Why GRPO is Important and How it Works

Last week on Arxiv Dives we dug into research behind DeepSeek-R1, and uncovered that one of the techniques they use in the their training pipeline is called Group Relative Policy Optimization (GRPO).
At it’s core, GRPO is a Reinforcement Learning (RL) algorithm that is aimed at improving the model’s reasoning ability. It was first introduced in their paper DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, but was also used in the post-training of DeepSeek-R1.
The process to go from DeepSeek’s base pre-trained language model to a reasoning model was laid out in detail in the DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning paper.
Last week we didn’t get too deep into the math or process behind GRPO or look at any code, so today the goal is to fully understand what is going on in GRPO and help apply it to your own work.
Recap: How R1 Used GRPO
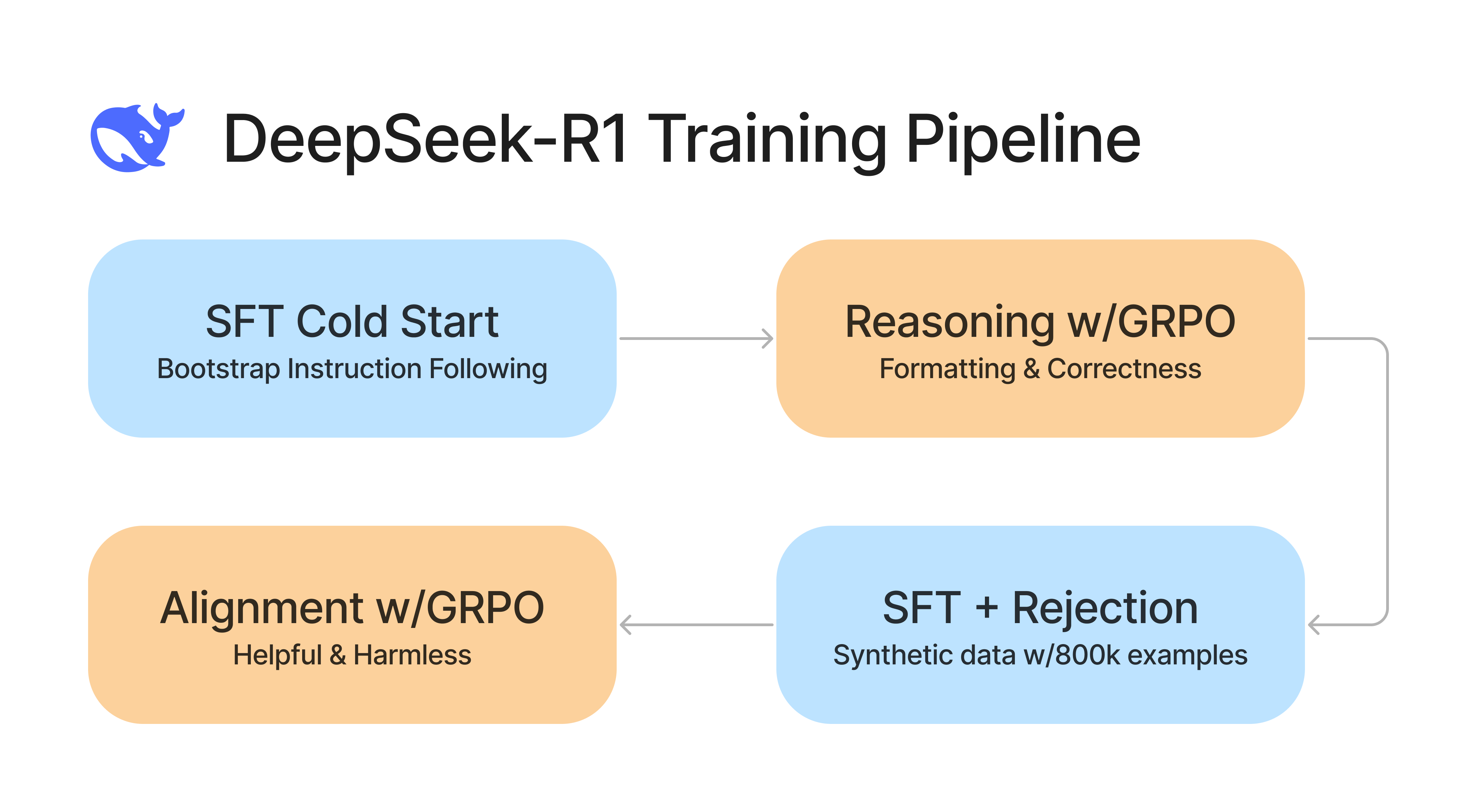
As a recap - the full pipeline for improving DeepSeek’s base model to the reasoning model alternates between using Supervised Fine Tuning (SFT) and Group Relative Policy Optimization (GRPO).
- Supervised Fine Tuning (SFT)
- Cold start the training with high quality data
- A couple thousand examples verified by humans
- Reinforcement Learning w/ GRPO
- Train the model to have reasoning traces <reasoning></reasoning>
- Deterministic rewards for formatting, consistency, and correctness
- Supervised Fine Tuning (SFT)
- Generate 800k Synthetic SFT data points and reject and filter
- LLM As A Judge to filter incorrect responses
- Reinforcement Learning w/ GRPO
- Align the model to be helpful and harmless
In this post we will dive into the details of GRPO to give you a sense of how it works and where you can apply it to training your own models. I’ve been doing some experiments training smaller models with GRPO and will follow up with a post on implementation details and code examples to help tie together all the concepts.
Why is GRPO Important?
TLDR ~ The compute requirements drop significantly and it simplifies the RL. It just about cuts in half the compute requirements to do Reinforcement Learning from Human Feedback (RLHF) compared to what was used for ChatGPT (PPO). When you start considering LoRAs in the mix, this unlocks RL training for even the poorest of the GPU poor, and I got news for you. I tried it. And it works. I was able to successfully turn a 1B parameter Llama 3.2 model into a reasoning model with 16GB of VRAM. More on that in a subsequent post where I’ll share the code and hardware requirements.
💡 I was able to successfully turn a 1B parameter Llama 3.2 model into a reasoning model with 16GB of VRAM.
Basically we can all train reasoning models from our garages by spending < $100 on cloud GPU services. Or essentially “for free” if you are talking smol models on your own hardware. How does this work in under the hood? The next section will talk through the evolution from PPO to GRPO.
From PPO to GRPO
The Reinforcement Learning (RL) technique behind ChatGPT is rumored to be PPO which stands from Proximal Policy Optimization. The process was laid out in the InstructGPT paper to create a model that can follow instructions and go beyond simple predicting the next word.
The training process requires you to collect a lot of labeled data. For a given user query, you have the model generate multiple candidate responses. Then you have a human or AI in the loop to label and rank the outputs form best to worst. This can then be used as training data for a “reward model” who’s job is to calculate a “reward” for a new prompt that it sees. The reward should represent how good this response is, given the user query.
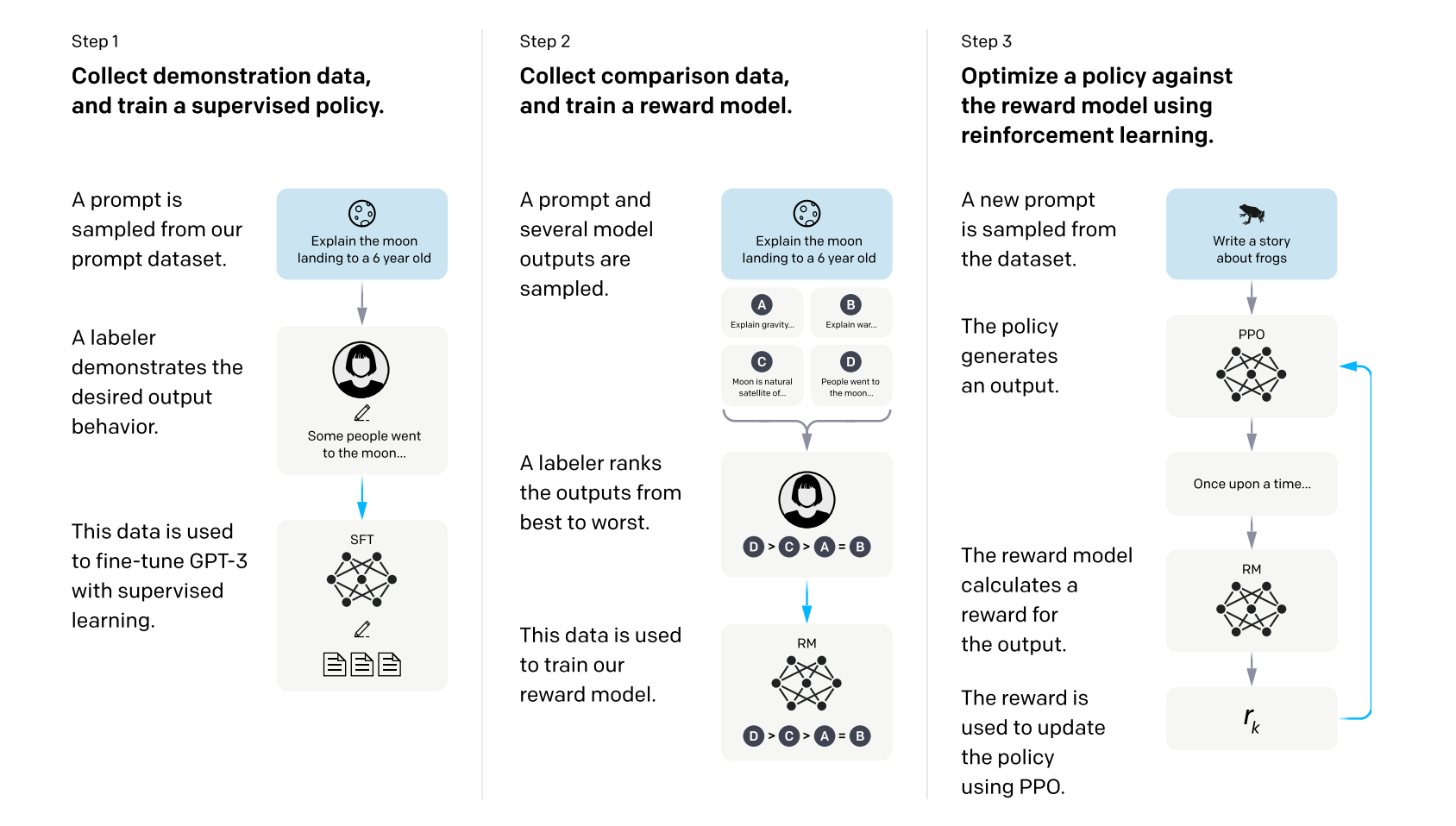
After you have collected all this ranked and labeled data you can kick off PPO to train your LLM.
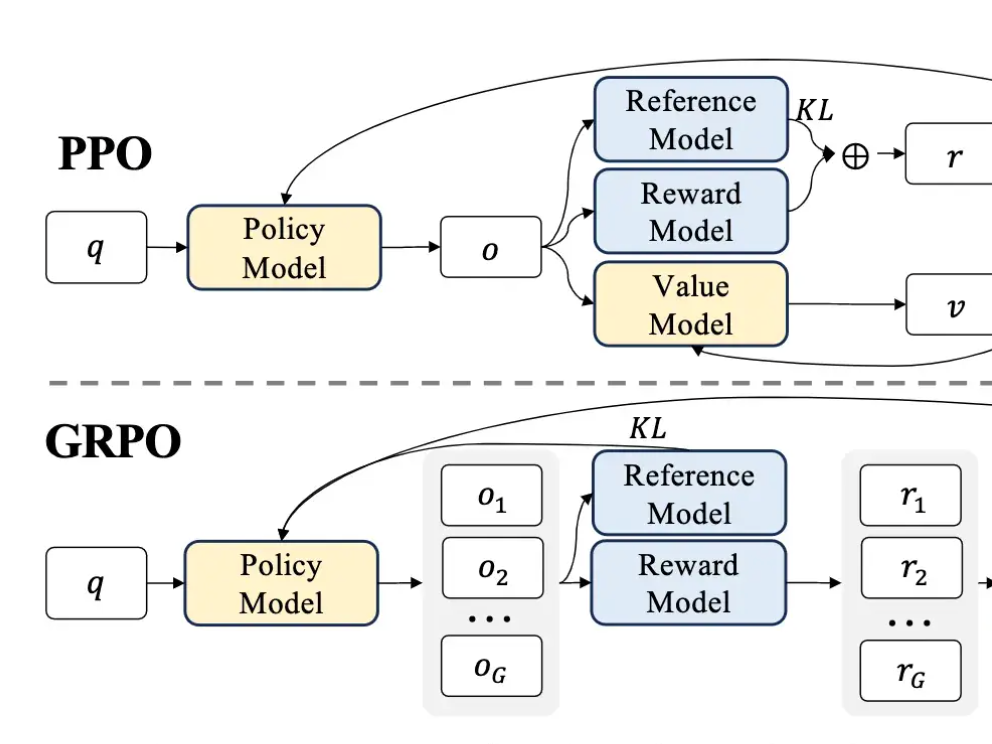
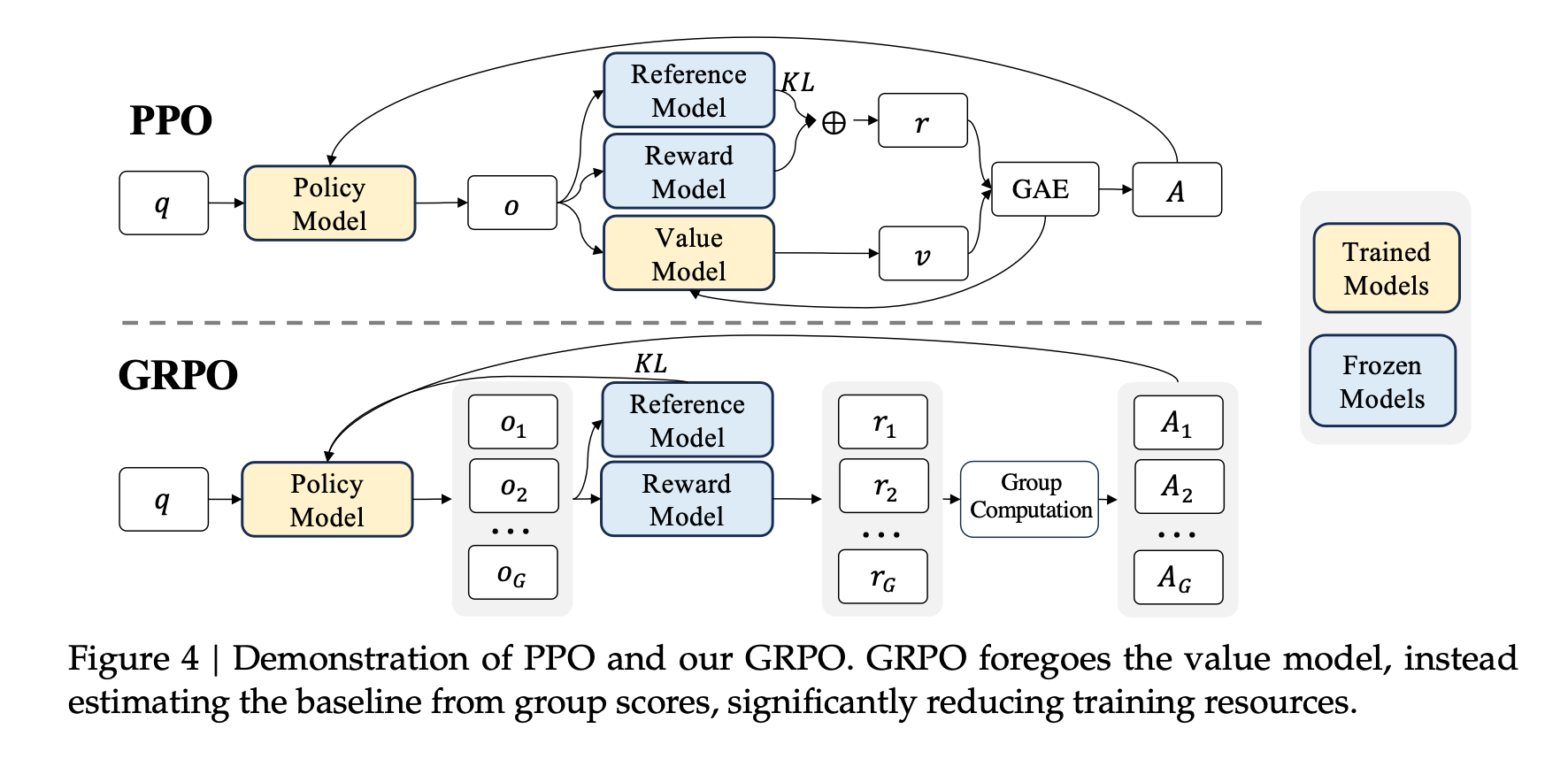
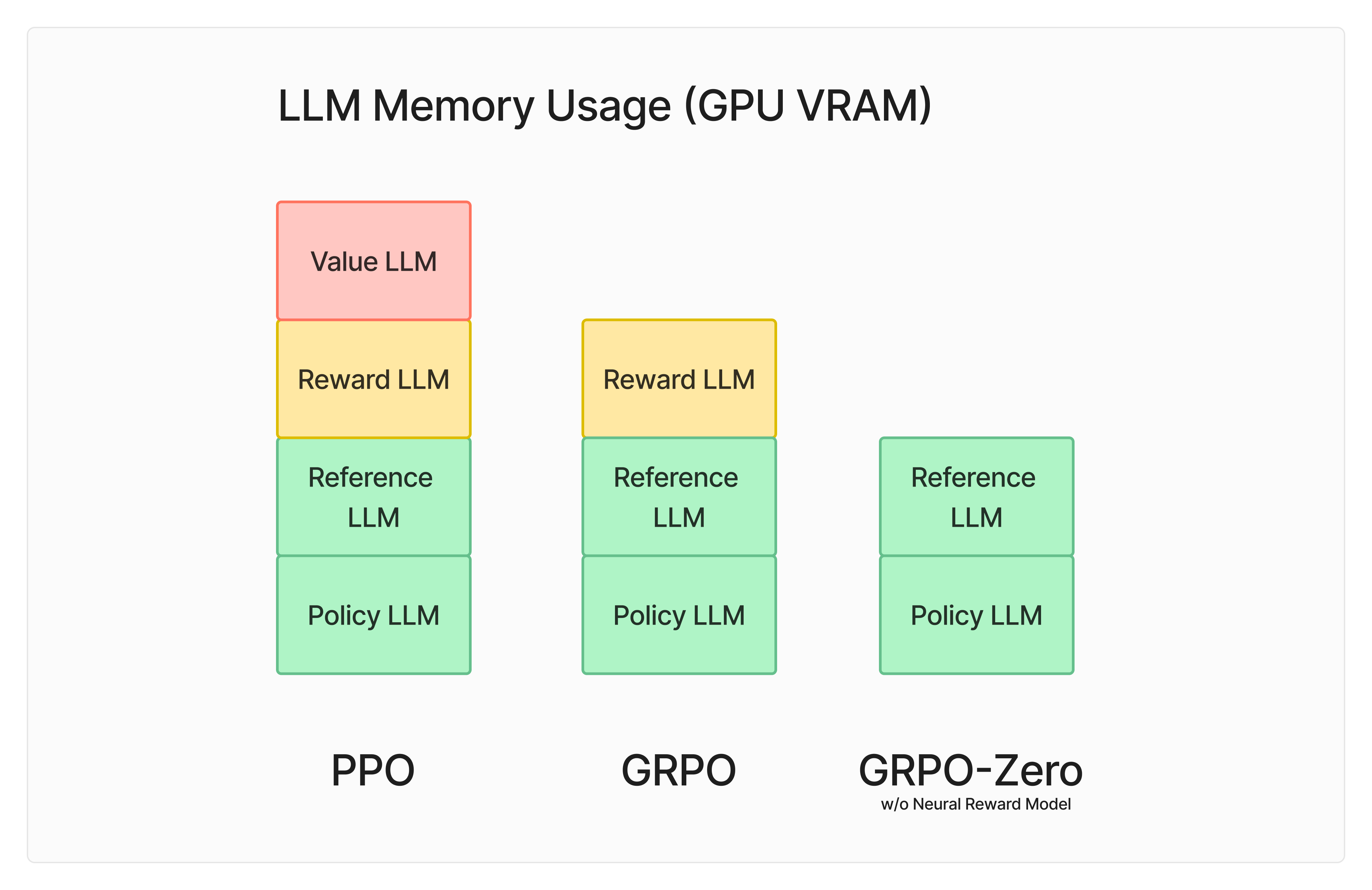
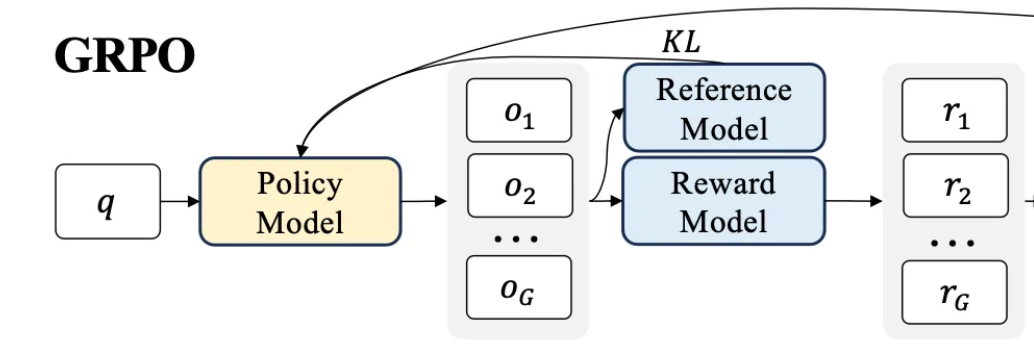
The problem is that PPO can be pretty expensive to train. The diagram from the GRPO paper shows all the different LLMs that are in the mix during PPO and GRPO. There are 4 different LLMs in the blue and yellow boxes below.
To help demystify some of the lingo above, here are my quick definitions:
- Policy Model - Fancy name for the current LLM you are training
- Reference Model - A frozen version of the original LLM you are training
- Reward Model - The model that was trained on human preferences (from the technique in InstructGPT above)
- Value Model - A model that is trying to estimate the long term reward given certain actions
Reducing Memory Usage with GRPO
In PPO both the policy model and the value model have trainable parameters that need to be back-propagated through. Backprop requires a significant amount of memory. If you look at the diagram above, GRPO drops the value model.

PPO has 4 LLMs in the mix, which all require substantial memory and compute. The value and reward models are typically of a comparable parameter count to the LLM you are training. The reference model is usually a frozen copy of the initial language model.
Not only is this computationally expensive, there are a lot of moving parts and multiple models you are optimizing. The more moving parts, typically the harder it is to optimize. GRPO helps simplify things.
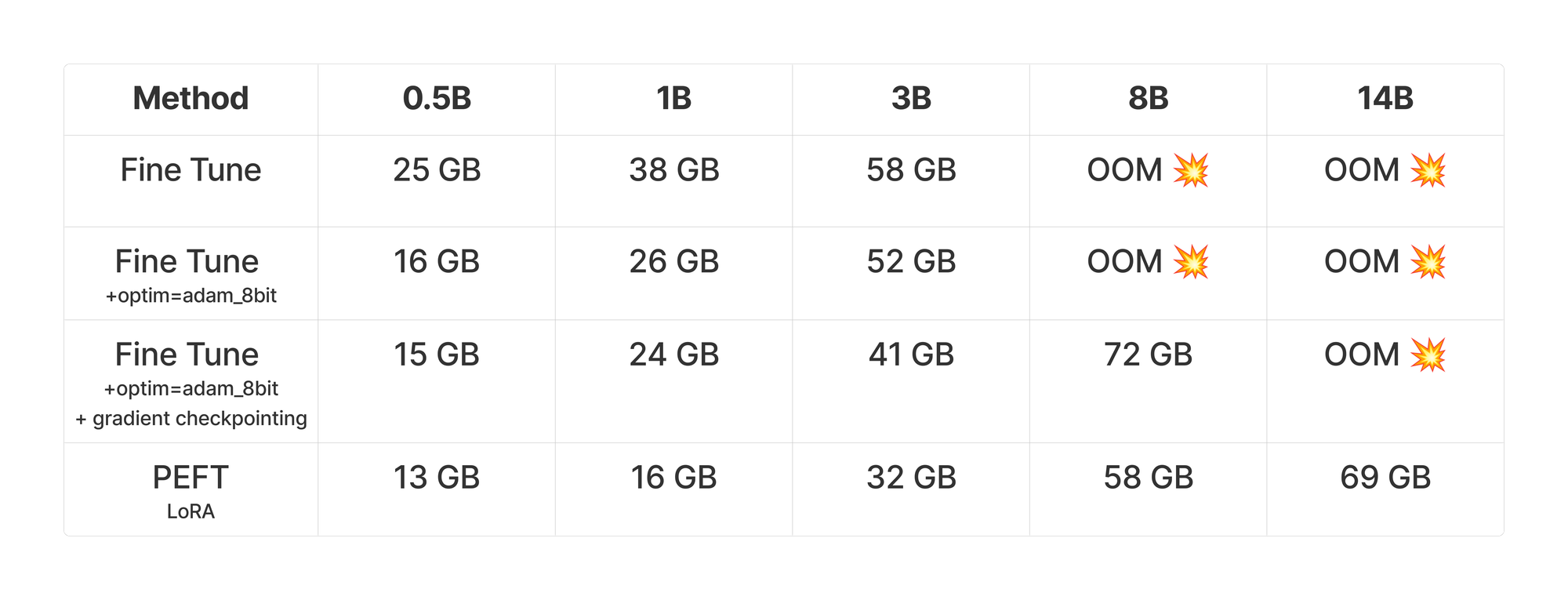
For fun, I decided to try a bunch of different model sizes on an H100 and see how easy it was to fine tune with GRPO
If you want all the technical details check them out here:

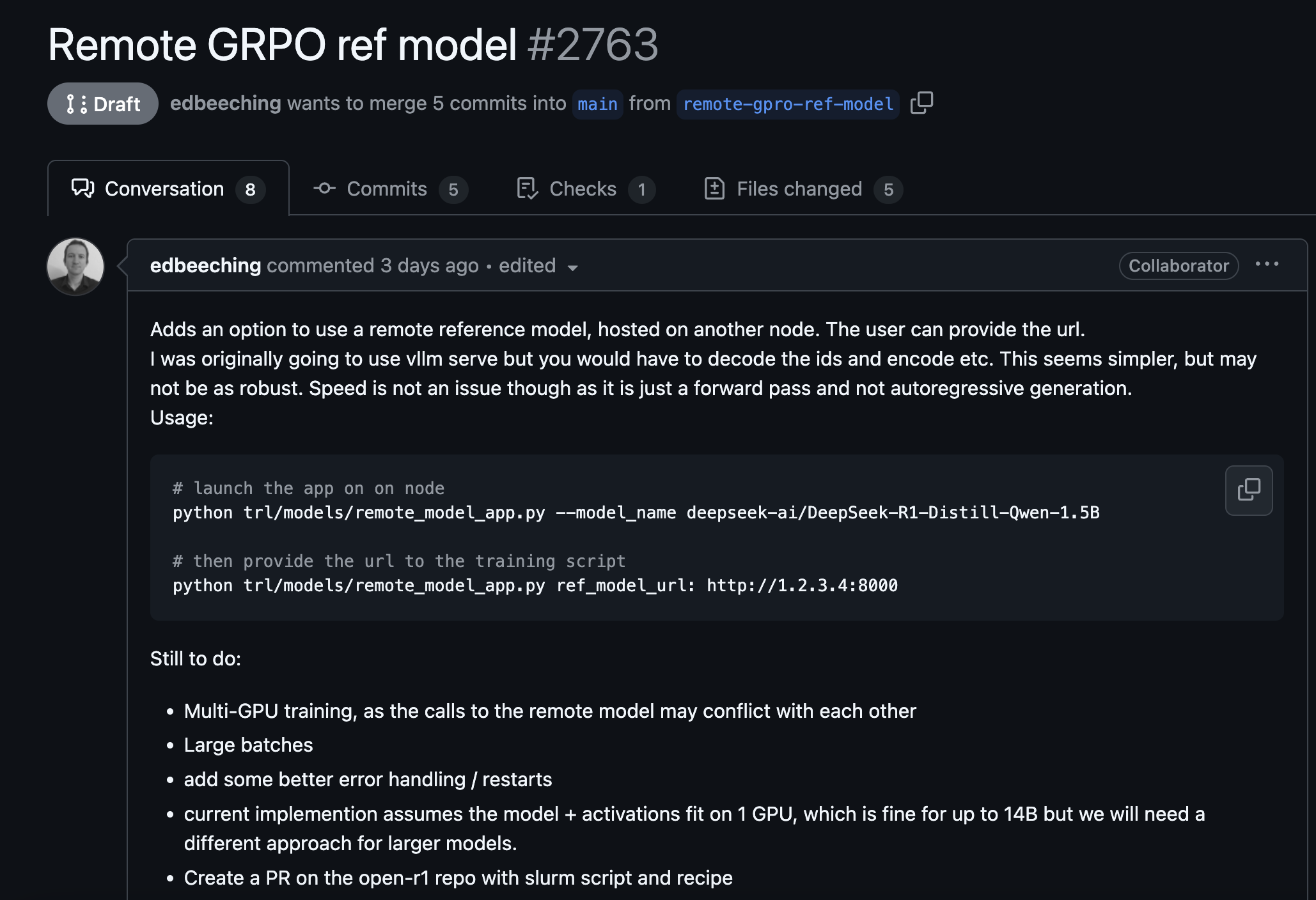
If you understand where all the system requirements comes from, you can start to contribute to open source or help optimize your own libraries like this most recent PR I saw on the trl repo:
Group Relative Advantages
The main signal you are trying to get out of your LLMs during RL is represented by “A” which stands for the “Advantage”. This helps give direction to update the original LLM’s weights. If the the advantage is high, you want to encourage the model to keep doing the same actions. If it is low, you want to encourage the model to try something different.
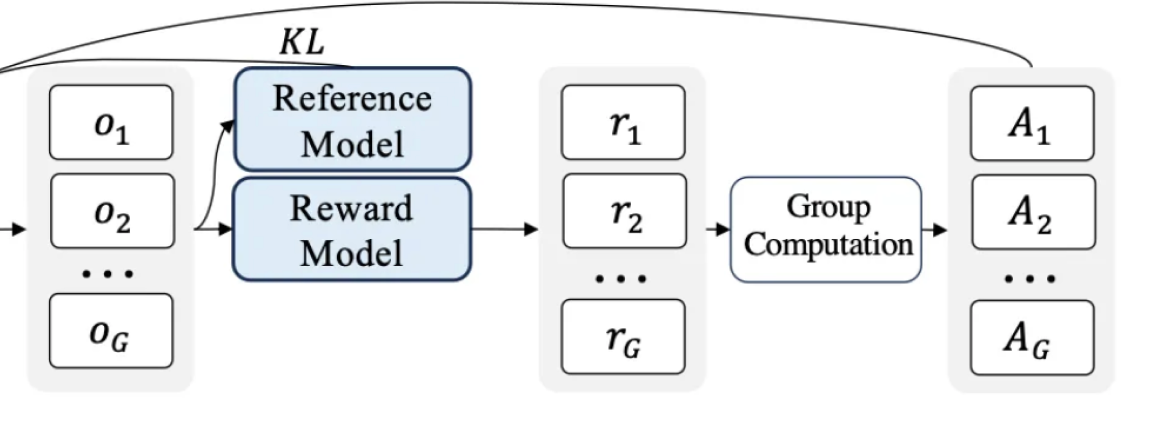
In PPO, the value model’s original job is to try to estimate how good the tokens that are generated are, or how likely they are to give a high reward. In order to do this well, it required you to train large LLM to make these value judgements. So how does GRPO remove the need for this?
The first trick is that instead of generating one output per query, GRPO starts by generating multiple outputs.
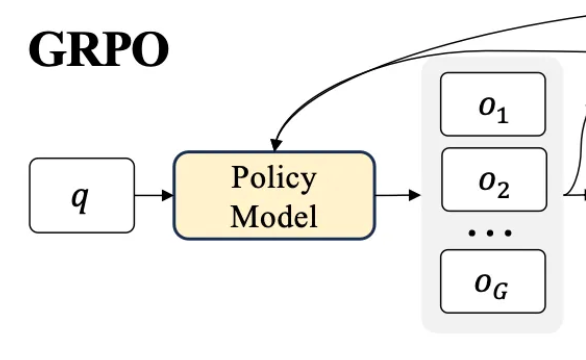
Concretely if the question is a math question the model might try a few different approaches to solve it. For example, if the question is:
Mr. Curtis has 325 chickens on his farm where 28 are roosters and the rest are hens. Twenty hens do not lay eggs while the rest of the hens do. How many egg-laying hens does Mr. Curtis have on his farm?
The model might come up with a few different reasoning traces, some correct (answer=227), and some incorrect (answer=305).

Correct Output
<reasoning>First, let's find out how many hens there are. The total number of chickens is 325, and 28 are roosters. So, the number of hens is 325 - 28 = 297. Of these 297 hens, 20 do not lay eggs, so the number of egg-laying hens is 297 - 20 = 277.</reasoning>
<answer>277</answer>
Incorrect Output
<reasoning>You need to subtract the 20 hens that do not lay eggs from the total number of hens to find the number of egg-laying hens. So, the number of egg-laying hens is 325 - 20 = 305.</reasoning>
<answer>305</answer>
Then for each output, we calculate a “reward” for how well that output answers the query. There can be multiple reward functions that evaluate different properties of the response. We will leave the reward functions as a black box for now, but just know that they return some numeric value that is higher if the response is good, and lower if the response is bad.
Rewards may look like:
- Formatting = 1.0
- Answer = 0.0
- Consistency = 0.5
Once we have our set of rewards (r) given our outputs, GRPO calculates our “advantage” (A) by simply looking at the mean and standard deviation of all the rewards.
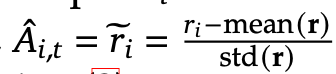
This equation is pretty handy for feature engineering in machine learning in general. It helps normalize arbitrary values to more a more learnable positive or negative signal. The intuition is “how many standard deviations from the mean is the data point?”
Let’s look at some examples.
# o_0 = <reasoning>I have some reasoning</reasoning><answer>12</answer>
r_0 = 1.0
# o_1 = <reasoning></reasoning><answer>12</answer>
r_1 = 0.5
# o_2 = The answer is 312
r_2 = 0.0
# o_3 = <reason>I did not have valid formatting or answer.
r_3 = 0.0
In raw numpy it would look something like this:
import numpy as np
advantages = [(r_i - np.mean(r)) / np.std(r) for r_i in r]
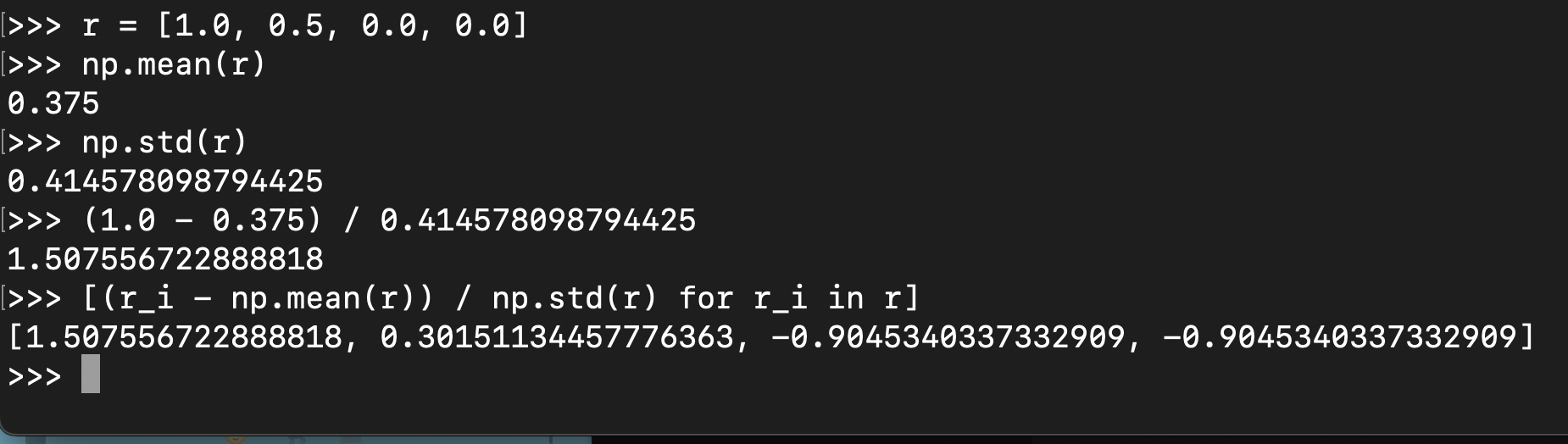
Let’s try it with another set of numbers:
rewards = [4.0, 2.5, 0.5, 0.1]
advantage = [(r_i - np.mean(r)) / np.std(r) for r_i in r]
[1.4137674241360643, 0.4606657898870322, -0.8101363891116772, -1.064296824911419]
You’ll notice the values center around 0.0 and tell you how good or bad the score is relative to all the other ones. This gives us a sort of baseline of “given this prompt, how good are the average responses going to be?”. Reward the good outputs, and penalize the bad ones in this batch.
This is pretty similar to what the value model was originally trying to do: estimate what our reward will be given a response. Since the policy model we are training is a language model, we can just tweak the temperature and have generate multiple possible completions instead. Then the average reward for all these generations is a good signal for how well the current model is doing, and if we should reinforce the behavior.
KL-Divergence
The final piece of the equation is the KL Divergence term.
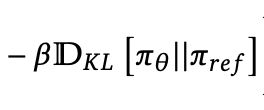
Without getting too deep into the math, this is why we have been keeping around a “reference model” during the training. The idea is that we do not want to drift too far from the original model. For each token, we want to make sure the new predictions do not drift too far from the original ones.
The intuition behind enforcing the KL Divergence is that the model we are starting with already knows how to write coherent sentences and follow instructions. We don’t want the new model to “reward hack” or exploit some sort of property in our reward signal that is not aligned with the original model. If it finds out that saying the word “pamplemousse” gets a high reward because it is a rarer word (and fun one to say) we don’t want it latching onto this behavior if it was not common in the pre-training.
Put all this together and you have this final equation!
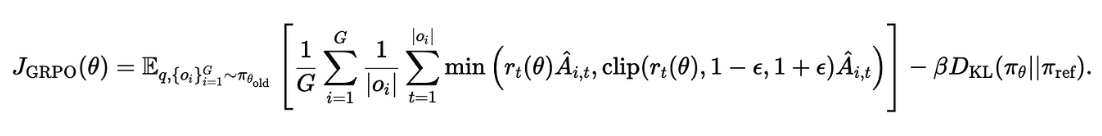
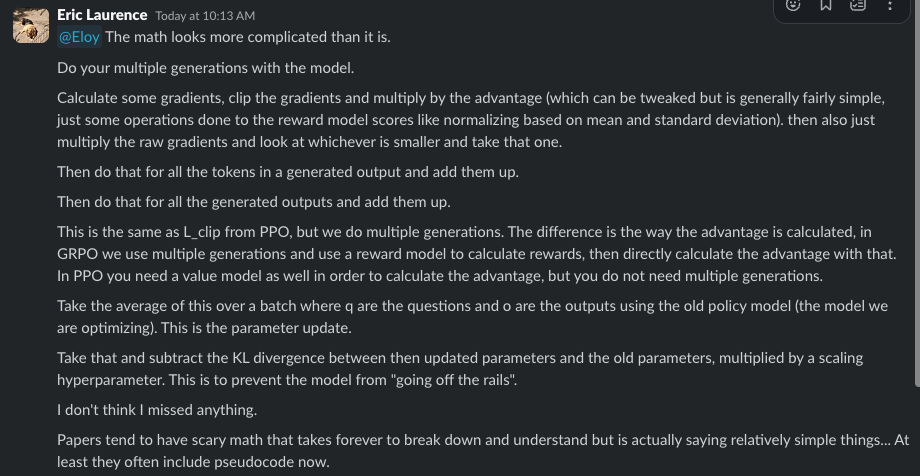
Or as our trusty Ox Eric says…The math looks more complicated than it is…
The Reward Signals
What’s super interesting about the DeepSeek-R1-Zero work is that they go even further to slash the memory usage because don’t use a “neural reward model”.

What does this mean? It means they are literally using regexes and string matching for reward signals. They argue that this helps with “reward hacking” and simplifies the whole training pipeline.
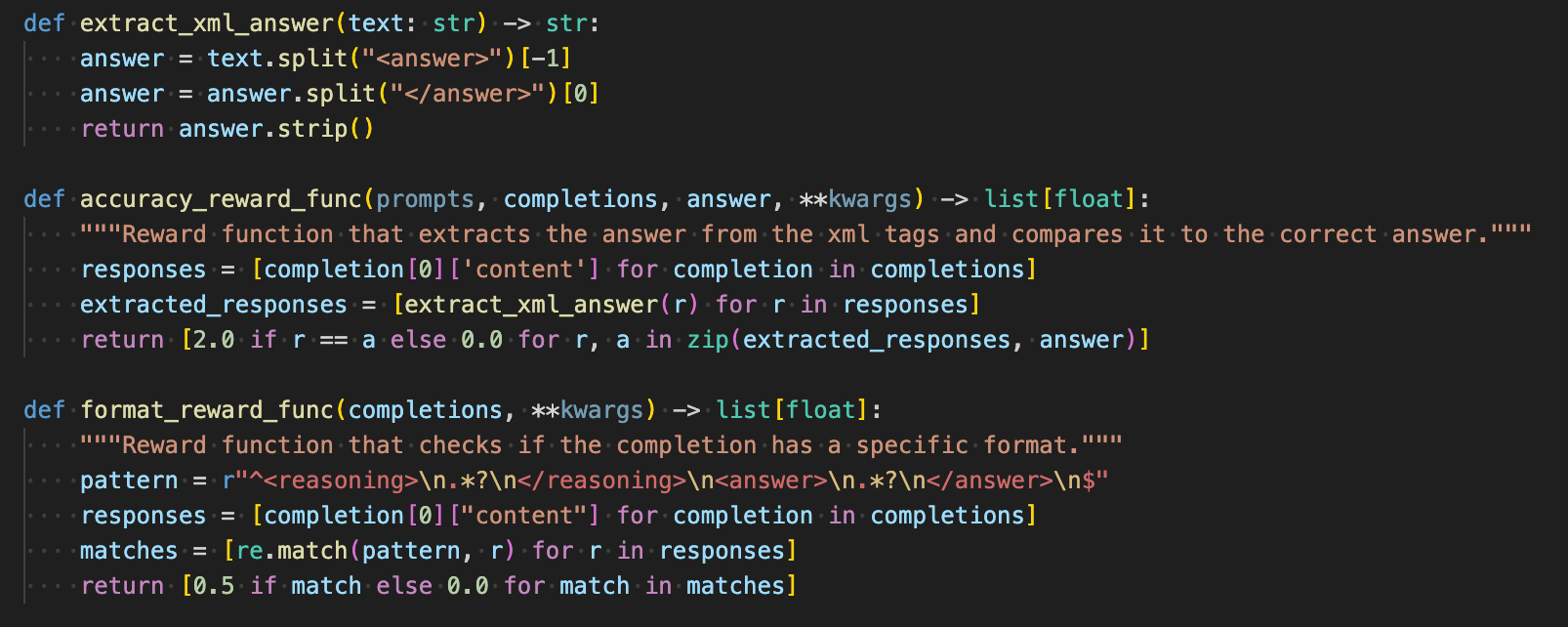
If you took the definitions in Accuracy Rewards and Format Rewards sections above and turned it into code, it would look like this:
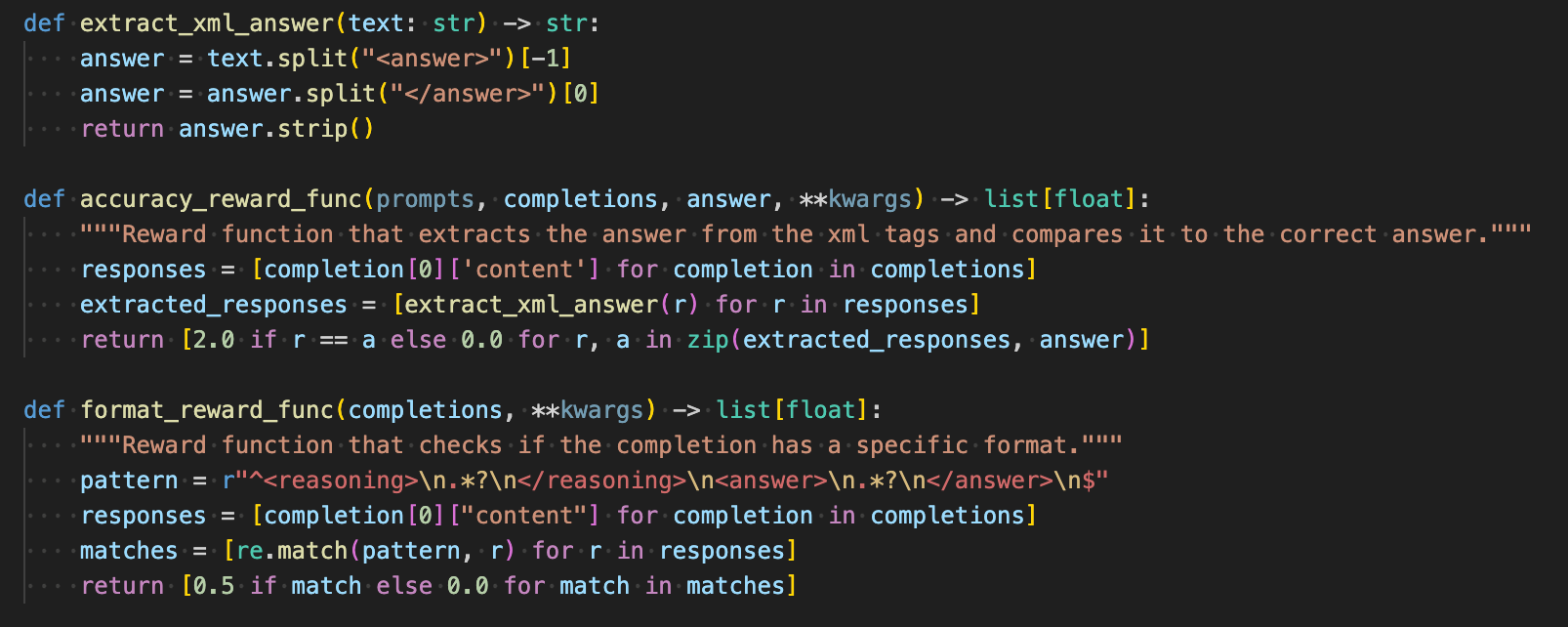
reference:

You don’t even need a full reward model LLM in the loop during training. This leaves us with the policy model and the reference model as the main memory requirements. Dropping the need of 4 LLMs to 2 gives us the huge reduction in GPU requirements.
If your spidey senses are tingling and asking “do these reward function really generalize?” you would be right. They work well for whatever you specify in the rewards, but not much else. In other words, with these two rewards the model does get good at following the <reasoning></reasoning><answer></answer> format and does gets good at reasoning through math, but it fails at other useful tasks.

My prediction is that “The Bitter Lesson” will strike again here. Given enough compute and data, models just want to learn. The less we hand code rules, and more we let the model learn on it’s own, the better it will perform. GRPO rewards here feel a little to hand coded. Why wouldn’t you just have the model learn the weights of the reward signals?
That being said, it is kind of fun playing with different rewards. What’s cool about GRPO is that as long as you can define it in code as a function that returns a value given responses, you can optimize against it. This could even be an external API call to another LLM. I have a feeling in the coming weeks / month people are going to start getting creative with what rewards are fed into GRPO because it is so accessible to train.
Next Up: Training a Rust Reasoner 🦀
What does this look like in practice? The “Transformer Reinforcement Learning” or trl library already has GRPO implemented, and it’s relatively easy to pass in your own reward functions.
Some of the folks in our community are going to try to train a smol 1B param LLM optimized for Rust. I think there’s a lot of juice we could squeeze out of low resource programming languages to get models we could run locally.
The idea would be this:
We have already started collecting a dataset in an oxen repository that is a combination of synthetic data and stack overflow questions that we plan on training on.

If you’d like to join us, let us know in the Discord!
If you are working on fine-tuning LLMs and want to simplify your workflow, check out Oxen.ai...or reach out and we could fine-tune for you if you'd like. We’re happy to bring our expertise to your use case and give you guidance bringing AI in your product from idea to reality. You could also join our community of over 1,300+ AI enthusiasts, engineers, and researchers to ask any fine-tuning questions.