Training a Rust 1.5B Coder LM with Reinforcement Learning (GRPO)


Group Relative Policy Optimization (GRPO) has proven to be a useful algorithm for training LLMs to reason and improve on benchmarks. DeepSeek-R1 showed that you can bootstrap a model through a combination of supervised fine-tuning and GRPO to compete with the state of the art models such as OpenAI's o1.
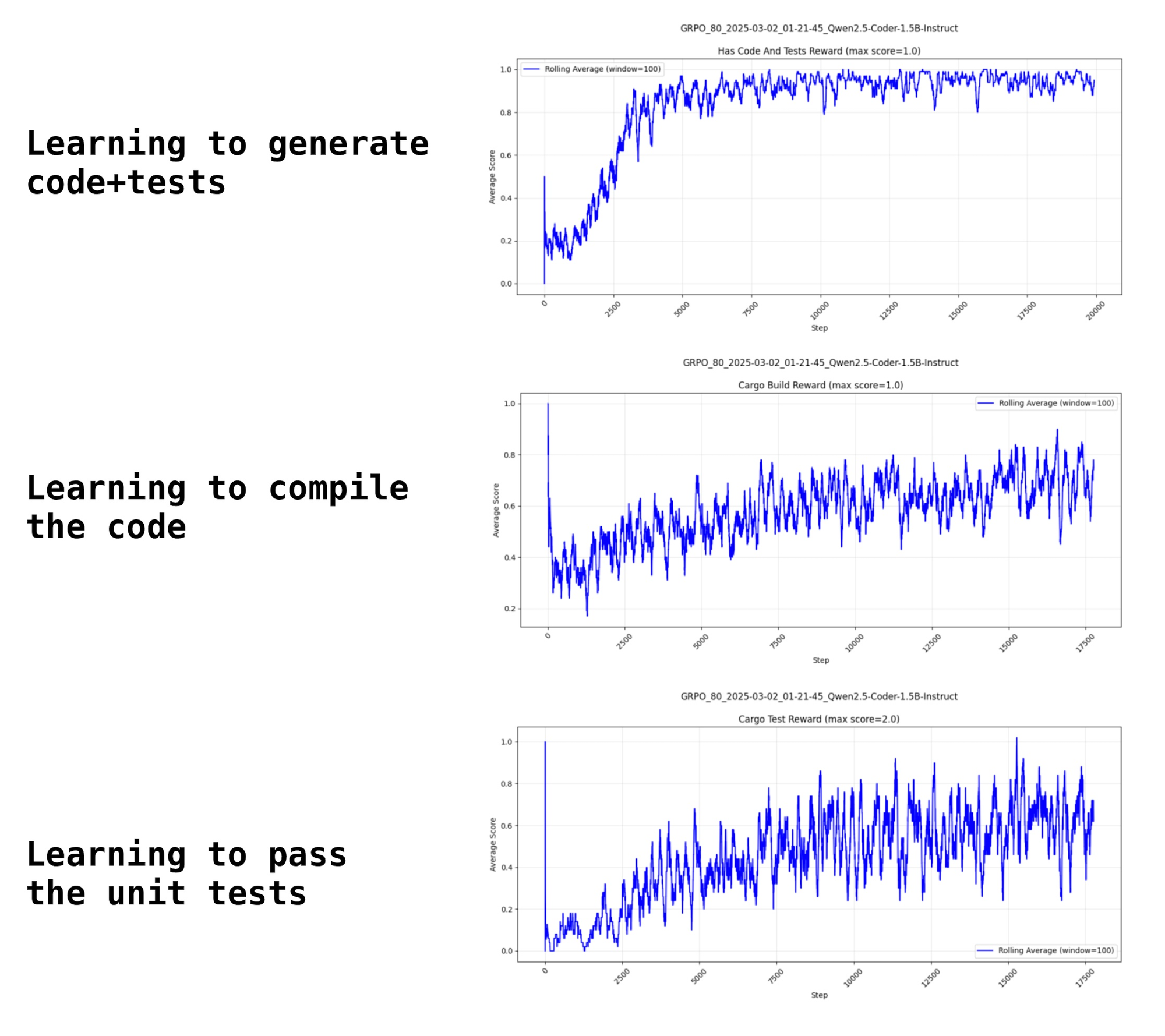
To learn more about how it works in practice, we wanted to try out some of the techniques on a real world task. This post will outline how to train your own custom small LLM using GRPO, your own data, and custom reward functions. Below is a sneak preview of some of the training curves we will see later. It is quite entertaining to watch the model learn to generate code blocks, get better at generating valid code that compiles, and finally code that passes unit tests.
If you want to jump straight into the action, the GitHub repository can be found here.
This post will not go into the fundamentals of GRPO, if you want to learn more about how it works at a fundamental level, feel free to checkout our deep dive into the algorithm below.

Greg spends days fine-tuning and preparing the Fine-Tune Fridays. He does this to empower engineers to hack on their own projects and use Oxen.ai to simplify fine-tuning (or do it for them). If you like this blog, try Oxen.ai today and we'd love to hear your feedback :)
Why Rust?
Rust seems like it would be a great playground for Reinforcement Learning (RL) because you have access to the rust compiler and the cargo tooling. The Rust compiler gives great error messages and is pretty strict.
In this project, the first experiment we wanted to prove out was that you can use cargo as a feedback mechanism to teach a model to become a better programmer. The second experiment we wanted to try was to see how small of a language model can you get away with. These experiments are purposely limited to a single node H100 to limit costs and show how accessible the training can be.
We are also a Rust dev shop at Oxen.ai, so have some interesting applications 🦀 x 🐂.
Why 1.5B?
Recently, there is a lot of work seeing how far we can push the boundaries of small language models for specific tasks. When you have a concrete feedback mechanism such as the correct answer to a math problem or the output of a program, it seems you can shrink the model while maintaining very competitive performance.
The rStar-Math paper from Microsoft shows this in the domain of verifiable math problems allowing the model to reason. The 1.5B model outperforms GPT-4o and o1-preview.
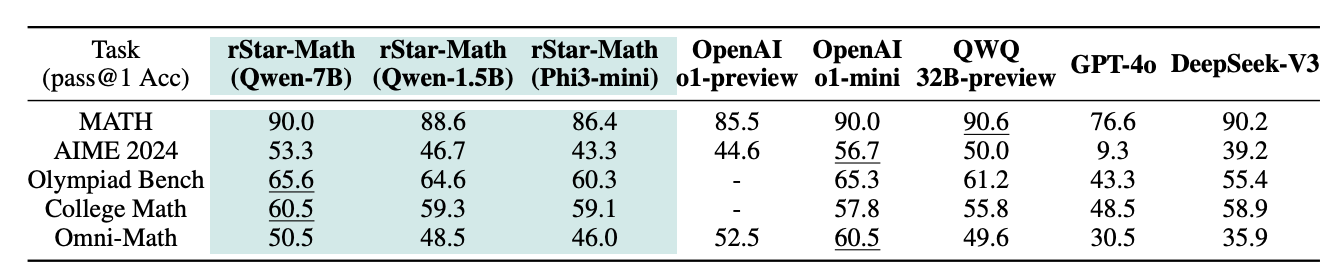
My hypothesis is that we can push similar level of performance on coding, since you have a similar verifiable reward: Does the code compile and does it pass unit tests?
Benefits of Smol LMs
Having small coding models have many benefits including cost, throughput, data privacy, and ability to customize to your own codebase / coding practices. Plus it's just a fun challenge.
The dream would be to eventually have this small model do all the cursor-like tasks of next tab prediction, fill in the middle, and improve it’s code in an agent loop. But let’s start simple.
Formulating the Problem
There are a few different ways you could structure the problem of writing code that passes unit tests. We ended up trying a few. A seemingly straightforward option would be to have a set of verifiable unit tests that must pass given the generated code. This would give us a gold standard set of verifiable answers.

After trying out this flow we found two main problems. First, if you don’t let the model see the unit tests while writing the code, it will have no sense of the interface it is writing for. Many of the errors ended up being type or naming mismatches between the code and the unit tests while evaluating against pre-built, verified unit tests.
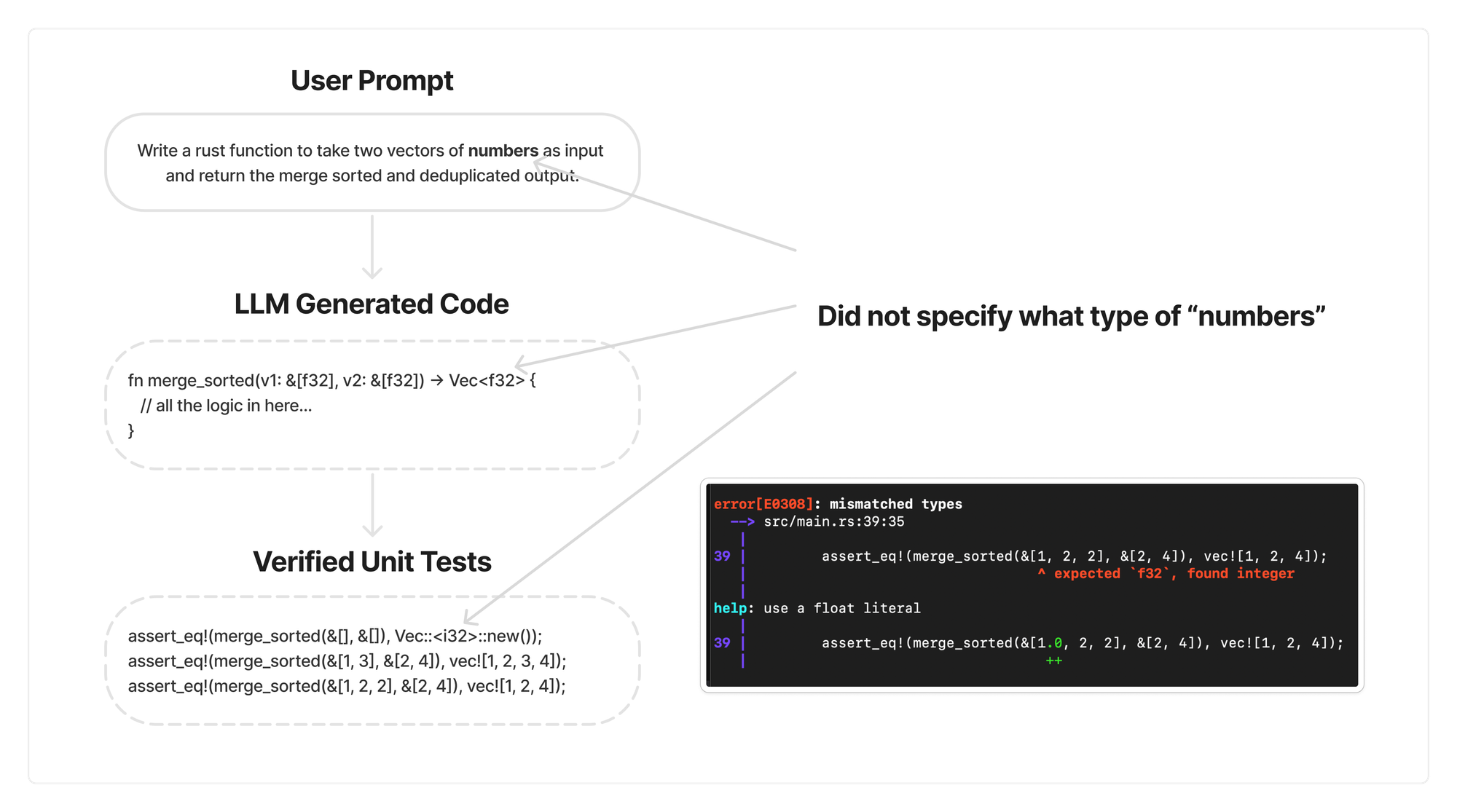
Second, if you allow the model to see the unit tests while its writing the code, you lose out on developer experience. Unless you are a hard core “Test Driven Developer” you probably just want to send in a prompt and not think about the function definition or unit tests yet.
Rather than trying to come up with something more clever, we ended up optimizing for simplicity. We reformulated the problem to have the model generate the code and the tests within the same response.

With single pass there is a danger of the model hacking the reward function to make the functions and unit tests trivial. For example it could just have println! and no assert statements to get everything to compile and pass. We will return to putting guardrails on for this later.
Finally we add a verbose system prompt to give the model guidance on the task.

The system prompt gives the model some context in the format and style in which we are expecting the model to answer the user queries.
The Dataset
Before training, we need a dataset. When starting out, we did not see many datasets targeted at Rust. Many of the LLM benchmarks are targeted at Python. So the first thing we did was convert a dataset of prompts asking Pythonic questions to a dataset of Rust prompts.
We took a random 20k prompts from the Ace-Code-87k dataset. We then used Qwen 2.5 Coder 32B Instruct to write rust code and unit tests. We ran the code and unit tests through the compiler and testing framework to filter out any triples that did not pass the unit tests. This left us with 16500 prompt,code,unit_test triples that we could train and evaluate on. The dataset was split into 15000 train, 1000 test, and 500 evaluation data points.
The final data looks like the following:
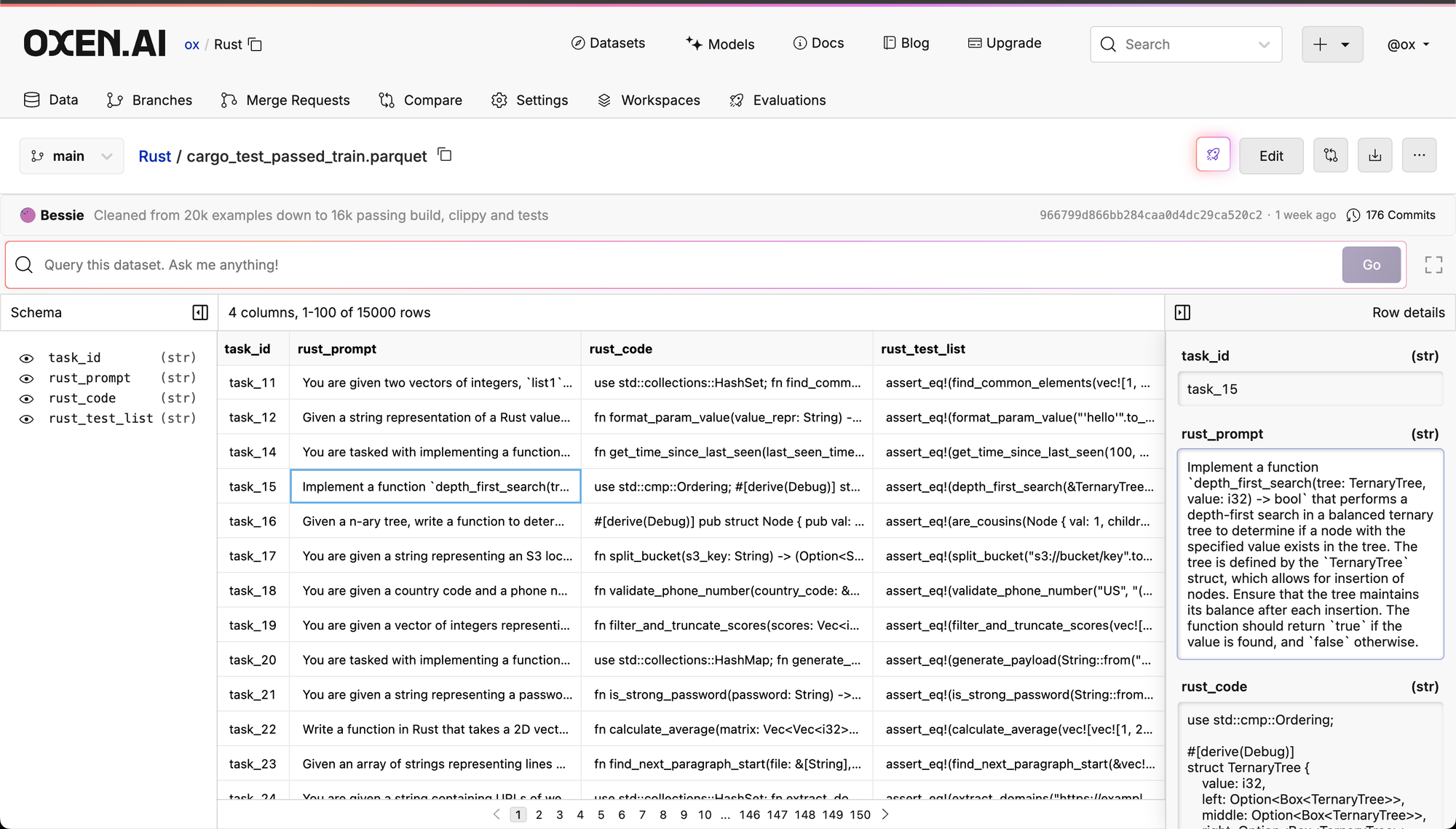

You can follow the prompts and steps by looking at these model runs:
1) Translate to Rust: https://www.oxen.ai/ox/mbrp-playground/evaluations/ce45630c-d9e8-4fac-9b41-2d41692076b3
2) Write Rust code: https://www.oxen.ai/ox/mbrp-playground/evaluations/febc562a-9bd4-4e91-88d7-a95ee676a5ed
3) Write Rust unit tests - https://www.oxen.ai/ox/mbrp-playground/evaluations/b886ddd6-b501-4db8-8ed6-0b719d0ac595
Funny enough, for the final formulation of the GRPO training we ended up throwing away the gold standard rust code and unit tests columns. With our reinforcement learning loop we only need the prompts as input. This makes it pretty easy to collect more data in the future. We’ll dive into how the single prompt as input works in the following sections. Even though we threw away the code and unit tests for training, it was nice to know the prompts are solvable.
Setting a Baseline
Once we formulated the problem, and have a dataset, we wanted to set a baseline and see how well the initial model performs. We will be bootstrapping the training with Qwen/Qwen2.5-Coder-1.5B-Instruct.
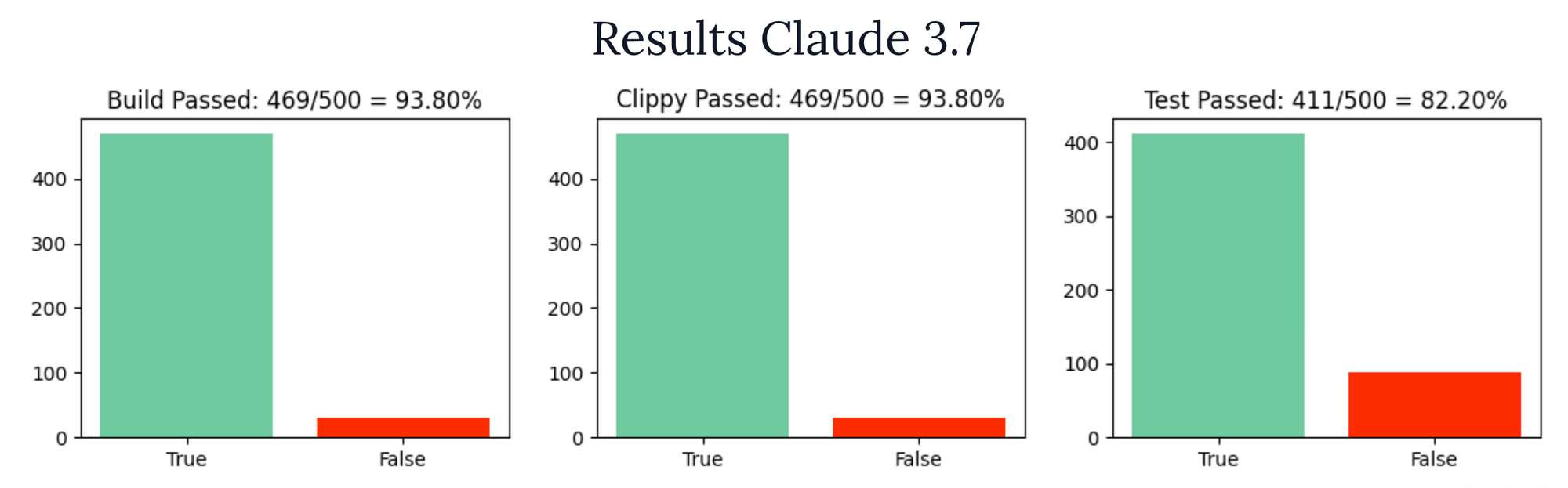
Below the results are split into how often the build passed, the clippy linter passed, and the unit tests passed.
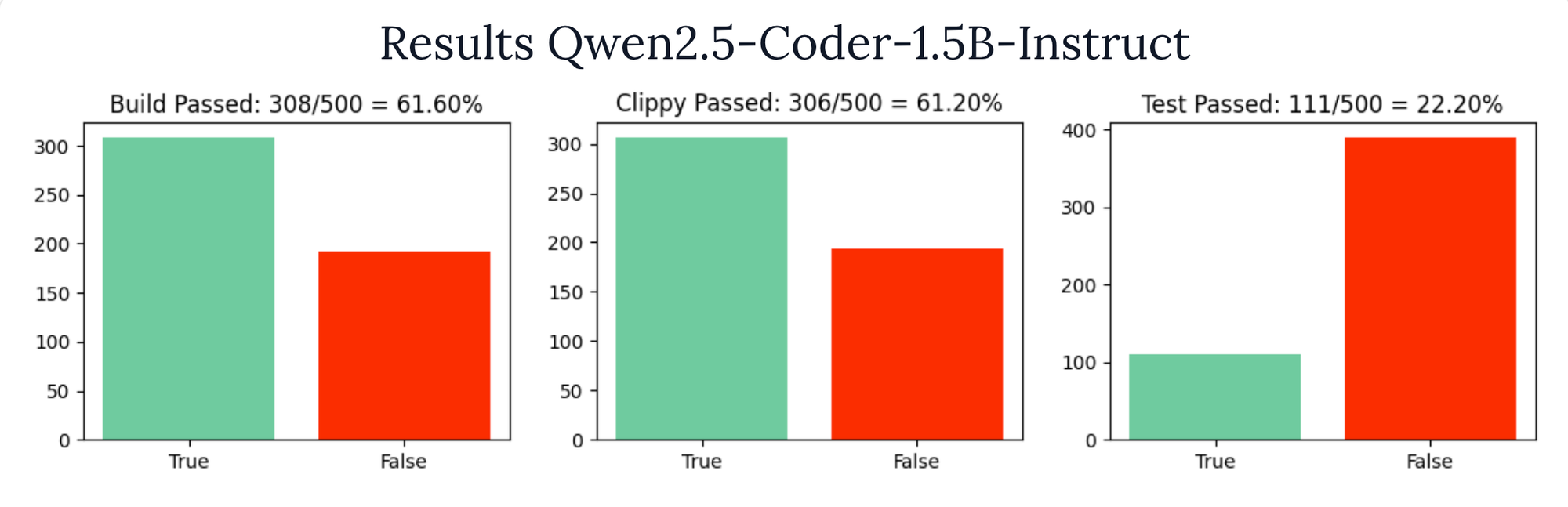
Clippy depends on the build passing, so those numbers tend to be pretty correlated. Feel free to poke around the raw data on Oxen.ai.
How does this compare to SOTA?
We also wanted to see how some of the larger foundation models perform on the task. This will give us a theoretical bar to aim for. The best model we found was GPT4.5, to see other models we experimented with and poke around the results check the appendix at the end.
GPT4.5 passes the build 98% of time and passes it's own tests 87% of time. Pretty impressive.
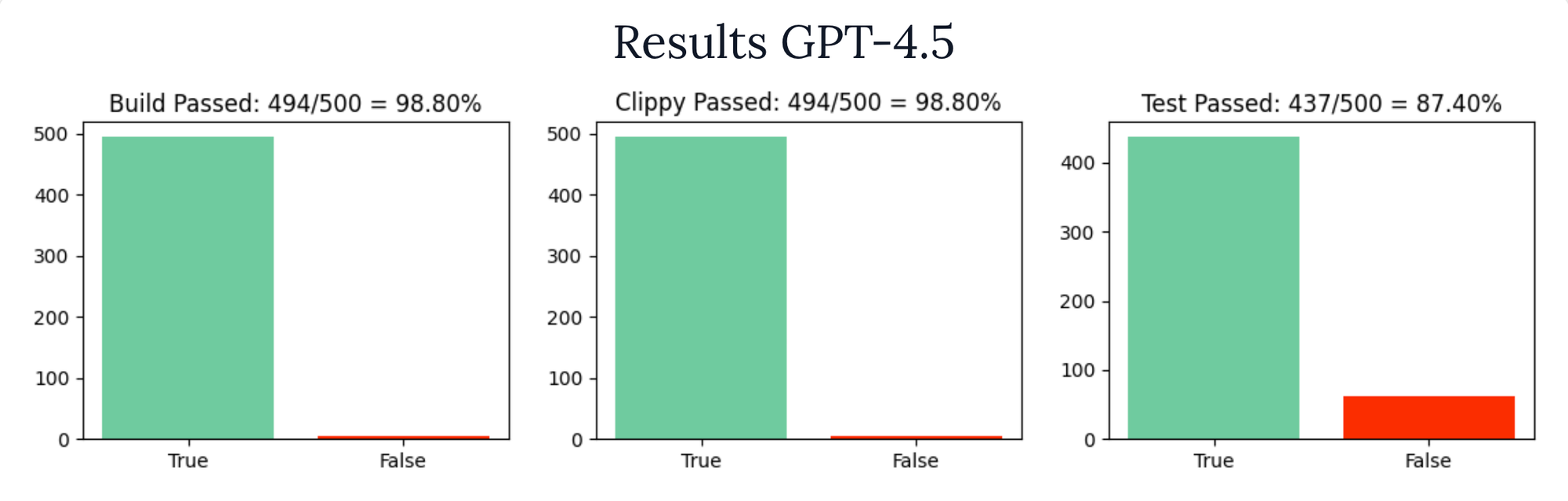

Coming in a close second was Claude 3.7 Sonnet.
Okay, all the setup work is complete. We formulated the problem, we have a dataset, we have a baseline, we have a target...finally we can get to training a model!
Designing Reward Functions
One of the beautiful parts of GRPO is the ability to engineer rewards as simple python functions. Once the rewards are defined, you let the model figure out how to optimize for them. Will Brown from Morgan Stanley calls this “Rubric Engineering”. It gives engineers an accessible way to steer models through RL.
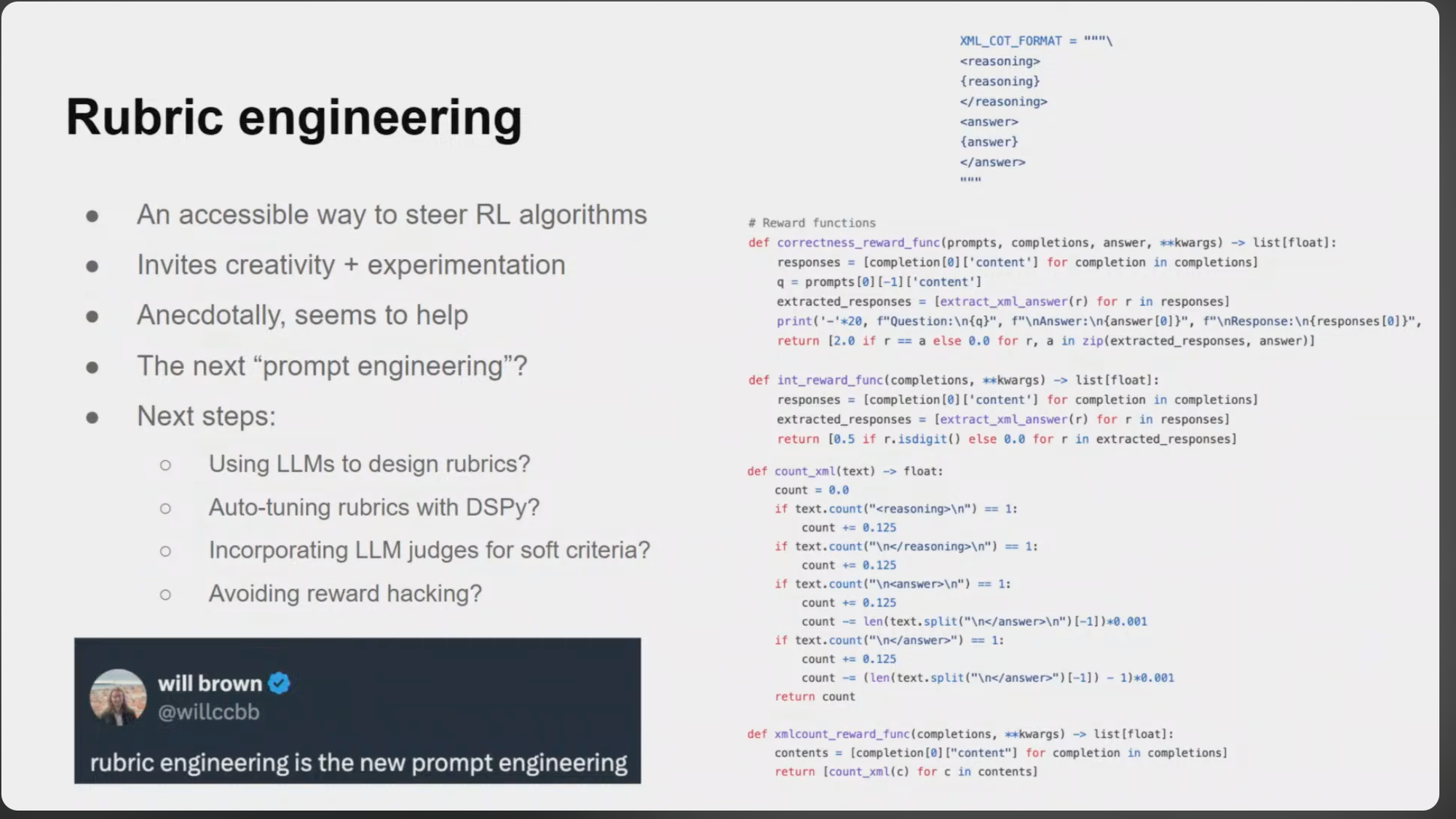
You can see the whole talk here:
GRPO reward functions take in the prompts, responses and target answers. In fact for some rubrics you do not even need the target answers, you may just be grading attributes about the completion itself like it’s format. Example rubrics could be:
- Correctness (direct string match)
- Response Length (number of tokens)
- Response Format (xml, json, code etc)
- External Tool Calls (cargo in our case)
- LLM As A Judge (truthful, helpful, harmless, etc)
We will be using a combination of formatting and running cargo build tools as the rewards. The starter code was taken from @willccbb’s fantastic gist.
https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb
Our Rubric
Let’s see what a “Rubric” looks for our problem. We take a user prompt in, have the LLM generate code and tests, then have a few functions that grade the response.

A reward function could be as simple as a regex requiring that we have a valid test block in our code.
# Simple regex for checking if a code block has a rust tests module
def code_has_test_block(code: str) -> Optional[str]:
# Use re.DOTALL to make '.' match newlines as well
result = re.search(
r'(#\[cfg\(test\)\]\s*mod\s+tests\s*\{.*?\})',
code,
re.DOTALL
)
return 1.0 if result else 0.0
# For each prompt and completion, reward if the response has a test block
def test_block_reward_func(prompts, completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [code_has_test_block(c) for c in contents]You’ll notice that the prompts and completions are a list and we return a list[float] as well. This is because GRPO has a parameter called num_generations that determines how many completions may be generated. Also you may have large batches of prompts + completions during generation. The GRPO algorithm generates N different responses per prompt, and each one gets run through your rubric. Here you can see the model trying different iterations, each passing and failing different rubrics.
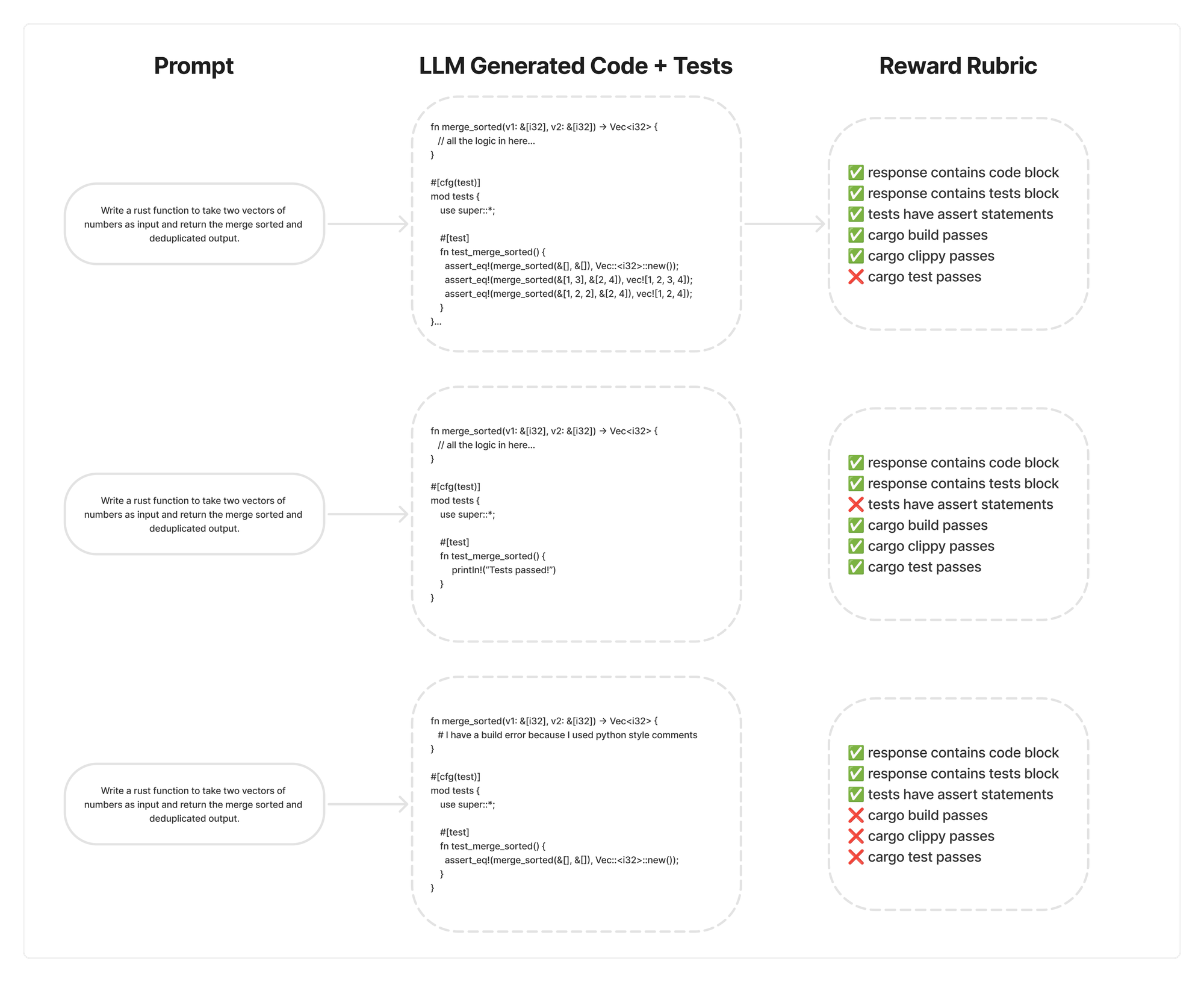
Over time, the model will learn to pass more and more of the rubrics that you define. With the help of the trl library, you can specify multiple different reward functions and pass them into a GRPOTrainer to train the model.
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
cargo_build_reward_func, # 1.0 if passes cargo build else 0.0
cargo_clippy_reward_func, # 1.0 if passes cargo clippy else 0.0
cargo_test_reward_func, # 1.0 if passes cargo test else 0.0
non_empty_reward_func, # 1.0 if the code is not empty else 0.0
code_block_reward_func, # 1.0 if there is a code block else 0.0
test_block_reward_func, # 1.0 if there is a test block else 0.0
tests_have_asserts_reward_func # 1.0 if there are assert statements in the test else 0.0
],
args=training_args,
train_dataset=train_dataset
)
trainer.train()Designing the reward functions is the most rewarding part of setting up a GRPO training loop. Pun intended 🙂.
Cargo Reward Functions
Like we alluded to at the start of the post, we will be using the cargo toolchain for our rewards. Since reward functions can be defined as pure python functions we will simply use subprocess to run the cargo tooling.
The full code can be found in this Marimo notebook on GitHub:
We define a RustTool class that can run cargo build, cargo clippy or cargo test. It has a run() function that will populate and return a dictionary of results with information about the tool passing/failing and any error messages.
class RustTool:
def __init__(self, name):
self.name = name
def run(self, results, project_dir):
try:
result = subprocess.run(
["cargo", self.name, "--quiet"],
cwd=project_dir,
capture_output=True,
timeout=10
)
results[f'{self.name}_passed'] = result.returncode == 0
results[f'{self.name}_stdout'] = str(result.stdout)
results[f'{self.name}_stderr'] = str(result.stderr)
except Exception as e:
results[f'{self.name}_passed'] = False
results[f'{self.name}_stdout'] = f"cargo {self.name} failure"
results[f'{self.name}_stderr'] = f"{e}"
return resultsThis tool then can be used in a project directory that we will setup for each test. The project setup and tear down creates a directory, writes main.rs and Cargo.toml files, populates them with the code and tests, the cleans it up after they are run. See the setup_and_test_rust_project function in the code for more details on this.
With the ability to setup and teardown mini rust projects, we need to hook this into a GRPO reward function. The signature of reward functions take in a batch of prompts and completions and expects you to grade each prompt+completion pair.
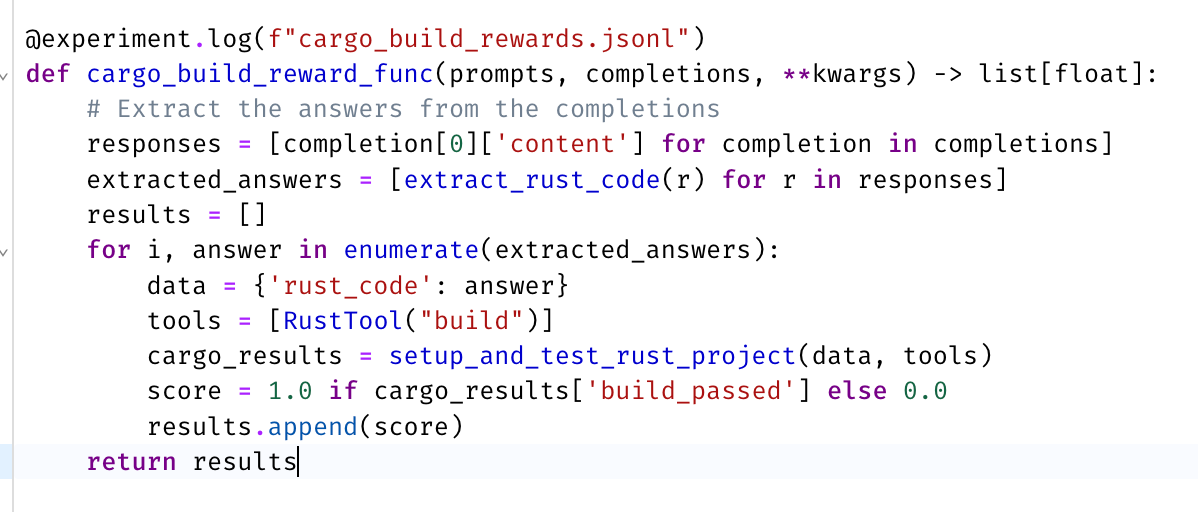
# GRPO reward functions take in lists of prompts and completions from the model during training
def cargo_build_reward_func(prompts, completions, **kwargs) -> list[float]:
# Extract the answers from the completions
responses = [completion[0]['content'] for completion in completions]
extracted_answers = [extract_rust_code(r) for r in responses]
results = []
for i, answer in enumerate(extracted_answers):
data = {'rust_code': answer}
tools = [RustTool("build")]
cargo_results = setup_and_test_rust_project(data, tools)
score = 1.0 if cargo_results['build_passed'] else 0.0
results.append(score)
return resultsIt can be helpful to log the prompts and completions to disk you to get a sense of how the GRPO algorithm works under the hood. For each prompt you will get N completions. Say we set N=4. This gives our model 4 chances at getting the completion correct.
Take for example task_8347 from our logs. You can see it tried to implement the particular function four times, and got the solution correct one time. GRPO rewards the model for the correct solution, improving it’s performance over time. The red below are 3 failed unit tests while the green is a single passed on for the given prompt.

We setup different reward functions for cargo build, test, and clippy using the same tooling and logic. There are also tests that ensure that the code and tests are non-empty and that the tests do indeed have assert! statements. This makes sure that the model does not hack the reward function and simply write tests with print statements that pass cargo test.
All of the results are logged to Oxen.ai during training so that we can plot them over time and monitor how well the model is learning. This is where the curves from the beginning come in. As the model is training, we simply compute a rolling average over the data to see if it is improving at the given reward.
rolling_avg = df['score'].rolling(window=window_size, min_periods=1).mean()You can see the model begins fluctuating between 30-40% passing the build, and slowly rises up to 70% within the windows as it trains.
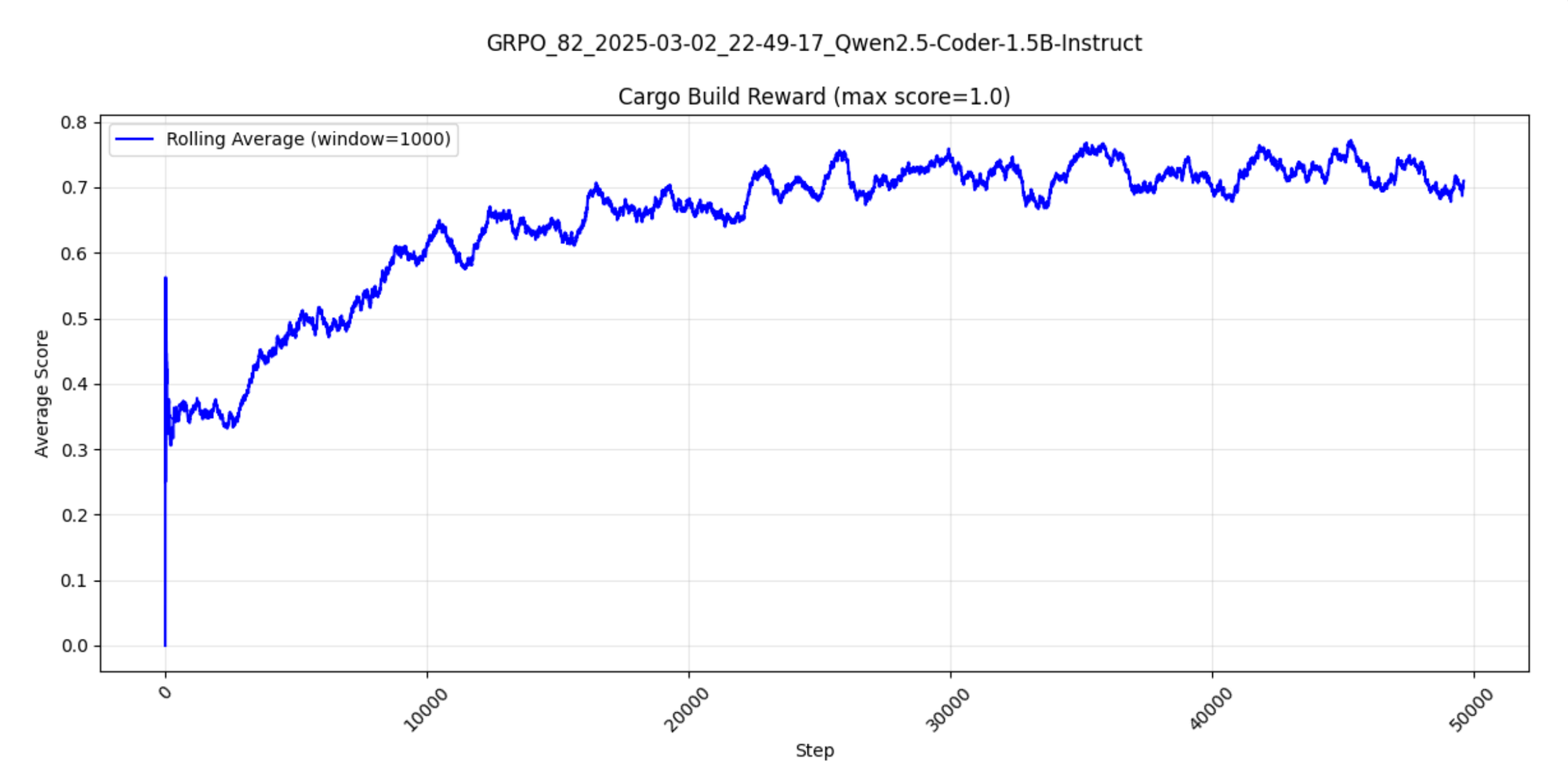
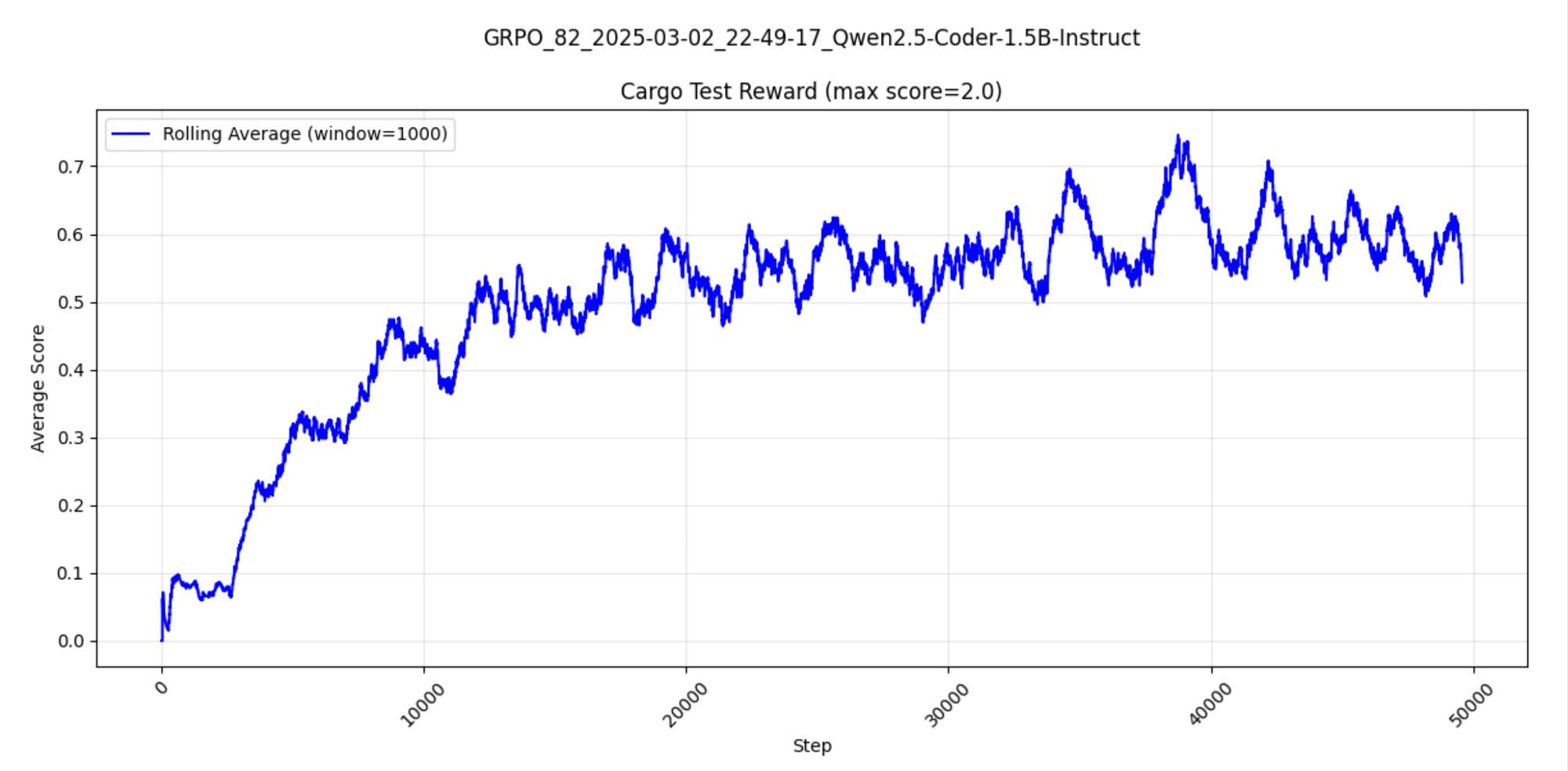
The tests take a little longer to start passing, and have a wider variation of success passing.
It is important to monitor how your model is improving on each on of your reward categories as well as look at some inputs and outputs as they flow through the model. This helps to make sure you don’t have any bugs and that the numbers make sense. In order to do this, we wrote a little @experiment.log python decorator that wraps the reward functions and logs the results to a jsonl file that is automatically committed to Oxen.ai.
The decorator itself simply writes results to the specified file every time the function gets called. Then there is a separate callback in the training loop that commits the data to Oxen.ai every N steps. The data is in chronological order, so you will have to paginate to the end to see the generations at the end of the training run. Below is some sample outputs.

How'd we do?
If you remember from earlier when we set a baseline, the Qwen/Qwen2.5-Coder-1.5B-Instruct model only got 61% accuracy writing code that builds and 22% accuracy passing the tests.
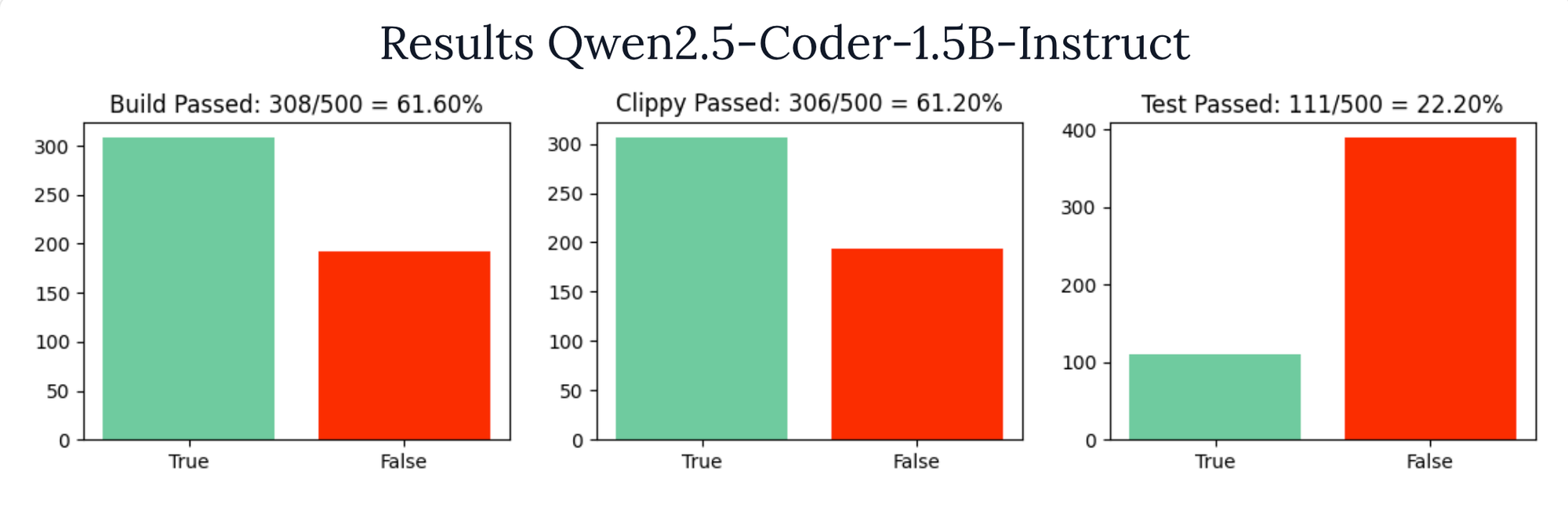
After one epoch of training with GRPO we bumped the build pass rate up to 80% and the tests are passing 37% of the time 🎉. This is a 20% and 15% bump in accuracy respectively with a single training epoch.
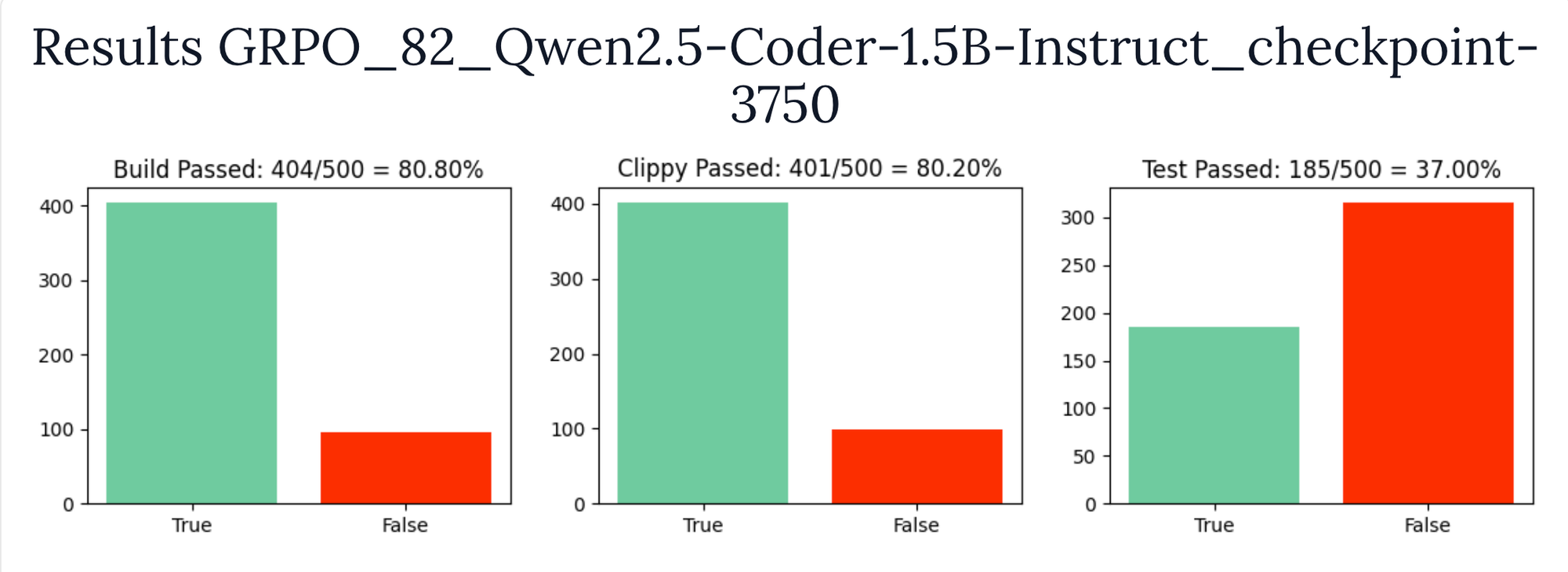
Not too shabby for a couple function definitions and a relatively small dataset. The raw results from the 1.5B model can be explored here:

This is a pretty encouraging start. The training took a bit over 24hrs and cost < $100 on Lambda Labs. Here's the cost per hour of an H100 for reference:

The experiment shows that the GRPO algorithm is relatively accessible for anyone to define their own arbitrary reward functions, and get a substantial bump in performance even on a small model.
Update: Training 3B Parameter Model
We decided to also kick off a 3B parameter model which got up to 73% accuracy.
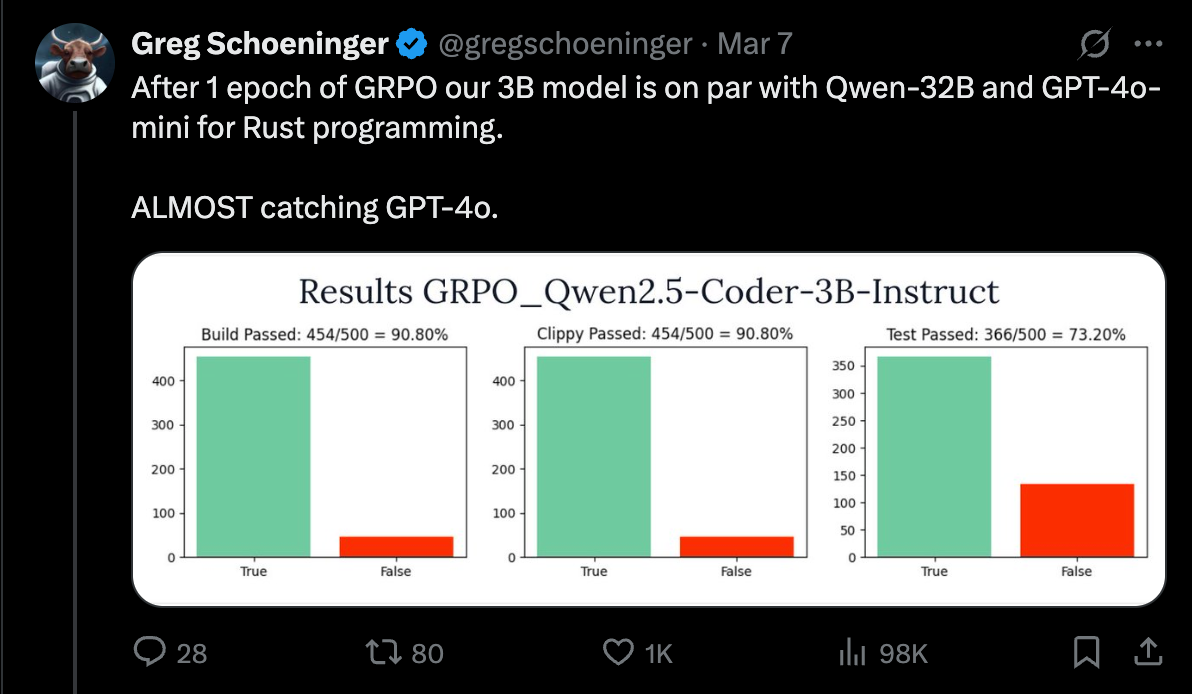
https://x.com/gregschoeninger/status/1898122619024818344
Next Up
This task was pretty limiting to writing a single function with unit tests that pass. Ideally you would want your coding model to be able to complete a variety of use cases. We will be working on extending the dataset to have different categories of tasks:
- ✅ Writing functions
- ✅ Writing unit tests
- Fixing errors from the compiler
- Fill in the middle / autocomplete
- Create a patch/diff given a prompt
- Next edit (tab) prediction
If you have any others that you think would be interesting to add to this list, let us know! We are also going to be running experiments on larger models such as 3B and 8B to see how the performance compares.
Want More?
This post is a part of a series called Fine-Tune Fridays where we fine-tune a model and show you how we did it! Check out Oxen.ai or reach out to hello@oxen.ai if you want to simplify your fine-tuning workflow or have us do it for you. We’re happy to bring our expertise to your use case and give you guidance bringing AI in your product from idea to reality. You could also join our community of over 1,300+ AI enthusiasts, engineers, and researchers to ask any fine-tuning questions.
Feel free to follow me on X (formerly Twitter) to get updates on any of this work.