latest commit are retained.
- Fuzzy Duplication: The text is split into 5-gram pieces, then MinHash is used to compute similarity. Again the files with the highest star count and latest commit time are preserved. This discards 6% of the data.
Deduplication at a file level seems to have a large impact on performance per token.
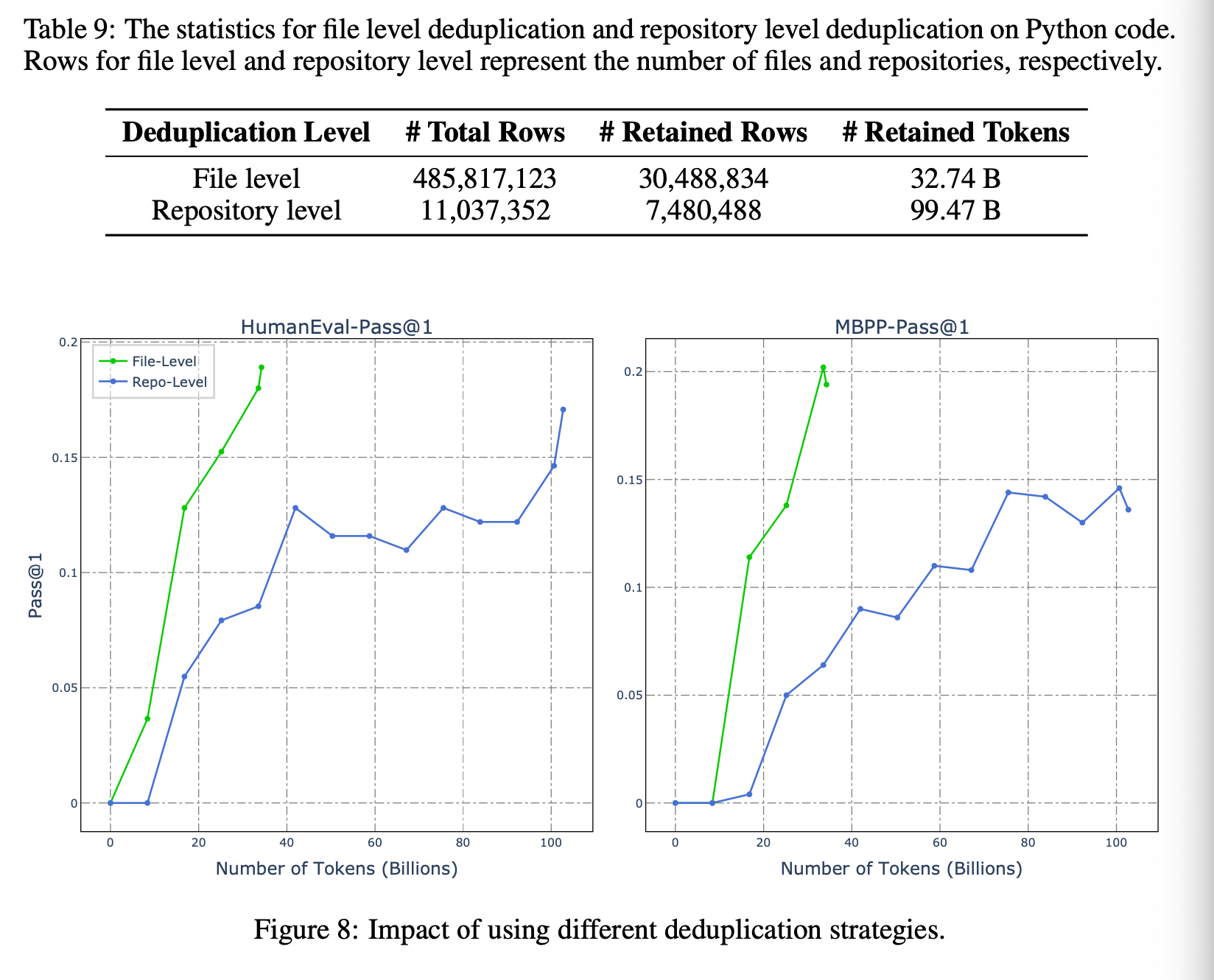
Transformation
Many files may have snippets information that is not useful in their headers such as “Copyright Intel Corporation (C) 2014-2016” which is stripped out.
PII is also stripped out via regexes for passwords, names, emails, and IP addresses. They are replaced with special tokens.
Filtering
They took inspiration from the Textbooks Are All You Need paper for some of the filtering rules.

“One can only imagine how frustrating and inefficient it would be for a human learner to try to acquire coding skills from these datasets, as they would have to deal with a lot of noise, ambiguity, and incompleteness in the data.”
This leads them to write heuristics to:
- Filter out files with poor self- containment;
- Filter out files with poor or minimal logical structure;
- Remove files that deviate significantly from standard formatting.

There are more concrete examples in the appendix. Here are some general code rules:
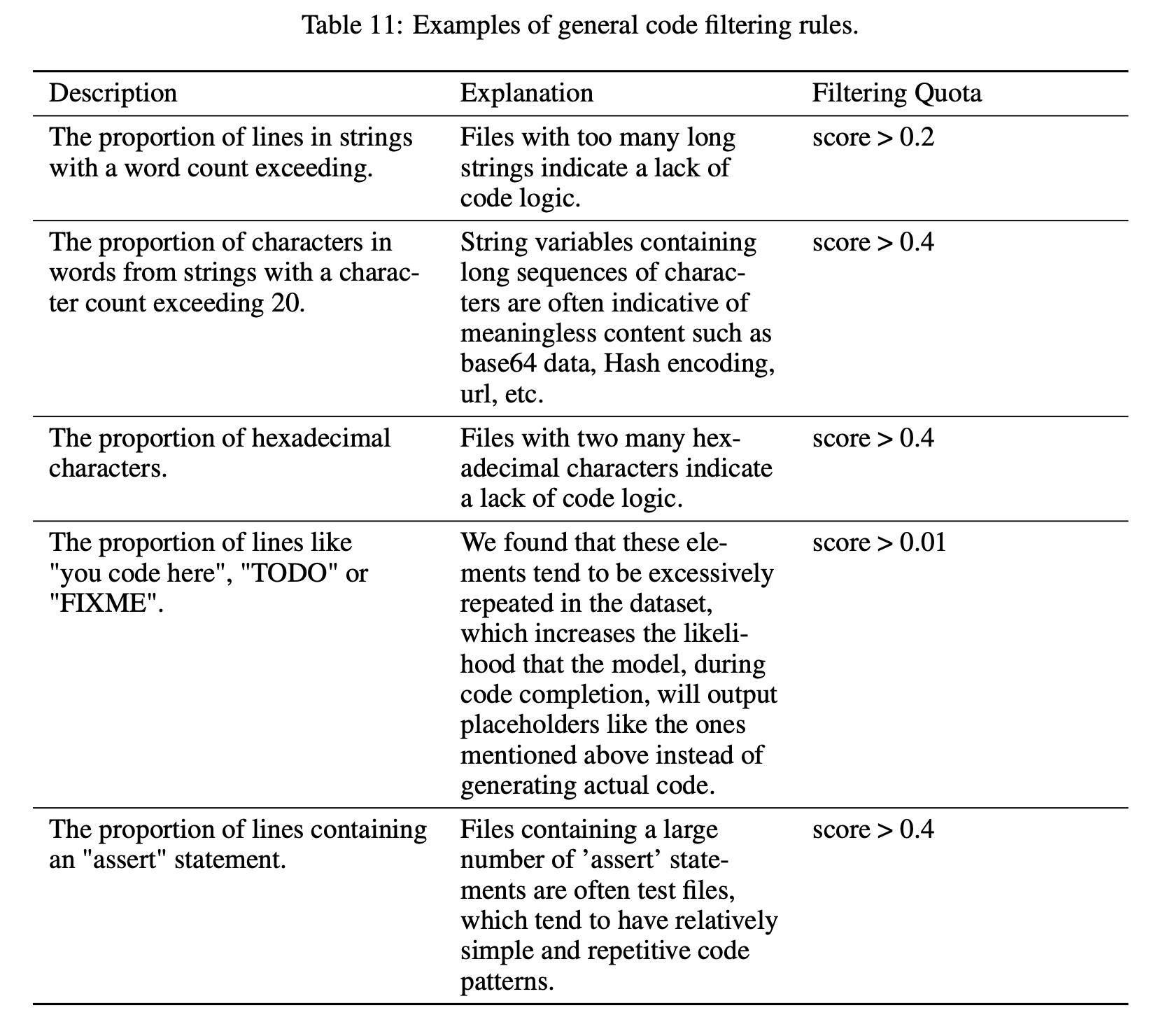
Here are some example python specific rules:
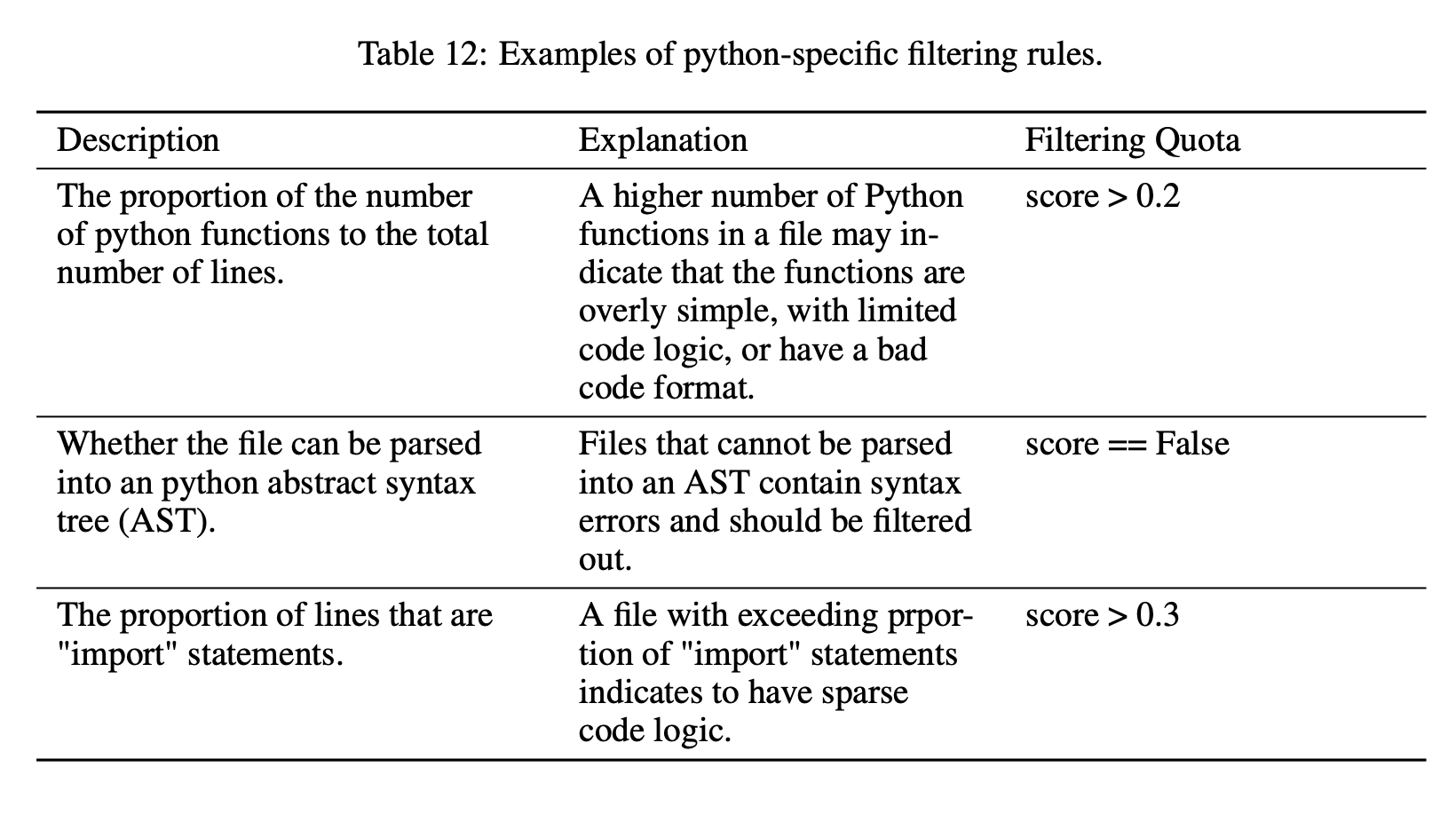
You can find the code for these rules here:

Surprisingly, filtering by GitHub stars had an impact than you would expect.
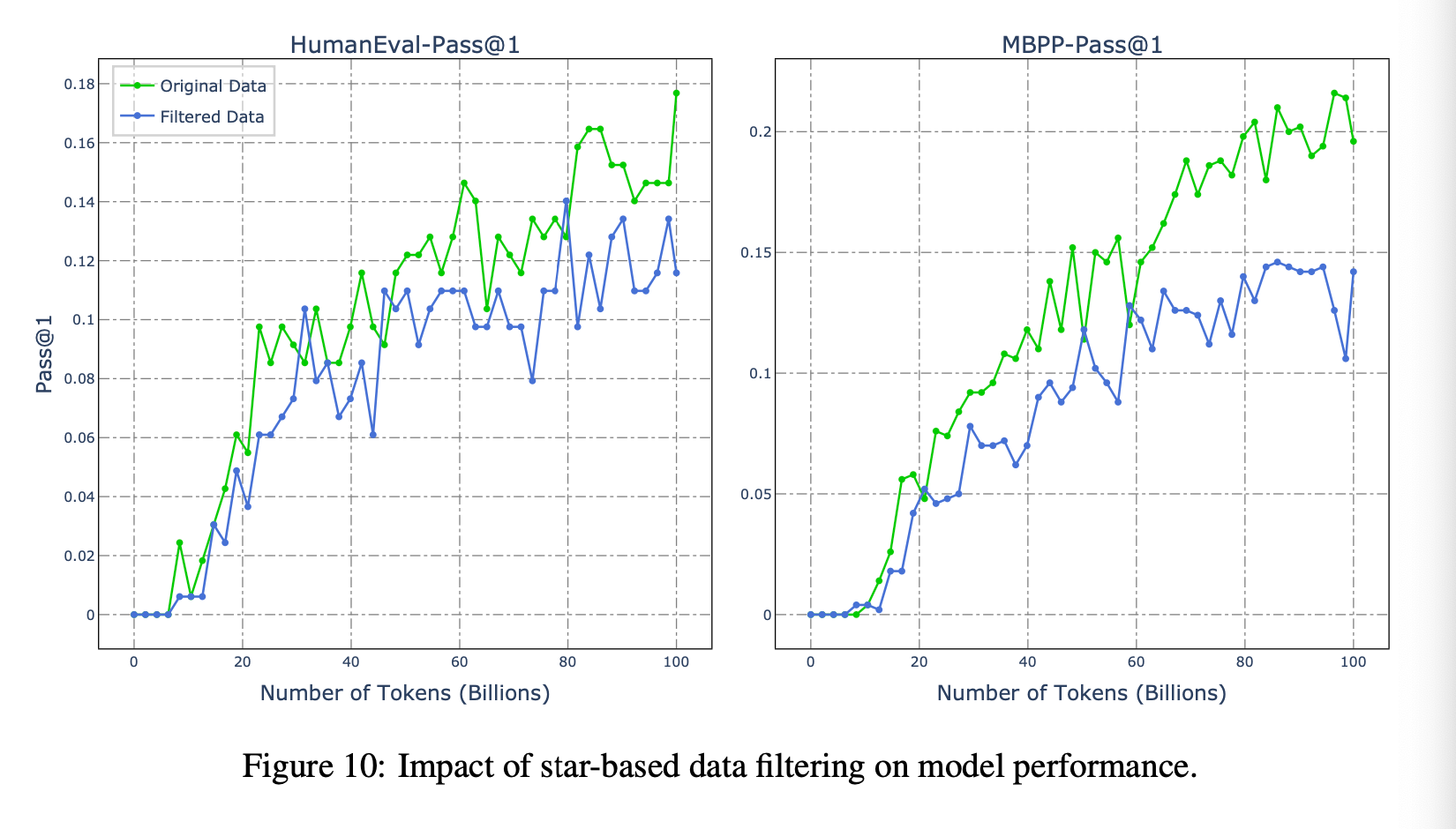
Sampling
Certain languages are over represented in the dataset such as Java and HTML - so they downsample them to make it a more even distribution.
Specifically, they downsample Java data from 409GB to 200GB and HTML from 213GB to 64GB.
How well does all the cleaning and filtering work? They looked at PCA of embedding extracted from Code-BERT model on the two distributions.
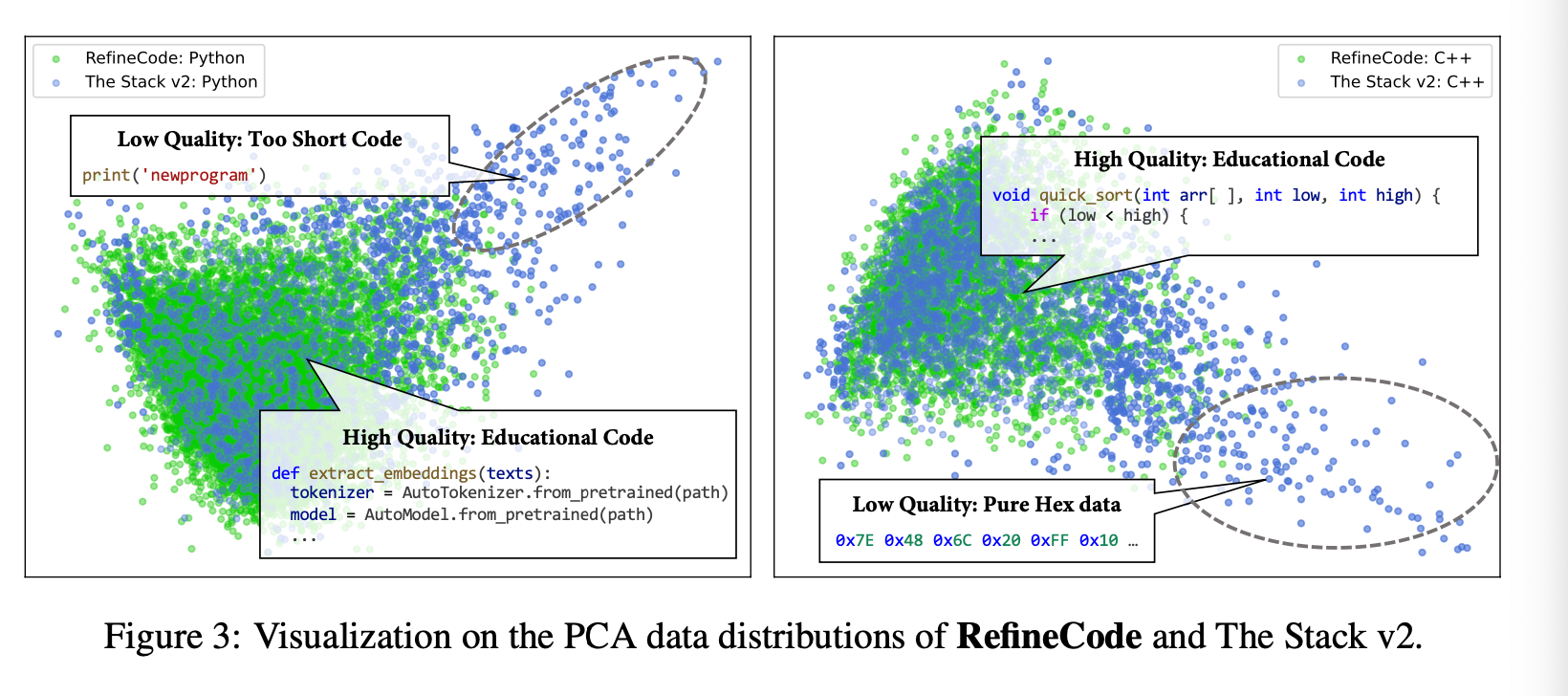
Notice the Stack V2 has large areas of garbage that we don’t want to train on such as short snippets and hex patterns.
Code-Related Data
They also filter down CommonCrawl, FineWeb, and Skypile to find “Code-Related Data”. They use fasttext as a classifier of whether text talks about code related topics.
Think of this as blog posts talking about code, stack overflow posts, etc.

Annealing Data
Like we’ve seen in the Llama papers, putting the highest quality data at the end of the pre-training helps model performance.
It is important that this high quality data comes from similar distributions as the rest of the pre-training data (same languages, etc) or else the model may suffer from catastrophic forgetting.
This high quality “annealing” data comes from data that is likely to be from “leetcode” style questions or has have tests to go with them.
Synthetic Data
For the high quality annealing data, they also leverage a strong LLM to synthesize batches of independent functions with their corresponding test cases. The synthetic data must pass the test cases after translation.
Training Details
Two models were trained:
8 billion params:

1.5 billion params:


The 1.5B model was trained using the Megatron-LM framework (which Ethan Ye from Nvidia works on, he was on a previous Arxiv Dive)
The 1.5B model was trained on a cluster of 256 H800 GPUs over a total of 109.5 hours (4.5 days), equating to 28,034 GPU hours.
The 8B model pre-training was conducted on a cluster of 512 H100 GPUs over 187.5 hours (~8 days), totaling 96,000 GPU hours.
Post Training
Once the model can complete snippets of code from pre-training on a massive dataset of raw code, we need to teach it to follow instructions. This is called “instruct-tuning” or post training.
This data typically looks like instruction, output and is available on Oxen.ai here:


They collate a bunch of Open instruct datasets here and filter down to the questions that relate to code. I collected a bunch of data mentioned in the paper here:

In order to generate high quality synthetic instruction data they have three different pipelines.
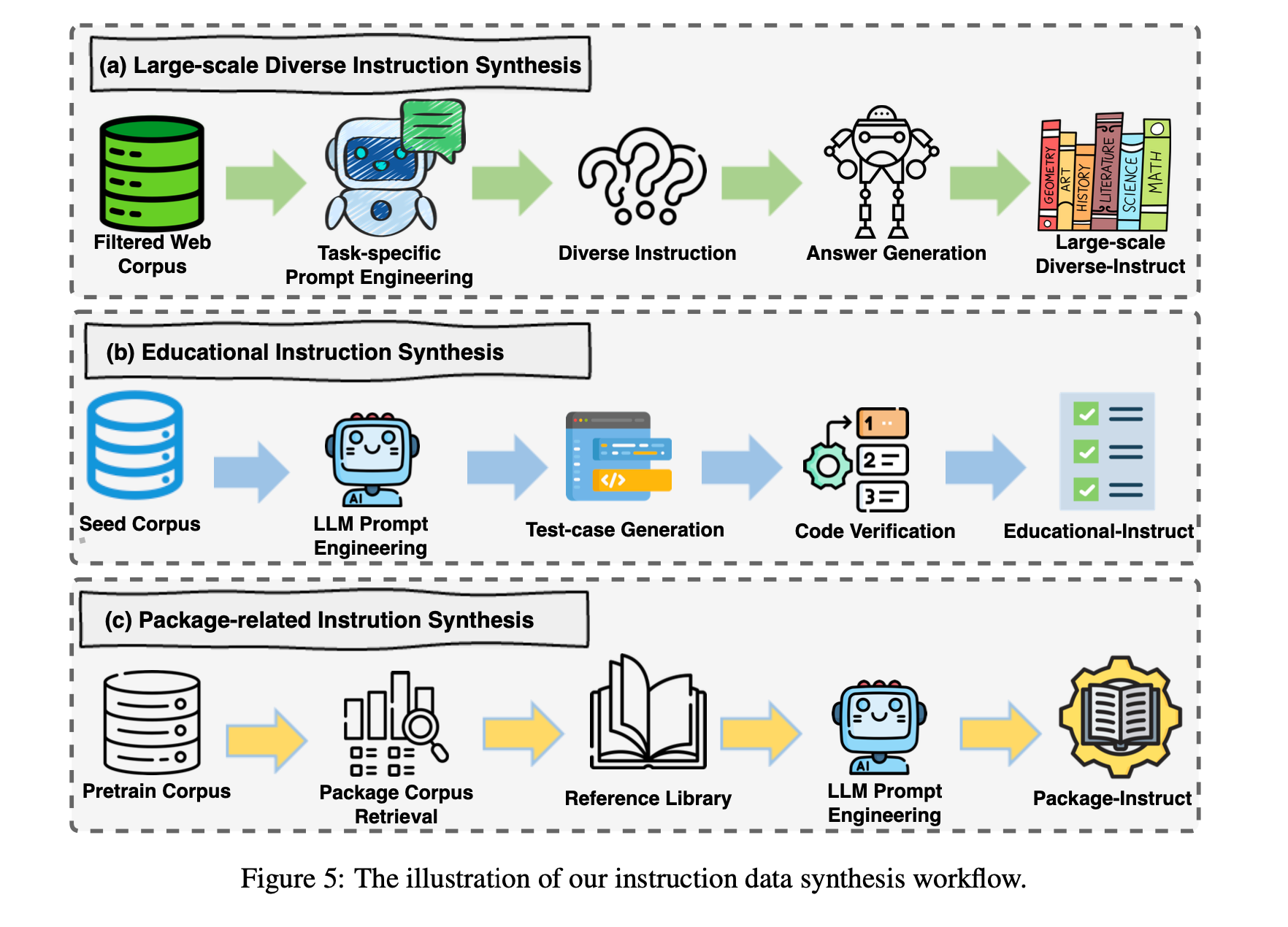
The prompts for these different pipelines are available in the Appendix:
a) Large Scale Diverse Instruction Synthesis
They leverage the filtered web corpus plus prompt engineering to generate synthetic questions given the text. They give the first prompt, but unfortunately they do not give much detail into other prompts they used to filter and clean out invalid questions or bad responses.

b) Educational Instruction Synthesis
They also take snippets of source code and have LLMs generate reference solutions, test cases, etc.

c) Package Related Instruction Synthesis
A big problem in code generation is outdated libraries and code in the pre-training data. This affects the model’s ability to call tools or be affective in the real world.
To combat this they synthesize tool usage data based on documentation of these libraries. They use a strong LLM to generate up to date question - answer pairs based on PyDoc and other tools.

I wish they gave a little more info on these steps do be honest, and I couldn’t find any code for this synthetic data generation in their github repositories. Probably due to licensing reasons.
Fortunately these pipelines are very similar to synthetic data pipelines we have seen in the past, and you could generate your own synthetic data given the prompts below and Oxen.ai’s Model’s feature.
Generating Synthetic Training Data
You can pick a strong model like Qwen2.5 72B Instruct and run it on a set of data to see the results.
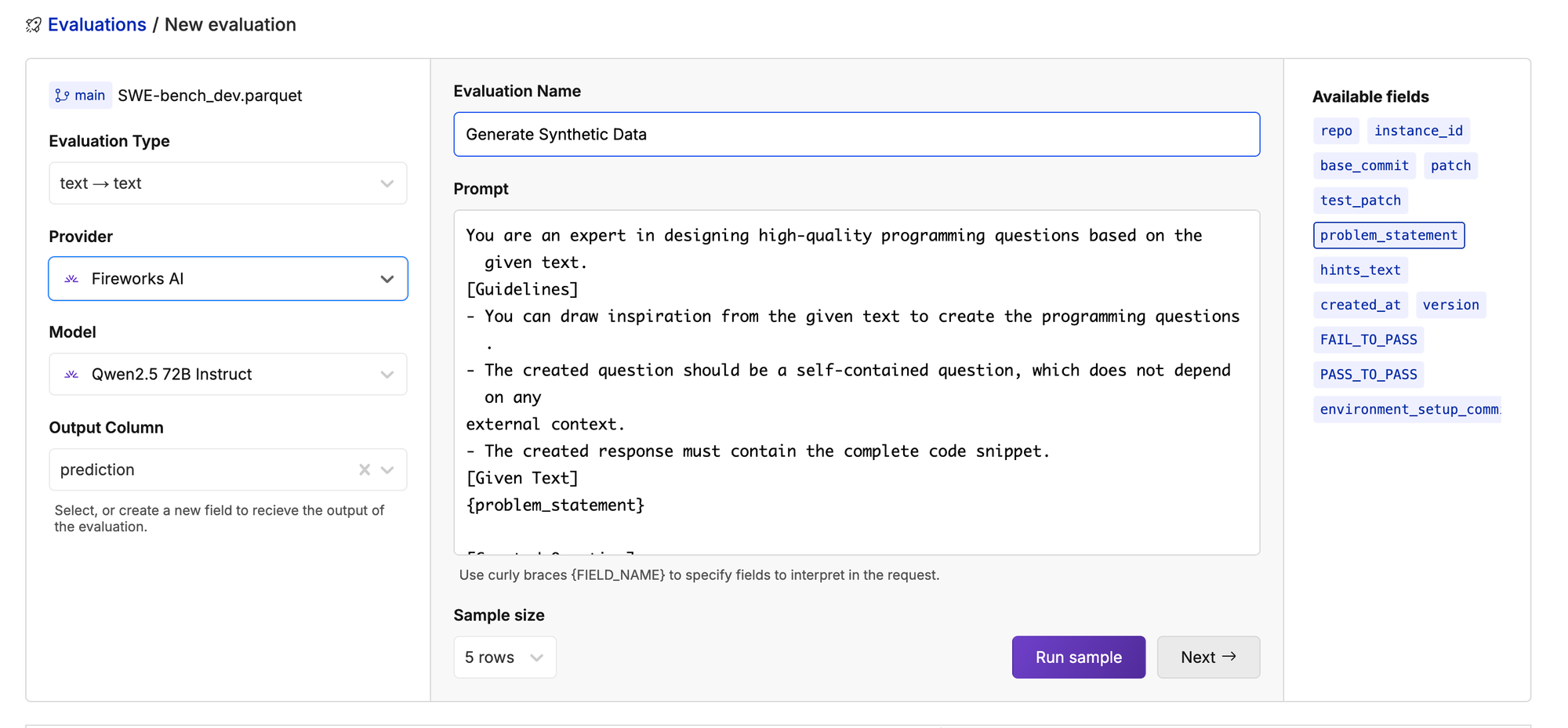
Let’s try it!
(feel free to fork the repository into your own namespace)

You are an expert in designing high-quality programming questions based on the given text.
[Guidelines]
- You can draw inspiration from the given text to create the programming questions.
- The created question should be a self-contained question, which does not depend on any
external context.
- The created response must contain the complete code snippet.
[Given Text]
{content}
[Created Question]
Two Stages of Instruct Tuning
They split the instruct-tuning into two stages “theoretical computer science knowledge” and “practical coding tasks”.
The first stage they generate Q-A pairs based on algorithms, data structures, and networking principles. This ensures that the model can respond with greater precision to questions about concepts such as binary search trees, dynamic programming, and the intricacies of object-oriented design patterns.

The second stage switches to practical coding tasks. This data consists of high quality code from GitHub. The code should be well maintained and formatted code.

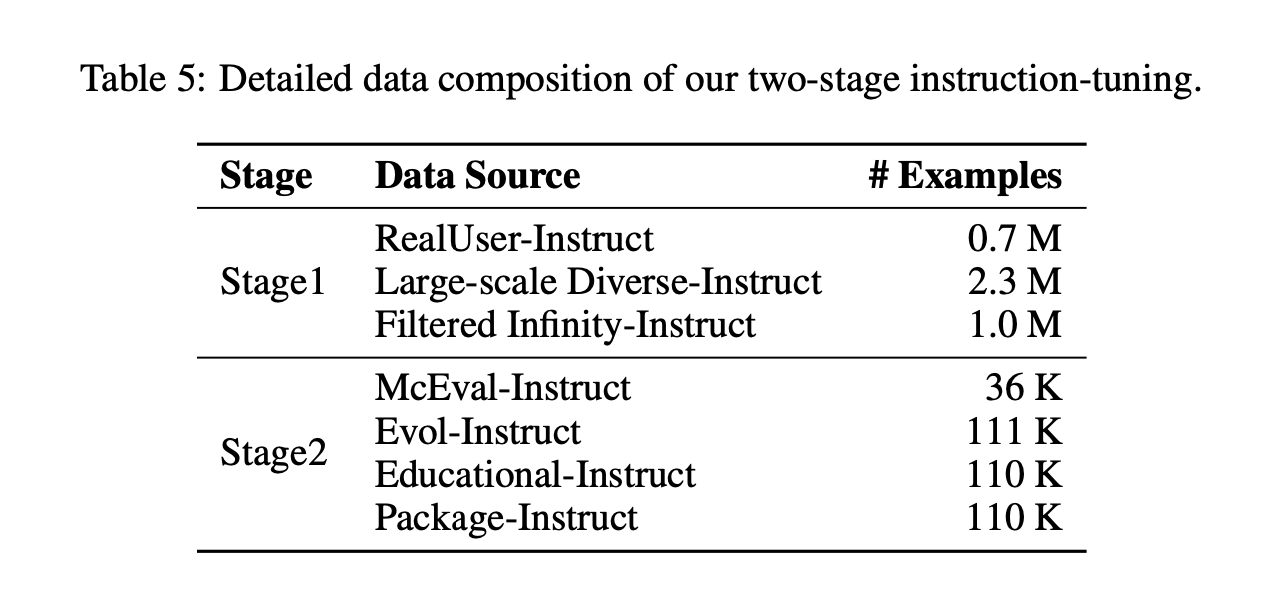
They train on the first set of data for 1 epoch with batch size of 4096 and the second set for 3 epochs with the batch size of 512.
They remove any data that has overlap with benchmark datasets such as HumanEval or MBPP.
In order to see the impact of the two step training, they adopt the CodeArea test set and use GPT-4 as a judge.
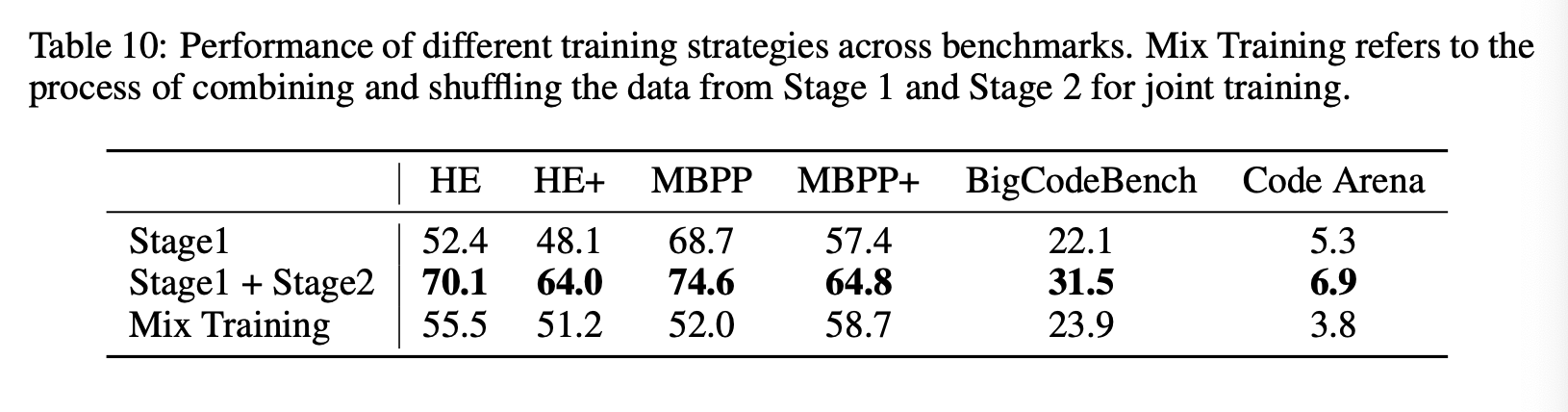
The progression of learning broad strategies before practical implementation seems to give the model a big boost.
I wonder if GPT-4 prefers more practical responses, and that the model then is tuned to lean more practical at the end. It would be interesting to eval with a few more judges and prompts.
Evaluation
They first evaluate the base models on the ability to complete code snippets, GitHub Copilot style.
This is the framework they used to evaluate:
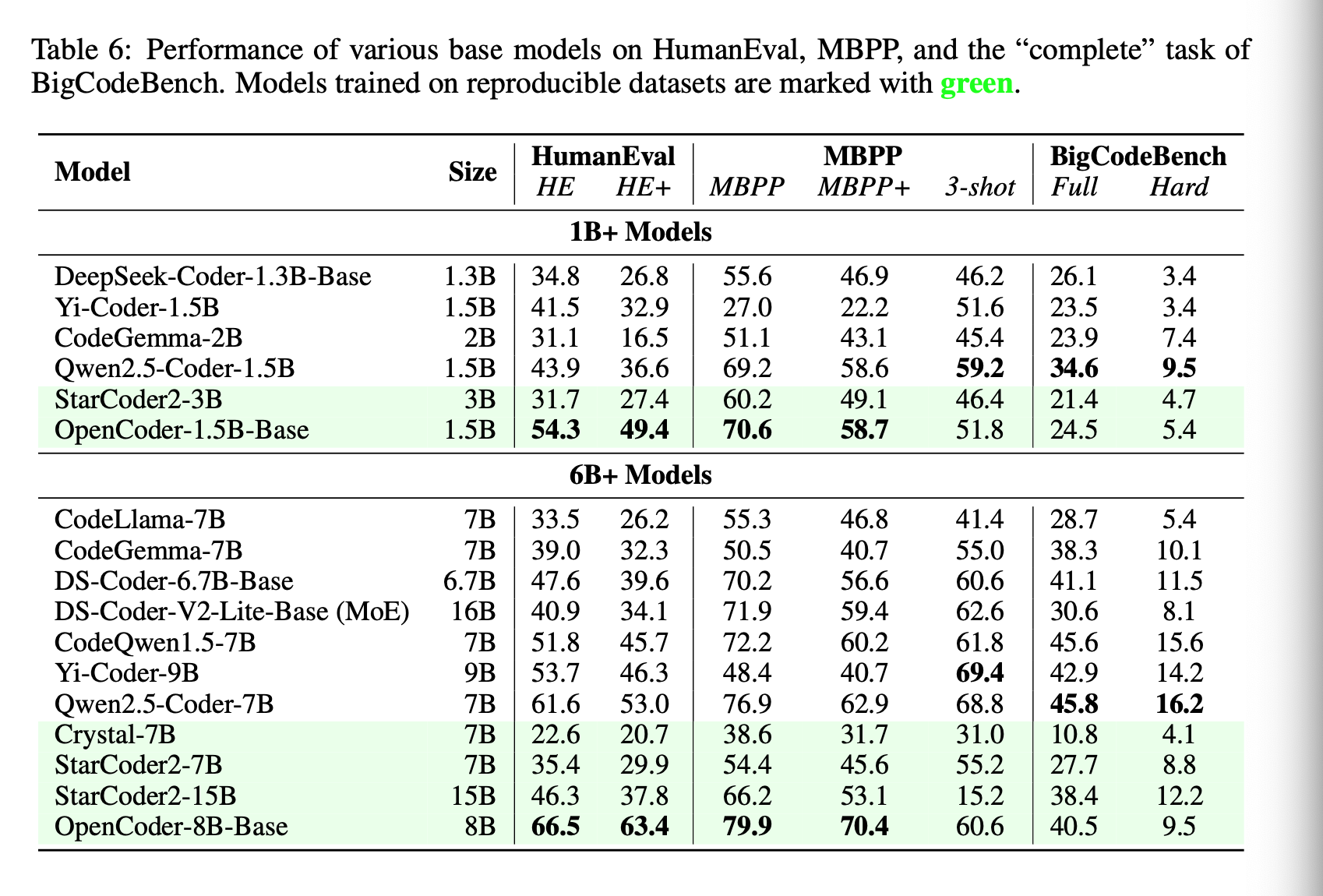
Then they evaluate the instruct models on the same benchmarks and a few more including LiveCodeBench and MultiPL-E.
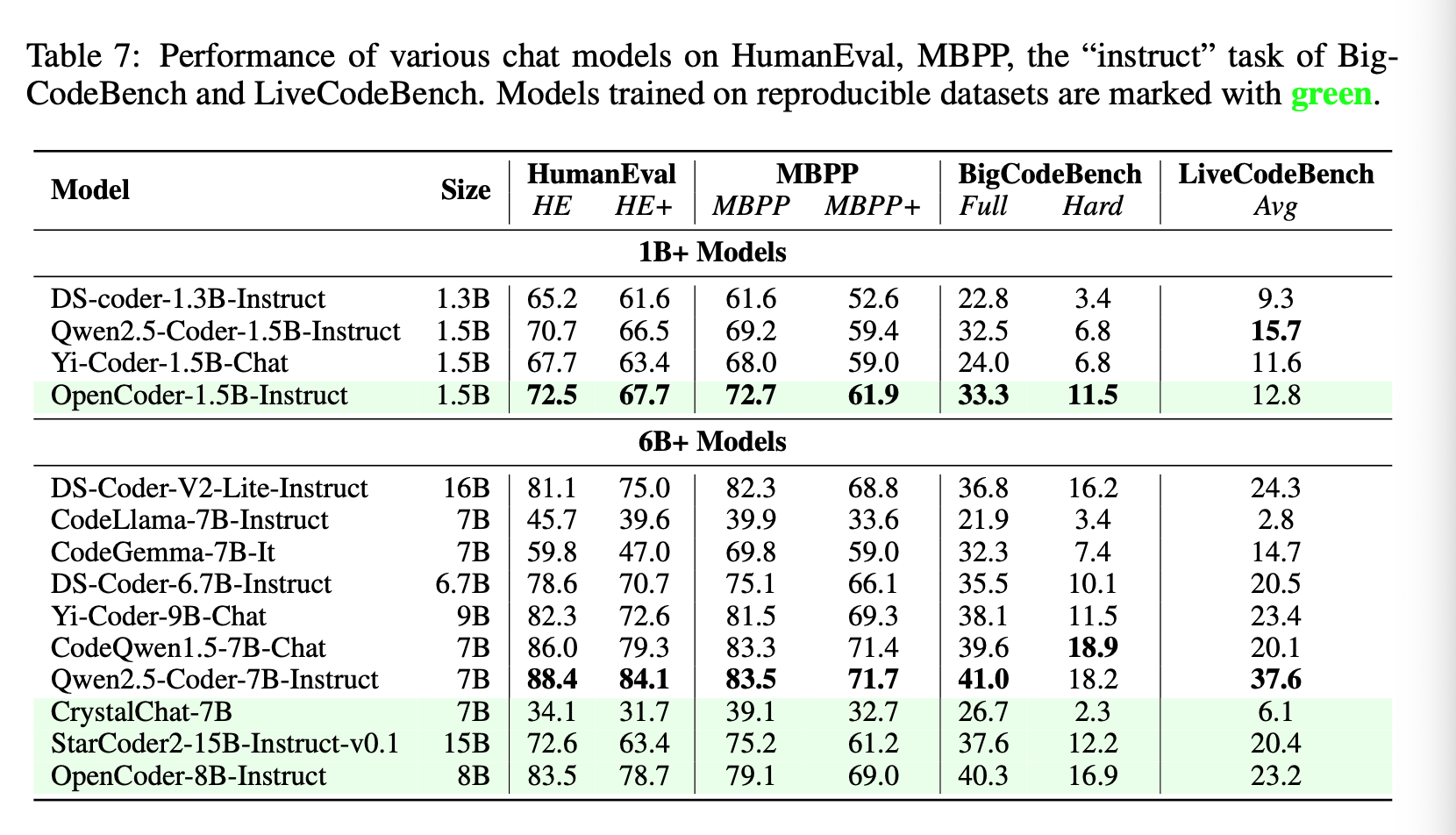
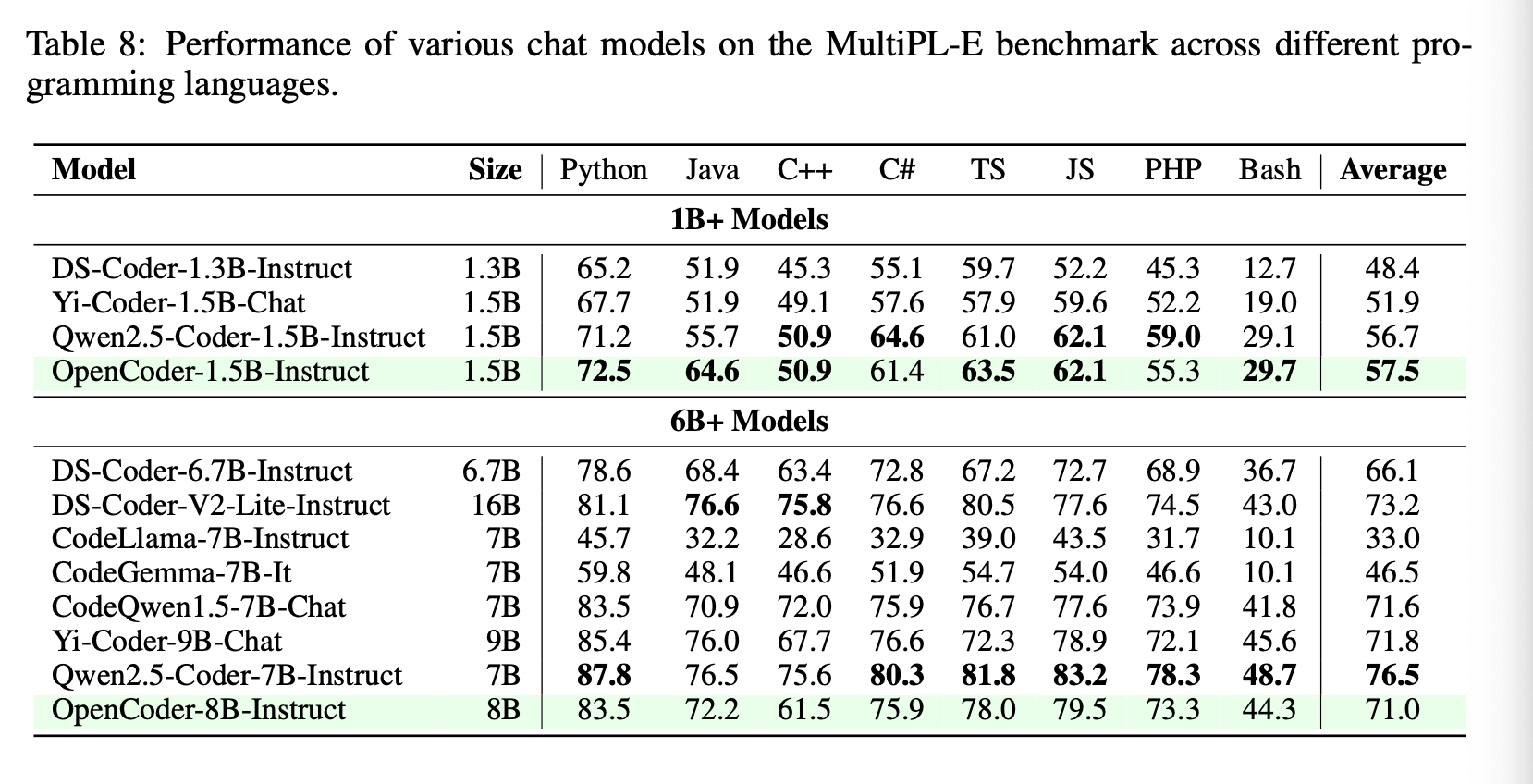
Conclusion & Future Work
I always harp on the fact that open models without open data is not in fact open-source. That’s like releasing a source code binary without any of the code that you can edit. At the end of the day, data is what powers how these LLMs behave. The fact that this paper open sources all of the data along with the models is huge win.
We are going to hack on the million dollar KPrize internal to Oxen on our Friday hack days. I would love to hear your thoughts or if you have tried using these models locally as well.