How Phi-4 Cracked Small Multimodality
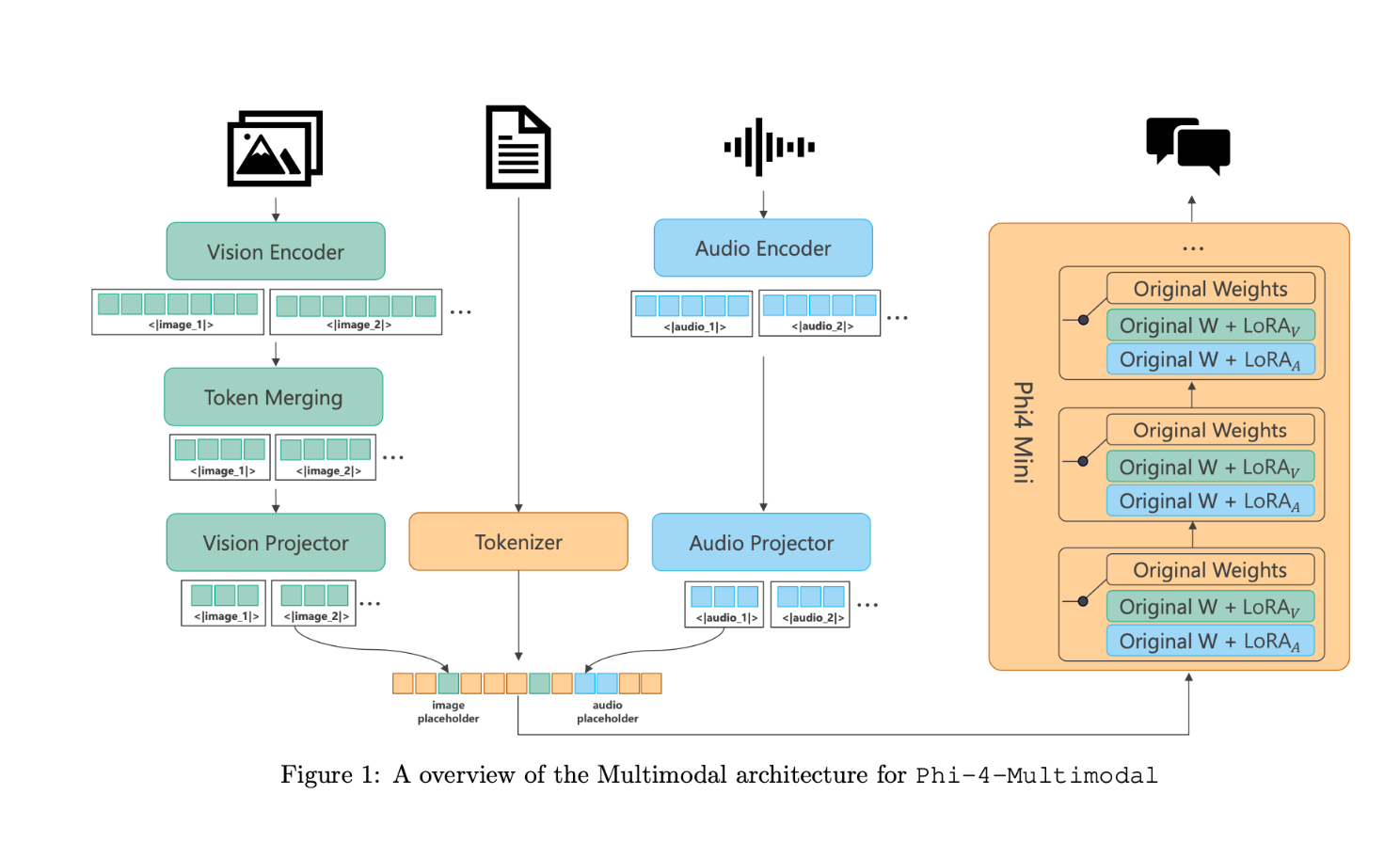

Phi-4 extends the existing Phi model’s capabilities by adding vision and audio all in the same model. This means you can do everything from understand images, generate code, recognize speech, translate languages, and reason over complex tasks all in a 5.7B parameter model that you can run on your laptop. All while maintaining the original language model performance.
Microsoft’s Phi models continue to show if you carefully curate and synthesize data, you can achieve highly competitive performance with Small Language Models (SLMs).
This was an Arxiv Dive filled with examples and code examples so I'd recommed following along with the video to see what we did.
Greg spends full days diving into research papers and writing the Arxiv Dives. He does this to empower engineers to hack on their own AI and use Oxen.ai to set up their data. If you like this blog, try Oxen.AI today and we'd love to hear your feedback:)
Use Cases
Here are some use cases one could use Phi-4 for:
- Brand recognition (what logos are in this image?)
- OCR
- Extract graphs from PDF
- Answer questions about charts
- Extract key frames from video
- Solve latex math problems
- Classify people
- Summarize images
- Write a user interface given a screenshot (could we optimize with GRPO?)
- Meeting transcripts
- Follow commands (Play that song)
Before we dive into how it works, let’s kick it around a little…

Model Architecture: Mixture of LoRAs
They add new modalities by using a “mixture of LoRA’s”, while keeping the base language model completely frozen. In their tests, this gets comparable performance to fully fine-tuned models on multi-modal benchmarks.
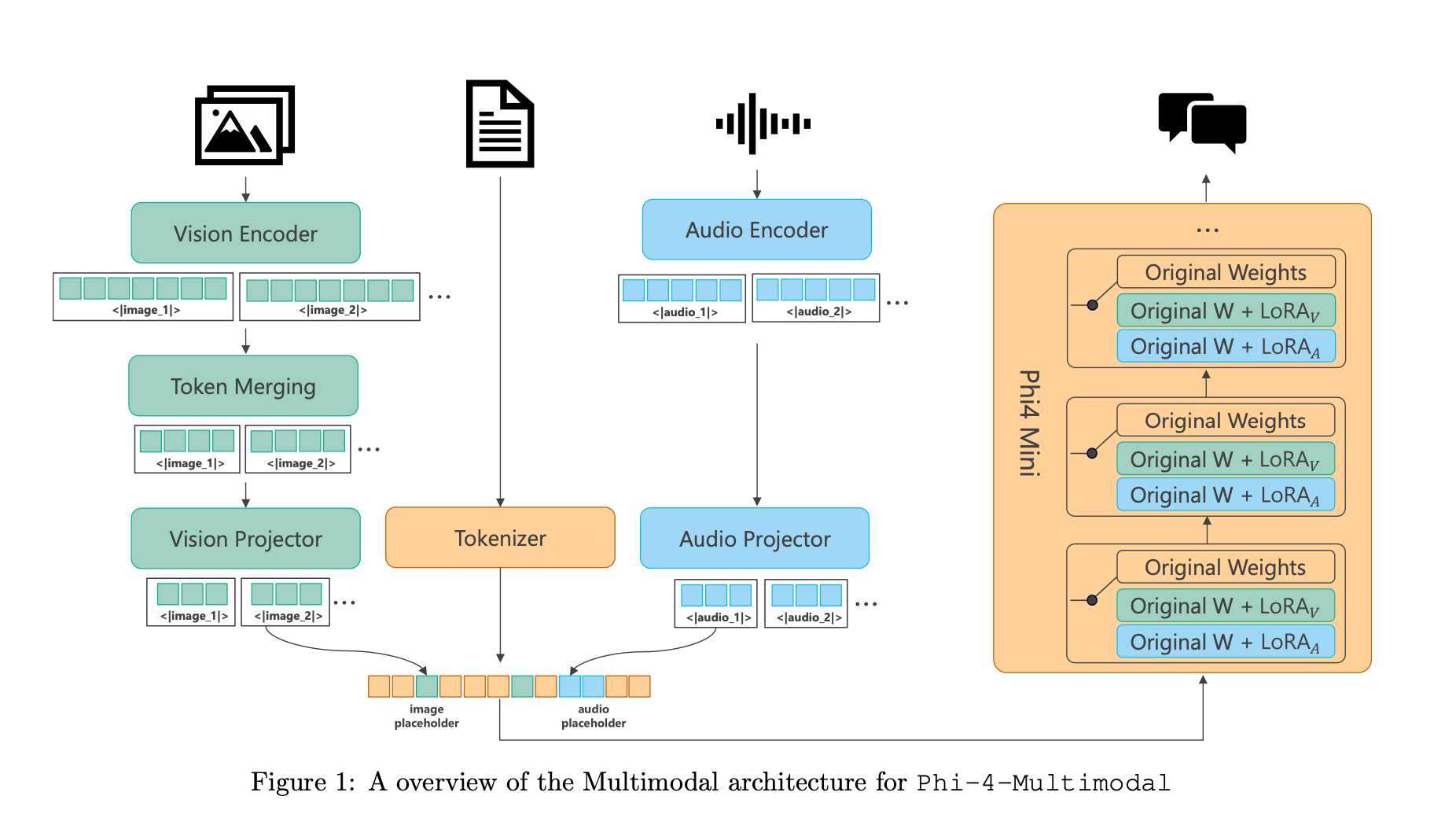
You’ll see that there are text, image, and audio tokens that are fed into the transformer. Then there visual and audio LoRAs (LoRA_V and LoRA_A) that are trained into the model.
This architecture is very extensible, allowing new LoRAs to be added without impacting existing modalities.
Often fine-tuning of new modalities in smaller language models can diminish the performance of the base model. It is hard to balance adding new modalities and maintaining accuracy while also keeping the architecture small enough to run on the edge.
To balance complexity of training, and model size, Phi-4-Multimodal trains different LoRAs for each modality.
If you don’t remember or don’t know about LoRA’s - you can think of them as small sets of parameters on the side that are very efficient to train and can be merged into the final model weights at the end. We dove into how they work here:

Vision Training
Base Model + LLM2CLIP training

Then four stages of training:
- Projector alignment - only train the vision projector on captions to align the vision and text embeddings, while preserving the vision encoder
- Joint Vision Training - projector and vision encoder are both trained to enhance OCR and dense understanding
- Generative Vision-Language Training - LoRA on the language decoder and trained on single frame SFT data for generative language modeling
- Multi-frame training - freeze the vision encoder, extend the context length with multi-image and temporal understanding
Audio Training
Two stage audio training:
- Large scale automatic speech recognition to align in the semantic space. Language decoder is frozen, but update the audio encoder.
- SFT on instruction following
Reasoning Training
LIMO and S1K show that you just need a little high quality reasoning data to get a reasoning model.
- Phi-4-Mini is pretrained on 50 billion reasoning CoT tokens from frontier LLMs
- Fine tuned on 200k high quality CoT samples
- Roll-Out DPO on 300k preference samples
Data and Training Details
As you can imagine, data collection for such a multimodal modal is quite extensive. They gloss over a lot of the details in the paper, but this is the bulk of the work.
This section will give you a sense of the data it was trained on, so we can have a better sense of what you can use it for in practice.
They improve the pre-training data over phi-3.5-mini through a few techniques
- Better data filtering - building a classifier based on positive and negative examples of toxic, obscure, scientific data points etc
- Better math & coding - they augment the original data with instruction based math and coding datasets
- Better synthetic data - The phi-4 technical report lays out these details. The idea is you can spoon feed the LLM more data like the data you actually want it to output. They hand crafted 50 categories of data with different desirable properties.
This ended up with 5 trillion pre-training tokens. Most of the LLM Training details is in the Phi-4 technical report, because this is the backbone.
For post training they add in function calling, summarization, code completion. And fill in the middle coding tasks.
They generate a large volume of synthetic chain of thought reasoning and DPO preference data.
The visual training data contains a few types of data:
- Documents with interleaved text-images
- Image-Text pairs (captions, etc)
- Synthetic datasets from OCR of PDFs
- Synthetic data for chart comprehension
- Instruction following SFT data
The Audio data is comprised of
- Automatic Speech Recognition (ASR) transcriptions
- Automatic Speech Translation (AST)
- Speech Question Answering
- Speech Summarization
- General Audio Understanding (other sounds like music)
- Instruction following data with audio - text pairs
They do use a lot of synthetic Text To Speech data to acquire and bootstrap some of the tasks above.
Some of the speech summarization data is up to 30 minutes of length and use transcription + summarization in text land to create the SFT data for summarizing audio.
Evaluation
Phi-4-Multimodal outperforms some of the closed source foundation models on a variety of benchmarks.
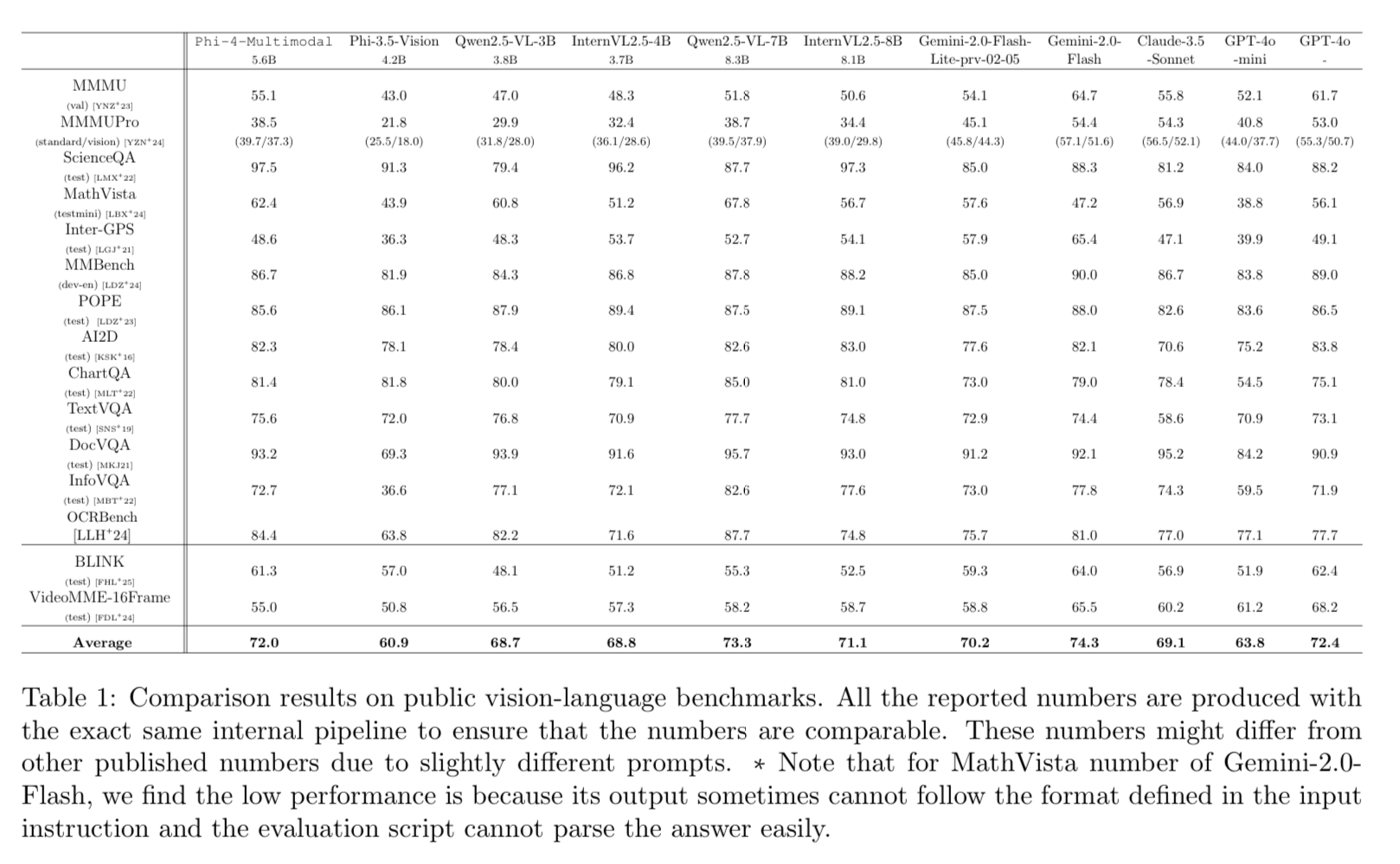
To be honest, some of these benchmarks are kind of dumb. Evaluating image models with multiple choice questions is not super applicable to the real world. Unless it’s a straight classification task.
Some more interesting tasks might look like this:
Extracting information from tables

Then asking follow up questions

I was most surprised by the speech recognition benchmarks. It kind of makes sense that language modeling and speech are tied, and training on both could improve the other.
Phi-4-Multimodal outperforms specialized speech models like WhisperV3.
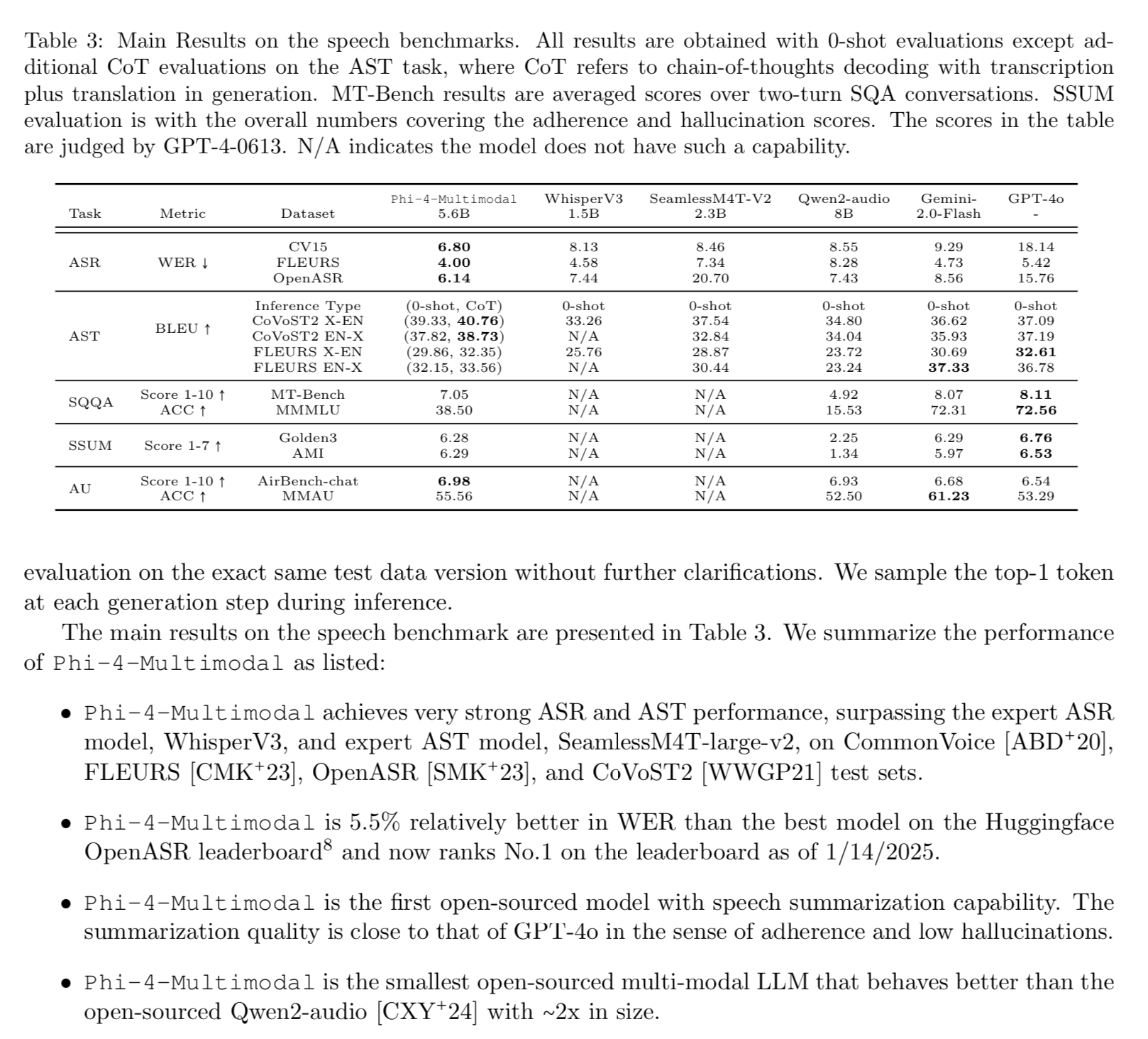
Show ASR live “Transcribe the audio clip into text.”
“Capture the speech in written format in the language spoken, please. Remove any hesitation words like um, uh. Support mixed languages. Your response should be formatted as follows: Spoken Content: <transcribed text here>”
SQQA - Spoken Query Question Answering.
There are many different audio tasks it can perform, this is nuts:

Do we want to try any more data now that you’ve had some time to think on it?
- Brand recognition (Starbucks)
- OCR
- Extract graphs from PDF
- Answer questions about charts
- Extract key frames from video
- Solve latex math problems
- Classify people
- Summarize images
- Write code given a screenshot (GRPO?)
- Meeting transcripts
- Follow commands (Play that song)
Conclusion
Overall, I think its pretty encouraging that we have a model that literally takes up 11 GBs of RAM (and I'm sure people will eventually convert this to a model that can run locally) are showing that we don't need these 400 billion parameter models, you just need really high quality data specific to your task. I'm excited to see where these small multimodal models go.
Notebooks 🚀
If you liked the notebooks you saw in the blog, they are live on Oxen.ai! Simply click "Add Files" -> "Create new notebook" within your repository to spin up an H100 GPU or any other compute backend in seconds.
We're looking for feedback, so feel free to join our discord and let us know what else would be helpful to add or improve.