Practical ML Dive - How to train Mamba for Question Answering


What is Mamba 🐍?
There is a lot of hype about Mamba being a fast alternative to the Transformer architecture. The paper released in December of 2023 claims 5x faster throughput when compared to Transformers and scales linearly with the length of the sequence instead of quadratically.
Last Friday we did a deep dive into how the model architecture works. If you are curious about the internals, check out our Arxiv Dive covering the paper.
 Greg Schoeninger
Greg Schoeninger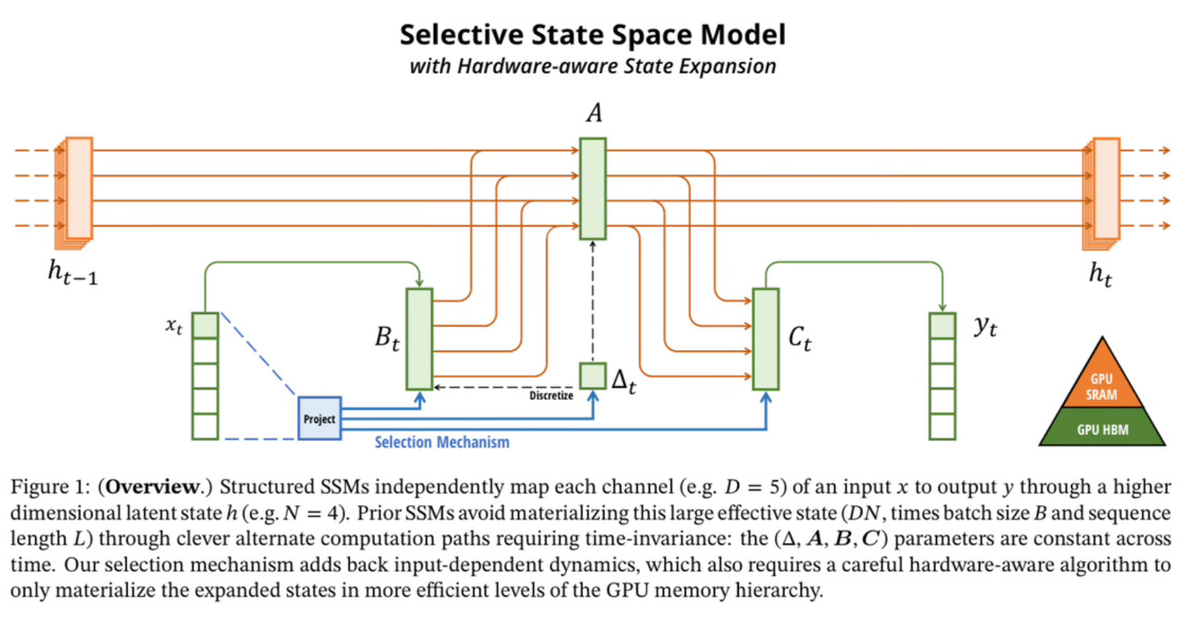
If you do not need to know about the internals, and just want to see how the model performs on your data, this is the blog post for you!
Practical ML Dive
This post is a part of a series called Practical ML Dives. Every Wednesday we get together and hack on real world projects. If you would like to join the practical discussion live, sign up here. Every week there are great minds from companies like Amazon Alexa, Google, Meta, MIT, NVIDIA, Stability.ai, Tesla, and many more.

The following are the notes from the live session. Feel free to watch the video and follow along for the full context.
What are we building?
Today we will be building a Question-Answering system using Mamba as the base LLM.
Q: What is the capital of Norway?
A: OsloThis topic is close to home for me, as I worked many years on question answering for a small startup called AlchemyAPI that eventually got acquired into IBM Watson. Systems like IBM Watson had many hand crafted features to be able to answer Jeopardy Questions. At the end of the day, Watson was just one giant logistic regression trained on top of hand engineering features.
Today, these LLMs abstract away all of these features in their parameters, so I am excited to see how well it does without all the manual writing of feature extractors.
I haven’t played with QA systems in years, so if you are ready, buckle up and join me on this journey to see how well a model like Mamba solves the problem.
Pre-Trained Models
Mamba in theory should be really well suited for the QA problem. Processing large context windows to extract an answer is a key component in building a system that can answer questions.
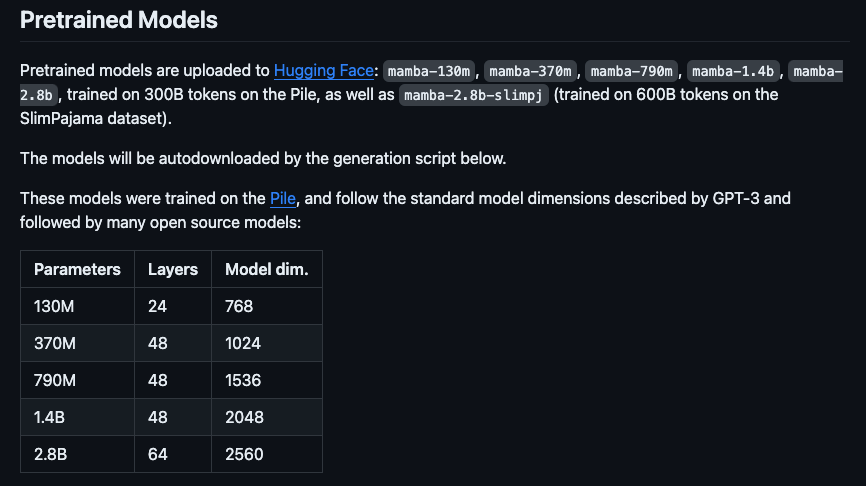
Before we get ahead of ourselves, let’s start simple and kick around the models that were released with the paper. There are a variety of pre-trained language models that were trained on the Pile dataset, all with different sizes.
The raw language models can be found on linked to on the GitHub repository.
https://github.com/state-spaces/mamba
Start Smol
For this practical session, I want to see what sort of bang for our buck we can get with the smallest model state-spaces/mamba-130m. The larger models in theory encode more hidden within their parameters, but they require you to have a large GPU and are slower to train.
Looking at nvidia-smi while training different size models, the largest I was able to successfully train was the state-spaces/mamba-790m model, but this one takes longer to train in general, and I only had a few days to run experiments.
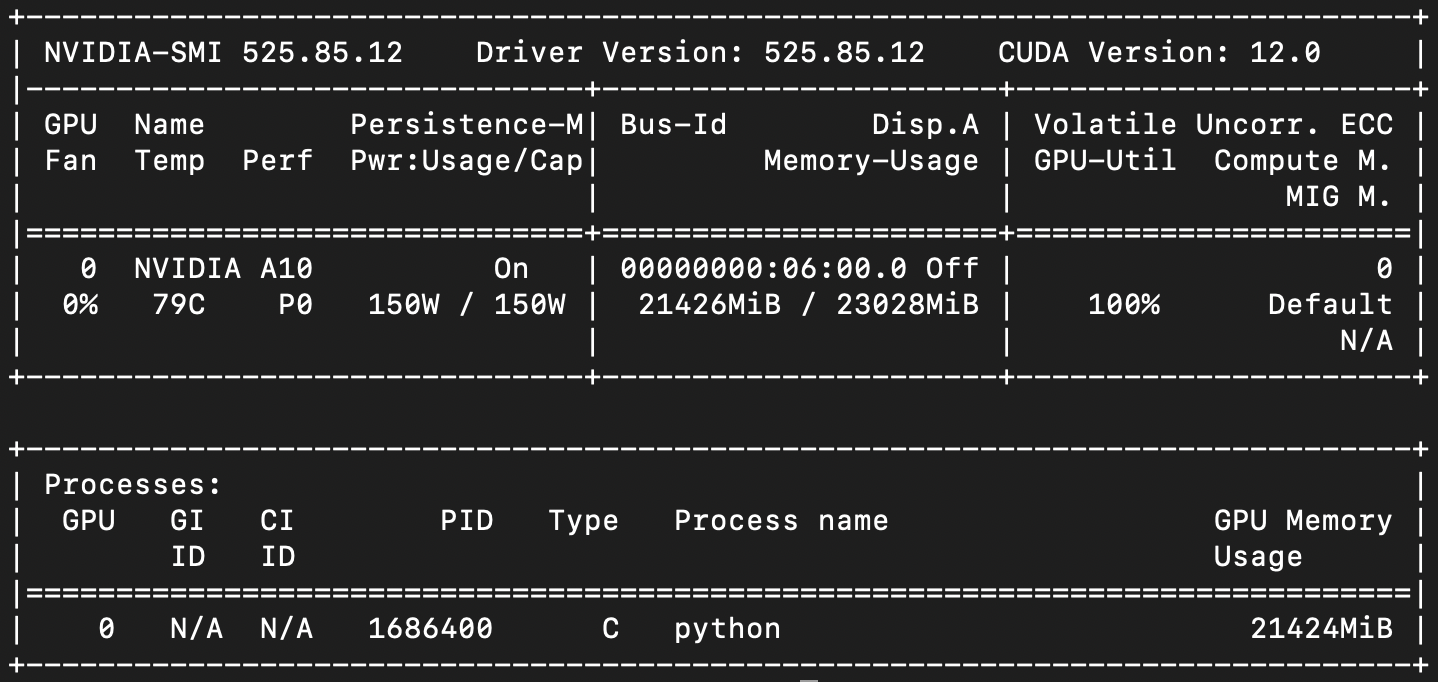
During training it seemed that sequence length mattered a lot, so while Mamba in theory has the nice property of scaling to sequence length of 1 million, in practice I was not able to train on very large sequence lengths given my 24GB GPU.
If you are GPU-poor like me, follow along and let’s milk the 130M model for all it’s worth.
The Code
Today we have a lot of code to cover, so I will be doing less copy-paste, and more running live so that we can see how the models behave.
All the code can be found here, and the dependencies can be installed with the requirements.txt
 Oxen-AI
Oxen-AINote: This code does require an NVIDIA GPU with CUDA installed to get up and running. If you are having problems with install, consult our Getting Started Appendix for tips I found useful to get everything running on the GPU.
Prompt Engineering
One of the many benefits of this large pre-training step, as discovered in the early GPT papers, was that we can prompt the model in different ways to get a variety of behaviors. This is talked about at length in the paper “Language Models are Unsupervised Multitask Learners”.
To learn more about the basics of prompting and why it is affective, check out our Arxiv Dive on the topic.
Greg Schoeninger
To see it in action, let’s start by prompting the raw language model. The following is a quick command line utility to test out the raw model.
This simplest form of interacting with this model is simply a while loop that prompts you for input. I hard coded a prompt in the loop to get us up and running.
The prompt
You are trivia bot. Answer the following trivia question.
{user_message}prompt_mamba.py
import torch
from transformers import AutoTokenizer
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
import sys
# Validate CLI params
if len(sys.argv) != 2:
print("Usage: python train.py state-spaces/mamba-130m")
exit()
# Take in the model you want to train
model_name = sys.argv[1]
# Choose a tokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
tokenizer.eos_token = "<|endoftext|>"
tokenizer.pad_token = tokenizer.eos_token
# Instantiate the MambaLMHeadModel from the state-spaces/mamba GitHub repo
# https://github.com/state-spaces/mamba/blob/main/mamba_ssm/models/mixer_seq_simple.py#L173
model = MambaLMHeadModel.from_pretrained(model_name, device="cuda", dtype=torch.float16)
while True:
# Take the user input from the command line
user_message = input("\n> ")
# Create a prompt
prompt = f"You are trivia bot. Answer the following trivia question.\n{user_message}"
print(prompt)
# Encode the prompt into integers and convert to a tensor on the GPU
input_ids = torch.LongTensor([tokenizer.encode(prompt)]).cuda()
print(input_ids)
# Generate an output sequence of tokens given the input
# "out" will contain the raw token ids as integers
out = model.generate(
input_ids=input_ids,
max_length=128,
eos_token_id=tokenizer.eos_token_id
)
# you must use the tokenizer to decode them back into strings
decoded = tokenizer.batch_decode(out)[0]
print("="*80)
# out returns the whole sequence plus the original
cleaned = decoded.replace(prompt, "")
print(cleaned)Simply run it by passing in the name of mamba the model you want to run.
python prompt_mamba.py state-spaces/mamba-130mYou can try this same script any of the models listed here:

🐍 Mamba Says What?
The problem is - raw pre-trained models are kind of like parrots 🦜. They like to repeat the last thing they said, with only slight hints of intelligence.
Let’s make our Mamba, more than a parrot. A flying Parramba if you will!

Running the script above with a few different prompts, quickly see the raw model is not very helpful on it’s own.
You are trivia bot. Answer the following trivia question.
'who is the current president?''Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'
'Who is the current president?'Very parrot like. Not very intelligent. What if I format it a little more like Q&A?
You are trivia bot. Answer the following trivia question.
Q: Who is the president?
A:B:
C:
D:
E:
F:
G:
H:
I:
J:
K:
L:
M:
N:
O:
P:
Q:
R:
S:
T:
U:
V:
W:
X:
Y:
Z: So we know it knows the alphabet at least! But okay. Still not much intelligence yet. Is this just because we are using the 130m model? Or can we squeeze a little more out of our silly parrot-mamba.
N-Shot Prompting
These raw language models often need a little more than a nudge to start generating coherent text. A technique called N-shot prompting can save us from some of the hard work of training.
The idea is simple, since our model acts like a parrot, give it a pattern to follow. We can construct a prompt with a few examples and see if it can generalize to the next one. This is a good way to poke at what inherent trivia knowledge our model has.
Let’s build a prompt that cues the model to follow this pattern:
You are a Trivia QA bot.
Answer the following question succinctly and accurately.
Q: What is the capital of France?
A: Paris
Q: Who invented the segway?
A: Dean Kamen
Q: What is the fastest animal?
A: Cheetah
Q: {user_input}
A: {model_response}Modifying our code above, we construct a prompt based on a set of N pre-defined examples of trivia questions.
# ... while True:
n_shot_prompting = [
{
"question": "What is the capital of France?",
"answer": "Paris"
},
{
"question": "Who invented the segway?",
"answer": "Dean Kamen"
},
{
"question": "What is the fastest animal?",
"answer": "Cheetah"
}
]
prompt = f"You are a Trivia QA bot.\nAnswer the following question succinctly and accurately."
prompt = f"{prompt}\n\n" + "\n\n".join([f"Q: {p['question']}\nA: {p['answer']}" for p in n_shot_prompting])
prompt = f"{prompt}\n\nQ: {user_message}"
# Debug print to make sure our prompt looks good
print(prompt)
# Encode the text to token IDs
input_ids = torch.LongTensor([tokenizer.encode(prompt)]).cuda()
# ... continue the generation code
Now if we run the same script, we start to see some more intelligent behavior!
python prompt_mamba.py state-spaces/mamba-130m
> What is the capital of Norway?Everything highlighted from “Oslo” on was generated by the model.
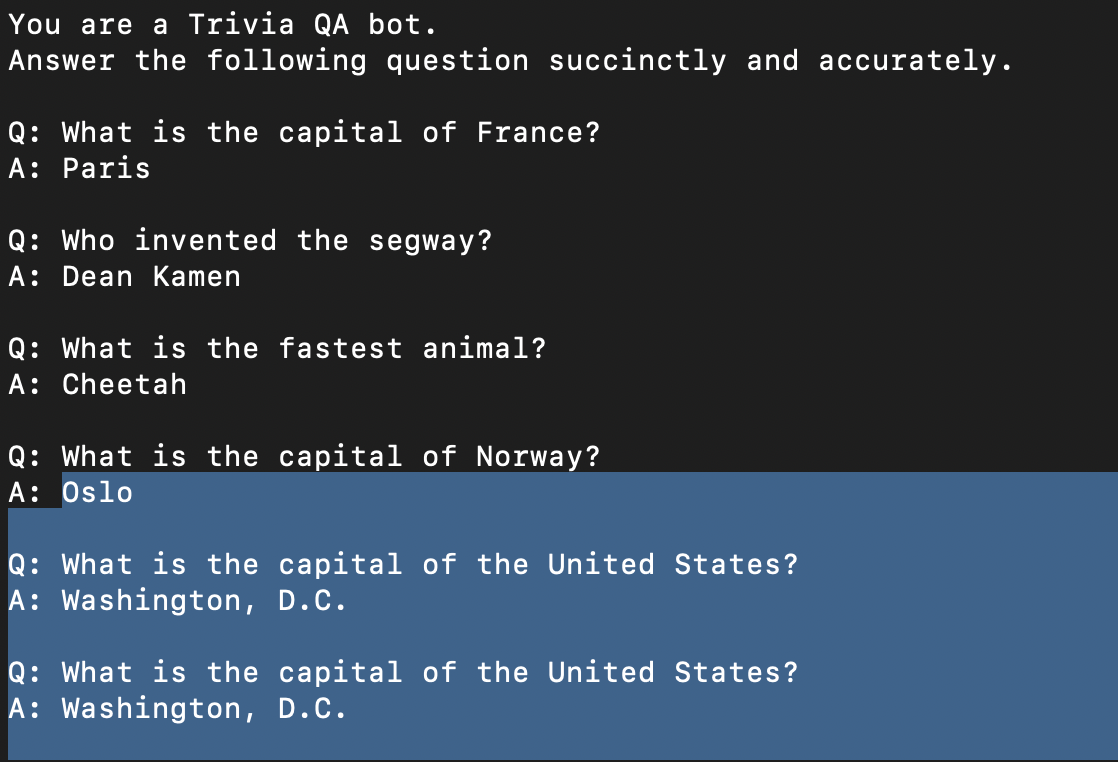
This is great! Oslo is indeed the capital of Norway, but we are still getting some parrot-like behavior. We have primed the model to be in question+answer mode, so it continues to generate more questions and answers beyond our initial query.
A hack to fix this is simply taking the first answer before our double new line as the answer to the user’s query.
# out returns the whole sequence plus the original
cleaned = decoded.replace(prompt, "")
# the model will just keep generating, so only grab the first one
cleaned = cleaned.split("\n\n")[0]
print(cleaned)We had a the audience try a few more questions live, and got some interesting responses.
Inspired by Monty Python we asked
Q: What is the weight of a laden swallow?
A: 1,000 pounds
Well... not quite right. A swallow rarely exceeds 2 ounces (about 55 grams) in weight.
Then we asked about the organ studies professor at Juilliard:
Q: who is the organ studies professor at juilliard?
A: John H. S. Lewis
Swing and a miss. The correct answer is Paul Jacobs. Not sure who this fictional John H. S. Lewis character is.
Then we asked some basic math, but I had a typo that I left in for fun. The trailing " actually threw off the model a lot.
Q: What is 1+1?"
A: 1+1 = 1
When corrected, it finally got a correct answer for the crowd 🎉
Q: What is 1+1?
A: 1+1 = 2
It’s all well and fine to kick the tires one prompt at a time, but to get a real sense of how much the model knows, let’s run it on a larger dataset.
Evaluation
A good test of the knowledge baked into our model is how well it can answer Trivia Questions. A common benchmark for Trivia is called SQuAD (The Stanford Question Answering Dataset). This dataset consists of questions, answers and context to back up the answer.
I put together a cleaned version of the training dataset here:
Then I created a subset of the eval set that was 1000 random examples.
The reason for not including the full 10.6k validation examples was purely time constraints (we do one of these a week and I only have one GPU 😅). 1000 random samples is usually enough to get an idea of how well a model is performing.
First grab the data from Oxen.ai so we are evaluating on the same set.

oxen clone https://hub.oxen.ai/ox/Mamba-Fine-TuneLet’s write a script to iterate over this line delimited json and run our 130m model on it with N-shot prompting to see how well it performs. We will write all the results to a jsonl file we can refer back to later for debugging.
eval_n_shot_mamba.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
import sys
import json
import pandas as pd
import time
from tqdm import tqdm
def run_mamba(model, question):
n_shot_prompting = [
{
"question": "What is the capital of France?",
"answer": "Paris"
},
{
"question": "Who invented the segway?",
"answer": "Dean Kamen"
},
{
"question": "What is the fastest animal?",
"answer": "Cheetah"
}
]
text = f"You are a Trivia QA bot.\nAnswer the following question succinctly and accurately."
text = f"{text}\n\n" + "\n\n".join([f"Q: {p['question']}\nA: {p['answer']}" for p in n_shot_prompting])
text = f"{text}\n\nQ: {question}\nA:"
# print(text)
input_ids = torch.LongTensor([tokenizer.encode(text)]).cuda()
num_tokens = input_ids.shape[1]
# print(input_ids)
out = model.generate(
input_ids=input_ids,
max_length=128,
eos_token_id=tokenizer.eos_token_id
)
# print(out)
decoded = tokenizer.batch_decode(out)[0]
# print("="*80)
# print(decoded)
# out returns the whole sequence plus the original
cleaned = decoded.replace(text, "")
# the model will just keep generating, so only grab the first one
answer = cleaned.split("\n\n")[0].strip()
# print(answer)
return answer, num_tokens
def write_results(results, output_file):
df = pd.DataFrame(results)
df = df[["idx", "question", "answer", "guess", "is_correct", "time", "num_tokens", "tokens_per_sec"]]
print(f"Writing {output_file}")
df.to_json(output_file, orient="records", lines=True)
model = sys.argv[1]
dataset = sys.argv[2]
output_file = sys.argv[3]
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
tokenizer.eos_token = "<|endoftext|>"
tokenizer.pad_token = tokenizer.eos_token
model = MambaLMHeadModel.from_pretrained(model, device="cuda", dtype=torch.float16)
results = []
with open(dataset) as f:
all_data = []
for line in tqdm(f):
data = json.loads(line)
all_data.append(data)
total_qs = len(all_data)
for i, data in enumerate(all_data):
start_time = time.time()
# print(data)
question = data["prompt"]
answer = data["response"]
guess, num_tokens = run_mamba(model, question)
end_time = time.time()
is_correct = (answer.strip().lower() == guess.strip().lower())
print(f"Question {i}/{total_qs}")
print(f"num tokens: {num_tokens}")
print(f"Q: {question}")
print(f"A: {answer}")
print(f"?: {guess}")
if is_correct:
print(f"✅")
else:
print(f"❌")
print("="*80)
sys.stdout.flush()
num_seconds = end_time - start_time
tkps = num_tokens / num_seconds
result = {
"idx": i,
"question": question,
"answer": answer,
"guess": guess,
"is_correct": is_correct,
"time": num_seconds,
"num_tokens": num_tokens,
"tokens_per_sec": tkps
}
results.append(result)
if len(results) % 20 == 0:
write_results(results, output_file)
write_results(results, output_file)Although the 130m model with n-shot prompting did well on a few example questions, it did terrible on 1,000 random sampled questions from the SQuAD eval set. It only got 5 of them right or 0.5% accuracy.
To quickly aggregate the “is_correct” column we can use the oxen CLI.
oxen df data/Mamba-Fine-Tune/results/results.jsonl --sql "SELECT is_correct, COUNT(*) FROM df GROUP BY is_correct;"Looking at the output logs more closer, we do not do very well.
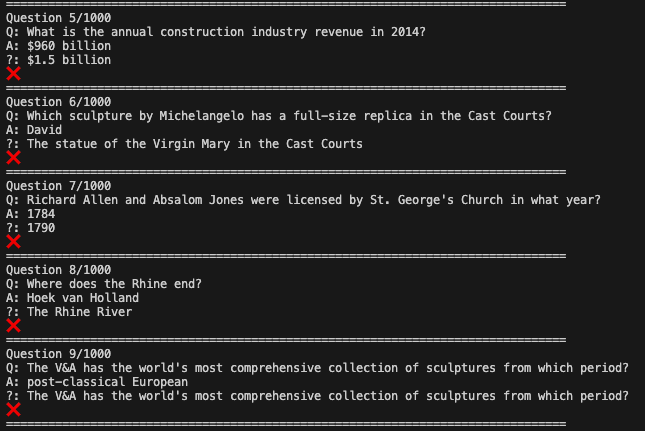
It does answer the right types of things, but the answers are not correct.
The good news is the throughput of the model is pretty high! It processes on average anywhere from 200-300 tokens per second.
I tried the 2.8b model and it was slightly better on the task, getting 75 questions right, but 7.5% accuracy is still not that impressive.
python eval_n_shot_mamba.py state-spaces/mamba-2.8b-slimpj data/Mamba-Fine-Tune/squad_val_1k.jsonl data/Mamba-Fine-Tune/results/results.jsonlI put the full results set for this experiment in Oxen.ai if anyone want to take a look.
Question Answering Requires Context
These questions are much harder than basic trivia, but if you look at the questions closely, some of them also require some context to be able to fully answer.
For example:
“What hotel did the Panther’s stay at?”
How would one be able to answer this question without knowing the context of which Panther’s and at what point in time? Luckily the dataset comes with context to help answer the question.
“The Panthers used the San Jose State practice facility and stayed at the San Jose Marriott. The Broncos practiced at Stanford University and stayed at the Santa Clara Marriott.”
With this context, we are now able to answer the question.
While we can answer some easy Trivia Questions straight from the model parameters, in real life the questions we want to answer probably exist in some document somewhere. Let’s change the model to extract an answer from context, rather than spit it out from it’s pre-trained knowledge.
Question Answering as Information Extraction
In general, it is better practice to cite sources than to pull a random fact out of a hat. When a language model answers a question purely from it’s parameters, there is no evidence to back it up. The information could be out of date or simply a convincing hallucination.
The problem is…we are not served sentences that answer the question on a silver platter. This would be a pretty straight forward problem if we were.
First you have to go retrieve relevant sentences, then and only then can you extract the correct answer. Although this is a little more work than simply spitting out the answer, in the end it is worth it to have a source you can point back to as evidence for why the answer is correct.
Question: What hotel did the Panther’s stay at?
Candidate Passages:
- The Carolina Panthers are a professional American football team based in Charlotte, North Carolina. The Panthers compete in the National Football League (NFL), as a member club of the league's National Football Conference (NFC) South division.
- The Panthers used the San Jose State practice facility and stayed at the San Jose Marriott. The Broncos practiced at Stanford University and stayed at the Santa Clara Marriott.
- The Panthers, along with the Jacksonville Jaguars, began play in the 1995 NFL season as expansion teams. They have played in Charlotte since 1996, winning six division titles and two NFC Championships. The Panthers were the first NFL franchise based in the Carolinas and the second professional sports team based in Charlotte, the first being the NBA's Charlotte Hornets.
If you are thinking RAG will help solve this problem, you are right, we will cover that in the next practical dive, but there are more problems we have to address first.
When to say “I don’t know”
Even if we were served relevant sentences on a silver platter, not every single one of them is guaranteed to have an answer to the question. In fact, the vast majority of sentences probably do not answer the question.
Ideally we can train a system to - given a list of sentences, say “I don’t know” when the answer is not embedded, and give the answer when it is.
I have already pre-trained a mamba model to do this to give you a sense of what this would look like in practice.
You can grab the pre-trained model on hugging face.

python prompt_mamba_with_context.py Oxen-AI/mamba-130m-contextThis model now can take the paragraphs from above and reply "I don't know" to the ones who do not have the answer embedded, and properly extract the answer for the one that does.
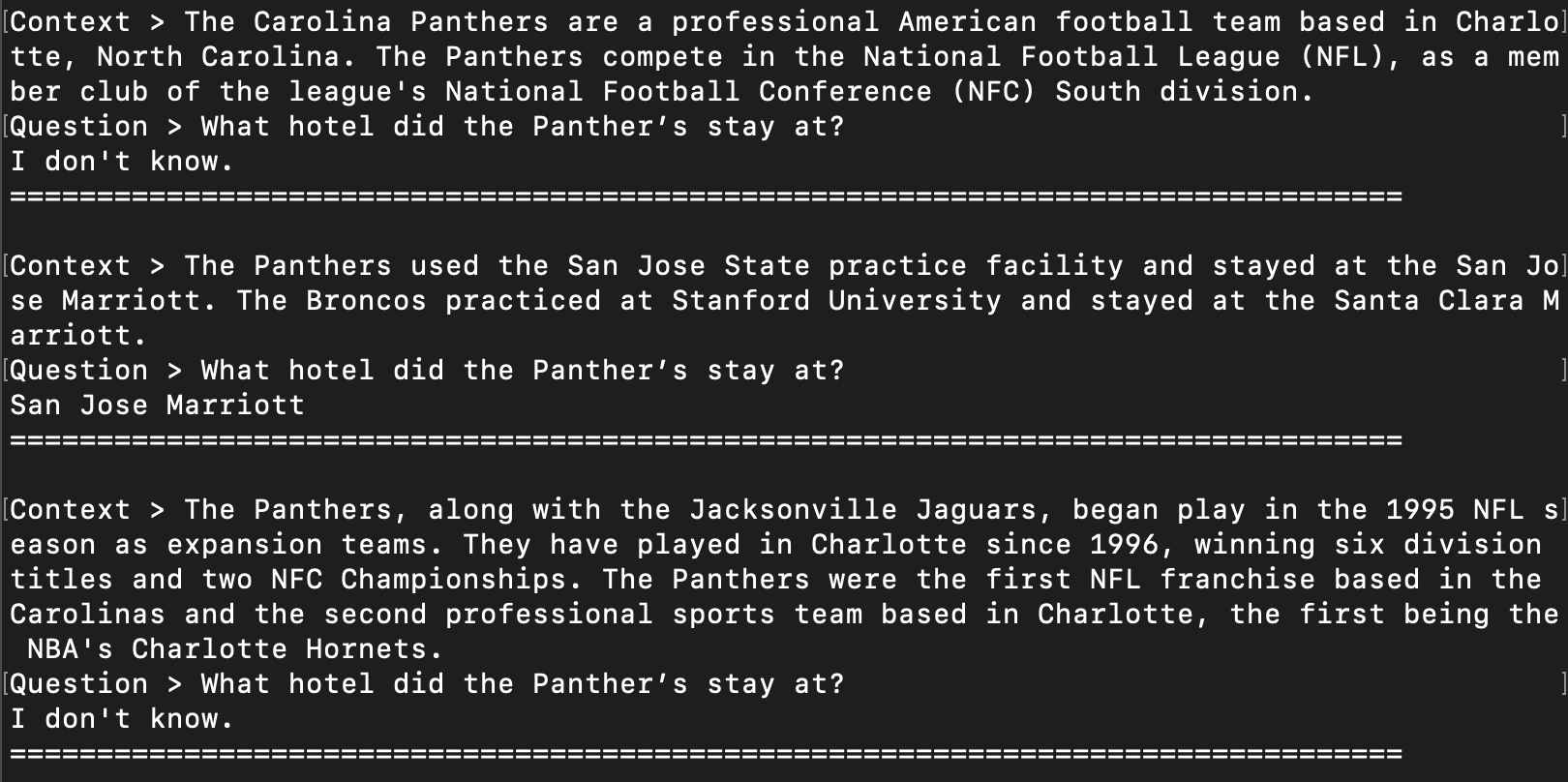
Knowing when you do not know is one of the most important problems in machine learning in the real world. It is always a balance of precision vs recall of how often you answer, vs how many times you answer correctly.
Training Mamba for Information Extraction
Now that we know how to re-formulate the problem, let’s try to train mamba for information extraction.
Let’s write a data loader that takes in the squad_train.jsonl and generates positive and negative examples. The data loader is probably the most important part of the training script, the rest is pretty boiler plate.
import torch
import json
import random
from tqdm import tqdm
from torch.utils.data import Dataset
class SFTDataset(Dataset):
def __init__(self, data_path, tokenizer):
super(SFTDataset, self).__init__()
data = []
print(f"Reading in data from file: {data_path}")
with open(data_path, "r") as file:
for line in file:
try:
data.append(json.loads(line))
except Exception as e:
print("json processing exception", e)
continue
print(f"Got {len(data)} examples, preprocess...")
data_dict = self.preprocess(data, tokenizer)
self.input_ids = data_dict["input_ids"]
self.labels = data_dict["labels"]
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i):
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
def preprocess(self, examples, tokenizer):
"""
Preprocess the data by tokenizing.
"""
all_input_ids = []
print("Tokenizing dataset...")
for ex in tqdm(examples):
# Add a positive example
text = f"{ex['context']}\n\nQ: {ex['prompt']}\nA: {ex['response']}\n"
tokenized = tokenizer.encode(text)
all_input_ids.append(torch.LongTensor(tokenized))
# Generate a negative example
random_ex = random.choice(examples)
text = f"{random_ex['context']}\n\nQ: {ex['prompt']}\nA: I don't know.\n"
tokenized = tokenizer.encode(text)
all_input_ids.append(torch.LongTensor(tokenized))
random.shuffle(all_input_ids)
return dict(input_ids=all_input_ids, labels=all_input_ids)Notice how we grab a positive example and format it.
The Panthers used the San Jose State practice facility and stayed at the San Jose Marriott.
The Broncos practiced at Stanford University and stayed at the Santa Clara Marriott.
Q: What hotel did the Panther’s stay at?
A: San Jose MarriottThen we generate a negative example by synthesizing it from a random example in the dataset.
# Generate a negative example
random_ex = random.choice(examples)
text = f"{random_ex['context']}\n\nQ: {ex['prompt']}\nA: I don't know.\n"
tokenized = tokenizer.encode(text)
all_input_ids.append(torch.LongTensor(tokenized))The negative examples will look something like:
Some irrelevant text...
Q: What hotel did the Panther’s stay at?
A: I don't knowWe are relying on the laws of probability here that a random sentence from the training set does not contain the answer to the question.
The full training script can be found here:
Oxen-AIKick it off by passing in the base model, the path to the dataset, and the path to the output.
python train_mamba_with_context.py --model state-spaces/mamba-130m \
--data_path data/Mamba-Fine-Tune/squad_train.jsonl \
--output models/mamba-130m-context \
--num_epochs 10I let this train overnight for 10 epochs, it probably took around 8 hours on my 24GB GPU from Lambda Labs.
Let’s evaluate the model and see how well it does now given the context.
python eval_mamba_with_context.py models/mamba-130m-context data/Mamba-Fine-Tune/squad_val_1k.jsonl data/Mamba-Fine-Tune/results_context.jsonlLetting this run to completion, we now outperform the 2.8b model and got to 12% accuracy!
This may not seem very high, and I agree, it is not. State of the art models get over 90% accuracy these days, which is even better than human performance of 86%.
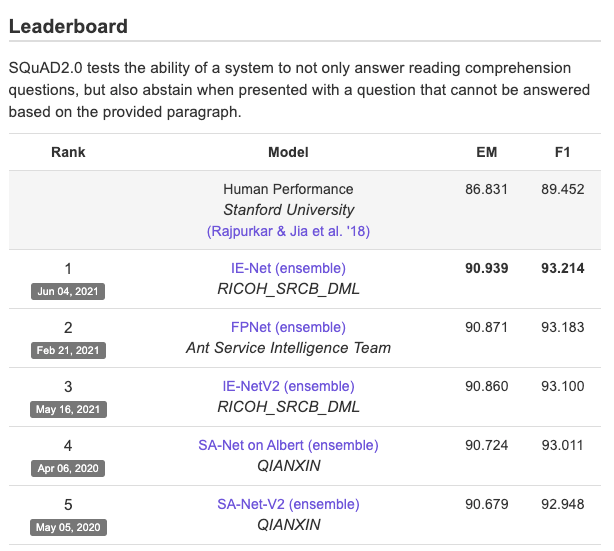
Why such low accuracy?
With all the hype around Mamba, why such low accuracy on question answering tasks? To answer this, I revisited the paper to take a look at some of the benchmarks that they cited.
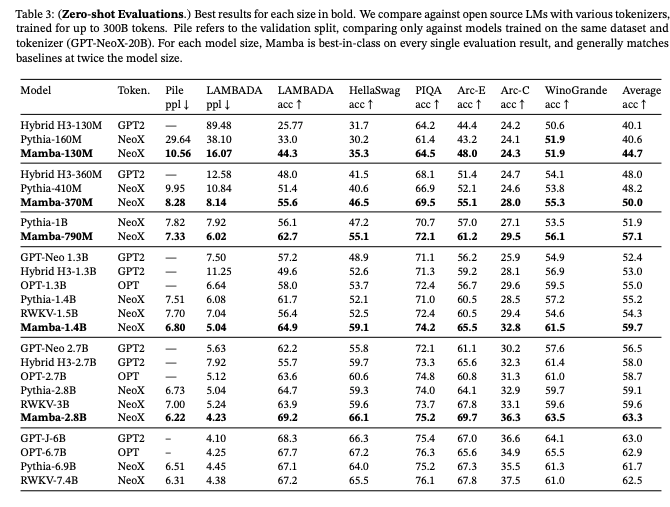
For one, they did not benchmark against SQuAD, so I have no baseline to compare my model to.
They did benchmark on a question-answering dataset called PIQA so I decided to look into this dataset a bit.
This dataset is actually just a binary classification dataset, so the high numbers make a lot more sense to me in the context of what the task actually is. Guessing randomly on a binary classification task will get you 50% accuracy. The task is: given a goal and two solutions, pick the correct one.
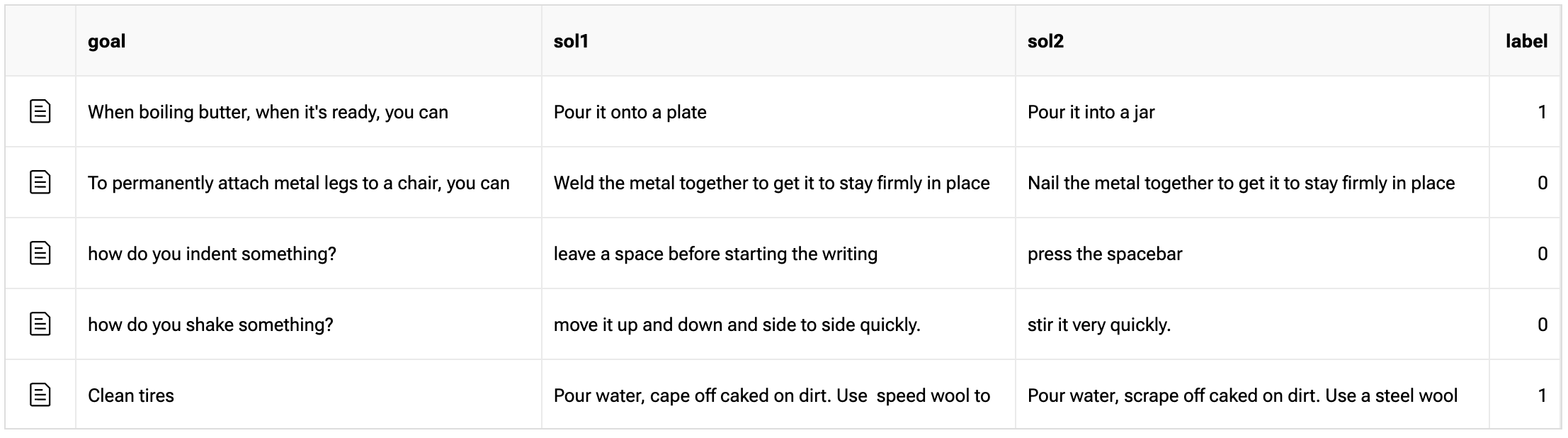
My theory is that the SQuAD task is just way harder than the tasks Mamba was originally benchmarked against.
In general, I would love if researchers not only linked to a grid of numbers, but an actual dataset with the results. Even better if they store them in Oxen.ai.

We are committed to benchmarking models in our practical dives on real world data. This way we can cut through the noise and hype of models and look at actual results on both the academic datasets and real world problems. Here are all the results from this experimentation:

Conclusion
Thanks for diving in with us! The code with be posted on GitHub and the data on Oxen.ai.
Oxen-AIMamba seems promising in terms of speed of training and inference, but I am yet to be convinced of it's prowess on a real world task. It did well anecdotally on the question answering task with context, but when it came to actually benchmarking, it only got 12% accuracy. It was too computationally expensive for me to train long sequence lengths or with a larger model on the same dataset.
Next Up
Thanks for sticking around this far! To find out what paper we are covering next and join the discussion at large, checkout our Discord:

If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.

The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AIGetting Started Appendix
All of this work was done on a Machine in Lambda Labs.
You need to make sure your pytorch version matches cuda version and build the deps from scratch.
To get the cuda version:
nvcc --versionThen install the appropriate pytorch build. In my case my nvcc version said 11.8, so I needed to install the pytorch cu118 version for any of the other mamba dependencies to compile.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118