Arxiv Dives - Efficient Streaming Language Models with Attention Sinks

This paper introduces the concept of an Attention Sink which helps Large Language Models (LLMs) maintain the coherence of text into the millions of tokens while also maintaining a finite memory footprint and latency.
Transformer based language models tend to break down in terms of text quality, latency, memory usage once they reach a certain context length. The paper introduces the concept of a StreamingLLM to solve all three of these issues.
Paper: https://arxiv.org/abs/2309.17453
Team: Massachusetts Institute of Technology, Meta AI, Carnegie Mellon University, NVIDIA
Publish Date: September 29th, 2023
Arxiv Dives
Every Friday at Oxen.ai we host a paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session presented by Arxiv Dive community member Daniel Varoli. Many thanks to the research he did preparing this dive for the group. Feel free to watch the video and follow along for the full context.
Why are StreamingLLM’s important?
Let’s start with a use case. Pretend you are building a chatbot. You pick LLama2-7B because it is open source and you can run it in your own infrastructure. You decide to run it without any modifications to get a baseline of performance.
Soon you get a beta user who starts using your chatbot. You observe the following behavior:
- The model gets slower as the conversation gets longer
- At some point the model starts outputting gibberish
- Eventually everything crashes and you don’t know why.
You remember you’ve read something about a “context window” limitation and realize that after 4096 tokens is just about when your model starts generating gibberish and just before it starts running out of memory.
You spin up a larger GPU to get rid of the out of memory errors, but still see the conversation slowing down, and eventually the model is outputting gibberish.
Why is this?
What is Context Length?
Transformer based Large Language Models tend to only be able to handle input of a certain context window. You may have seen this limit on the OpenAI GPT APIs or while playing around with Open Source models.
The context window is usually set at training, in order to keep the GPU memory usage and computational complexity under control. The vanilla self attention mechanism has the property of being O(N^2) with respect to the context length.
For example, GPT-2 had a context window of 1024 tokens, LLama-2 has a context winow of ~4k tokens, and GPT-4 has reached up to 32k tokens.
To relate these numbers to the real world - there are about 400 tokens in a single page in a book. So 4k tokens is about 10 pages of text.
This is not a hard limit on the model itself, but rather the fact that longer inputs can mean longer inference time, more GPU memory, and can affect your model’s perplexity or performance on language modeling tasks.
To see this in action, the GitHub repository that goes along with the paper has a great example video.
 mit-han-lab
mit-han-labOn the left and the right are two LLMs, one with Attention Sinks called the StreamingLLM, and one without. They both start by generating coherent text based on their training data.
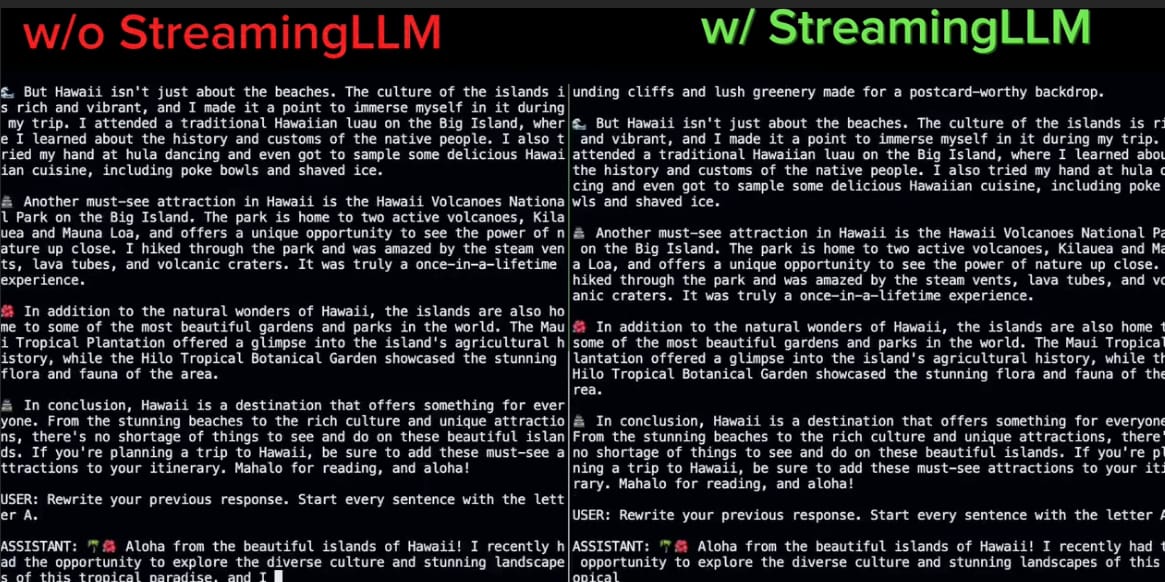
The problem is, once we hit a certain context length, the model without the StreamingLLM architecture starts slowing down as well as predicting text that is no longer coherent.

The model on the left starts spitting out random characters and patterns that no longer look like English. The StreamingLLM on the other hand continues to generate text that is readable and coherent.
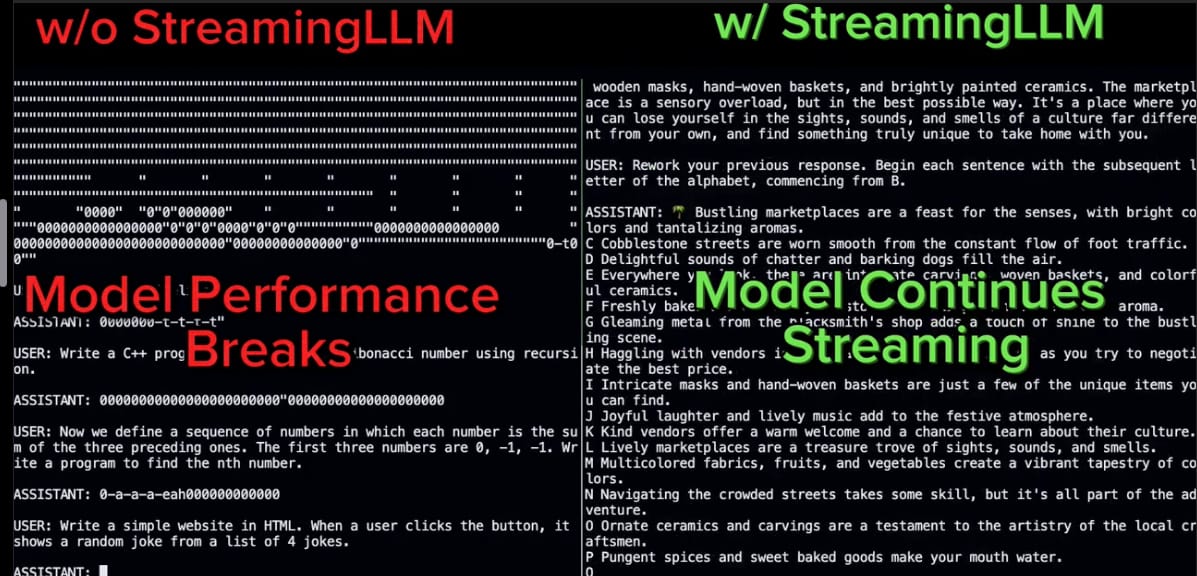
Not only this, at a certain point the model without the StreamingLLM will quickly run out of GPU memory.

What are we optimizing for?
Back to our chatbot example, we need to fix three things:
- The speed of our model on long sequences
- The memory usage of our model on long sequences
- The text quality generated after the training context window has been exceeded.
Important Note: While this paper does produce stable perplexity as a measure of text quality on long sequences, it does not enable the model to remember everything within that context window. Perplexity is simply “how well do we model the next word prediction”. Or “how perplexed is the model when it sees the actual word in the training data vs what it generated”. Lower perplexity is better, as the model is less perplexed. You can have a low perplexity while still not referring back to context earlier in the sequence. Long term reasoning and memory would be a fourth axes you could optimize for, but is not in the scope of this paper.
With that said, let’s start with optimizing the speed of the model on long sequences.
Key-Value (KV) Caching
Before diving into Attention Sinks, there is a concept known as KV Caching that has proven to solve the first one of our problems - speeding up the text generation.
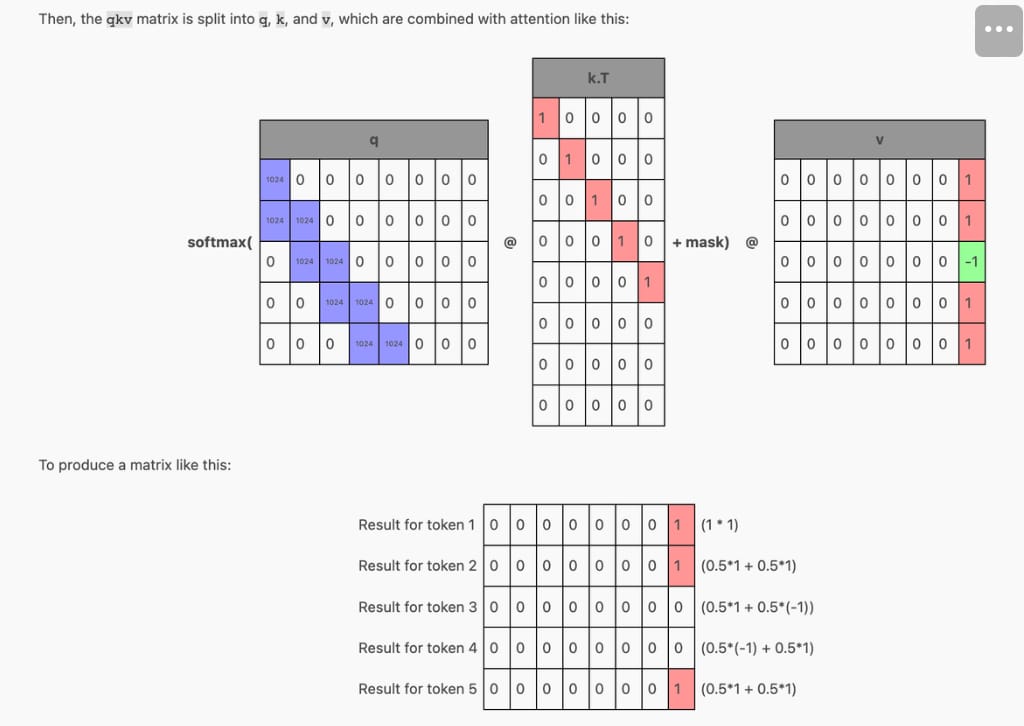
Transformer blocks within an LLM consist of three large matrices called the Key, Query, and Value matrices. These matrices require N^2 computation with respect to the sequence length in order for the model to look back all previous tokens generated.
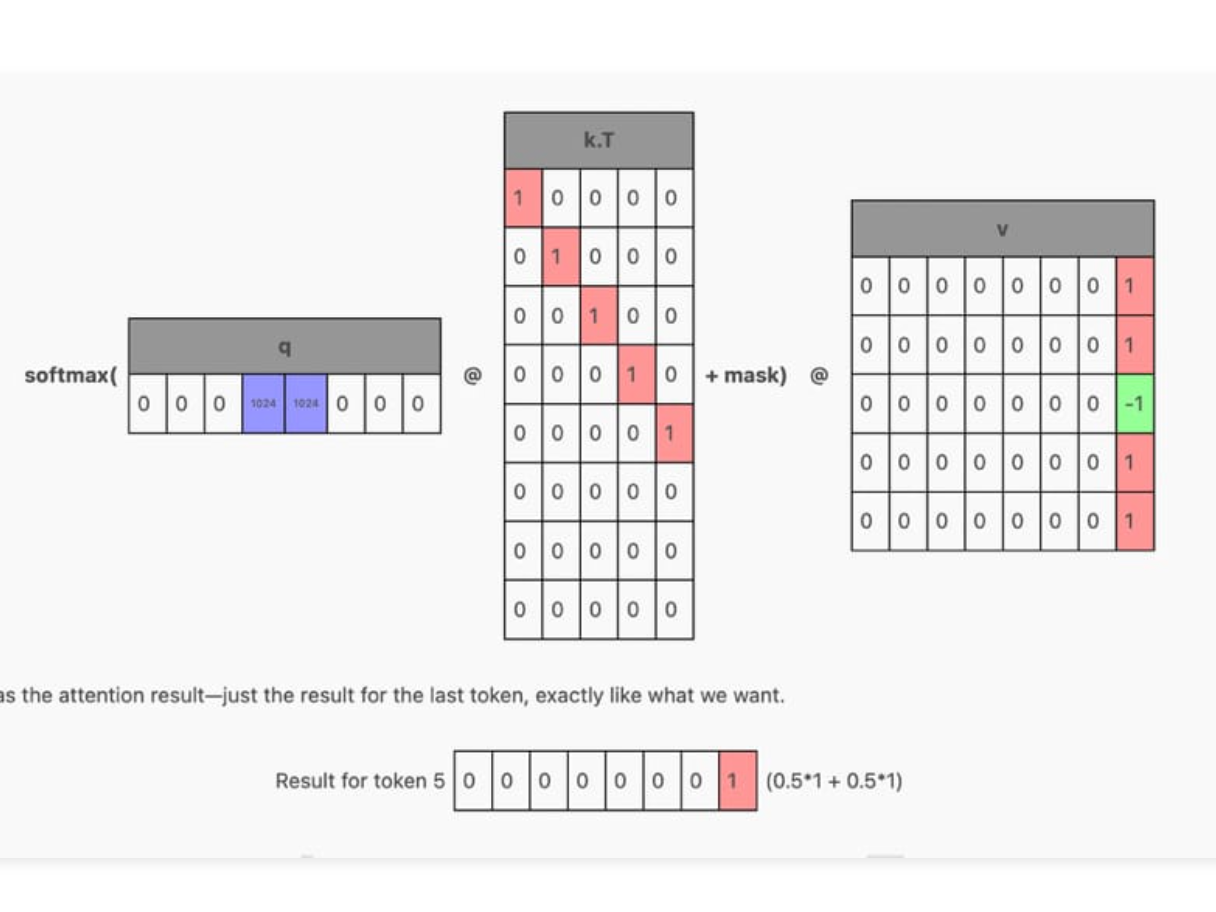
When generating a new token, it is important to note that the previous tokens all remain unchanged. Because of this property, we can cache the previously computed Key and Value matrices and apply them to only the last token position in the Queries.
In other words, instead of this:
We can do this:
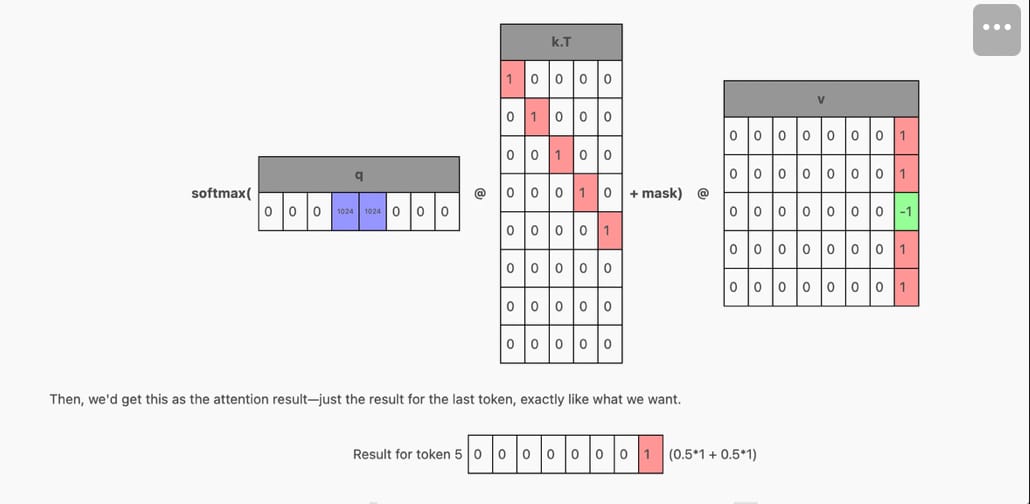
Then on the next generation, only a single token will be passed in, and the cached KV rows will be stacked on top of the K and V row for the new token to produce the single row Q and multi-row K and V that we want.
For more on KV Caching, feel free to read this blog post. If you have no idea what Keys, Values and Queries are within a transformer block, we have another deep dive into the Attention is All You Need paper that would be a good starting point.
KV Caching helps with speeding up the LLM, since we do not have to recompute everything for each new token. However now we have introduced a new variable of the size of the KV cache which will increase your memory usage with each generated token.
Efficient Streaming with Attention Sinks
Now that we have some context (pun intended) we can take a look at the core contribution of the paper.
We need our model to scale both in memory usage and speed, while maintaining perplexity (generating coherent text) all at the same time.
If you look at the Dense Attention mechanism in a vanilla transformer, you can see that we have poor computational complexity and high perplexity.
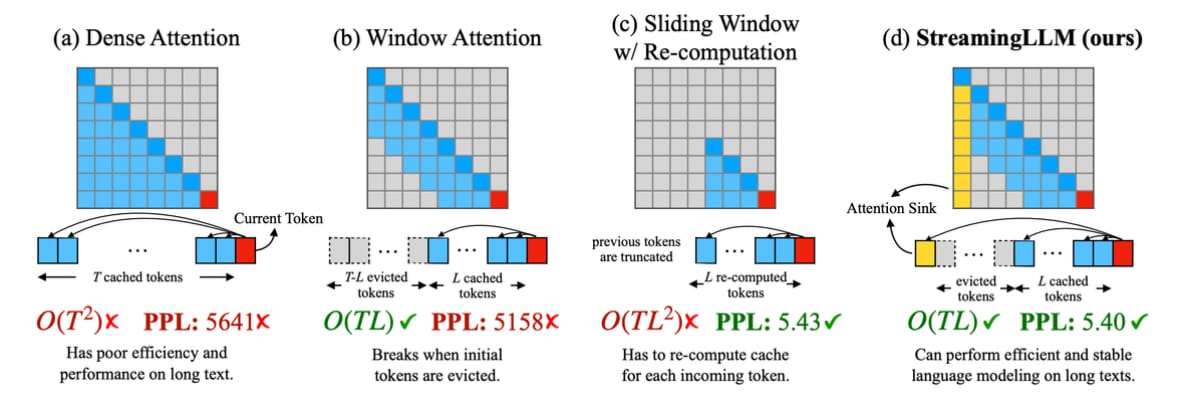
Techniques like sliding window attention improve computational complexity, but fall over in terms of perplexity after certain context lengths.
This paper introduced StreamingLLMs with special tokens that are used as “Attention Sinks” to give us the best of both worlds. It is both efficient and stable when generating text beyond the length of the trained context window.
What are Attention Sinks?
One of the things that the authors noticed in this paper is that methods that use the KV-Cache immediately spike in perplexity as soon as a the first entry is evicted from the KV-Cache. This suggests that these initial tokens are crucial for maintaining stability of the LLM.

After observing this spike in perplexity, they decided to look deeper into how the self attention mechanism was selecting the tokens to attend to.
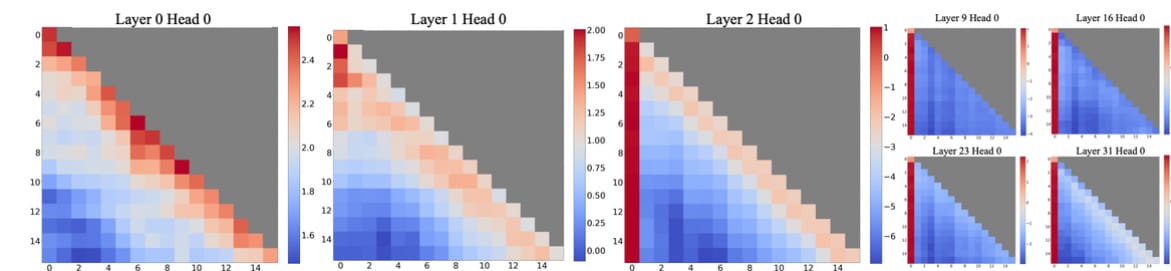
They noticed that the first few tokens accumulate a lot of the attention if you average it over the whole sequence. It seems that the model has learned a bias towards the absolute positions of these tokens during training, since they are always there while generating. If you evict them from the cache - this is where the model starts to go haywire.
This leads to the intuition that if we keep these first few tokens around, maybe the model’s performance will not degrade. Keeping the first few tokens in the KV-Cache is exactly what they decide to do, and they call this technique an “Attention Sink”.

The KV Cache typically has a fixed size to maintain memory consumption while increasing speed, so you have to evict the first tokens once the sequence reaches a certain length.
The big reveal: with an “Attention Sink”, you can simply evict the 4th, 5th, 6th, token etc while keeping the first N tokens within the cache. Now the model can dump its “excess attention” to the first N tokens, and not be “surprised” when they are evicted.
This simple trick leads to stability in the generation as we go forward, and is a bit shocking that it works at all. While it does improve language modeling stability, it does still evict tokens from the cache so it does not improve the model’s ability to reason about long sequences of text.
What’s cool about this technique is that you do not have to retrain the model at all to get these results. You simply have to change how the KV-Cache is updated.
Why does the model learn these mechanics?
There is a great blogpost that illustrates why this behavior may emerge at all.

The TLDR is that within the Self Attention Mechanism the model has a SoftMax that‘s job is to choose which tokens to attend to.

One property of the SoftMax is that something always has to be picked. The probability density accumulates to 1, and the model has learned that the first token is a good default to dump it’s “extra attention” on.
This feels like an odd feature of the Transformer in general, but the fact is: adding attention sinks works. Future research may come up with a less hacky solution that builds this sort of bias into the model itself.
Results on Perplexity
They measure the perplexity of 4 different approaches to attention with a few different LLMs.

As you can see, the perplexity stays consistent with respect to sequence length with the StreamingLLM while it immediate spikes with techniques such as sliding window attention.
They performed language modeling on a concatenated test set of 100 books (which is 4 million tokens!) and saw the model maintained stable perplexity as well.

Not only does the perplexity stay stable, the latency and memory usage of the StreamingLLM are also much more optimal.

What if we trained a model with a sink token?
So far we have not even trained a model. It has simply been a matter of changing how we evict tokens from the KV-Cache.
The authors decide to run experiments on pre-training a model with an explicit “sink token” and prepending this token to all the training examples fed into the model.
In the “vanilla” setting without pre-training we need 4 sink tokens to recover perplexity. They train a 160 parameter model and show that by adding the sink token to the pre-training, 1 sink token is sufficient.
More details of the pre-training experiment are in the paper, but it is interesting that if you explicitly give the model capacity to dump it’s attention to a sink token, it will learn to use it.
Conclusion
The StreamingLLM is an interesting finding and essential research into fixing model behavior after they extend beyond their trained context window. It produces stable text while maintaining latency and low memory consumption.
The StreamingLLM does not necessarily mean the model will remember everything in its past, or be able to reason about long sequences of text. This is because we are still evicting tokens from the KV Cache. Understanding how the KV Cache works, and what eviction policy is optimal can help us design models to be more effective in the future.
This is a nice trick to get your models to work with long sequences in production, and a great jumping off point for future research.
We had a great discussion live and thank you to our guest presenter Daniel Varoli from Zapata.ai for putting together the research and presentation!
Next Up
To find out what paper we are covering next and join the discussion at large, checkout our Discord 👇

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI