Downloading Datasets with Oxen.ai

Oxen.ai makes it quick and easy to download any version of your data wherever and whenever you need it.
When we say quick, we mean raw speed. Oxen chunks and transfers data faster than your traditional version control system. When we say easy, we mean there is a minimal learning curve. Oxen commands mirror git so that you can get up and running in a breeze.
Many of the features are also directly available through the Oxen.ai web interface if you prefer to work in the UI.
Install Oxen.ai
If you do not have Oxen.ai installed, it comes in two flavors a Command Line Interface (CLI) and a Python Library. If you are following along through the UI, feel free to skip these steps.
To install the CLI:
brew tap Oxen-AI/oxen
brew install oxenTo install the Python Library:
pip install oxenaiFurther instructions for downloading binaries for other platforms can be found in our developer docs.
Clone a Data Repository
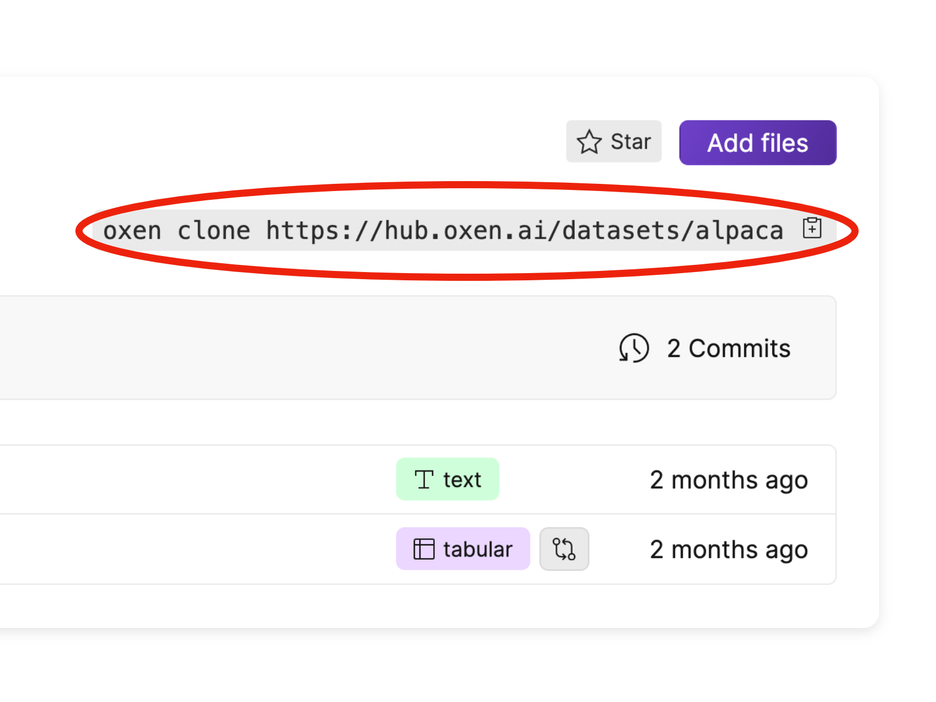
Cloning all the files and folders within data repository is as easy as using the clone command. Oxen smartly chunks and transfers the files and folders to your local machine and creates a .oxen directory to keep track of every version.
💻 Clone from CLI
oxen clone https://hub.oxen.ai/{namespace}/{repo_name}Every data repository on the Oxen.ai web hub has the clone command handy in the upper right hand corner above the file list. To follow along you can use the datasets/alpaca data repository which contains fine-tuning data for instructing large language models.
Make sure the url is prefixed with hub.oxen.ai . The hub part is important as copying the url directly from the browser will not work.
🐍 Clone from Python
You can also clone directly in Python with the oxenai library by specifying the repo identifier of namespace/repo_name .
import oxen
oxen.clone("datasets/alpaca")For more info options for the clone command, please refer to our developer docs.
Note: Fully cloning a data repository make 2 copies of the data locally so that you can iterate on different versions without worrying about losing changes. This can be overkill if you are worried about disk space. See the download command below to download a single copy.
Download Individual Files or Folders
Full data repositories may have more data than you need for certain situations like an evaluation run on a test set. The complete version history is also not always needed. Oxen contains handy commands for downloading specific versions of individual files and directories for one off tasks.
💻 Download from CLI
oxen download datasets/alpaca data.jsonlIf you want to download data from specific version you can specify it with the --revision flag. The revision can either be a branch name or a commit id.
oxen download {namespace}/{repo_name} --revision my-branch🐍 Download from Python
From python you can use the dataset module's download function:
from oxen.datasets import download
download("datasets/alpaca", "data.jsonl", revision="main")Both download functions accept a file or a directory. If a directory is specified it will recursively clone the data in that directory.
🌎 Download from Web
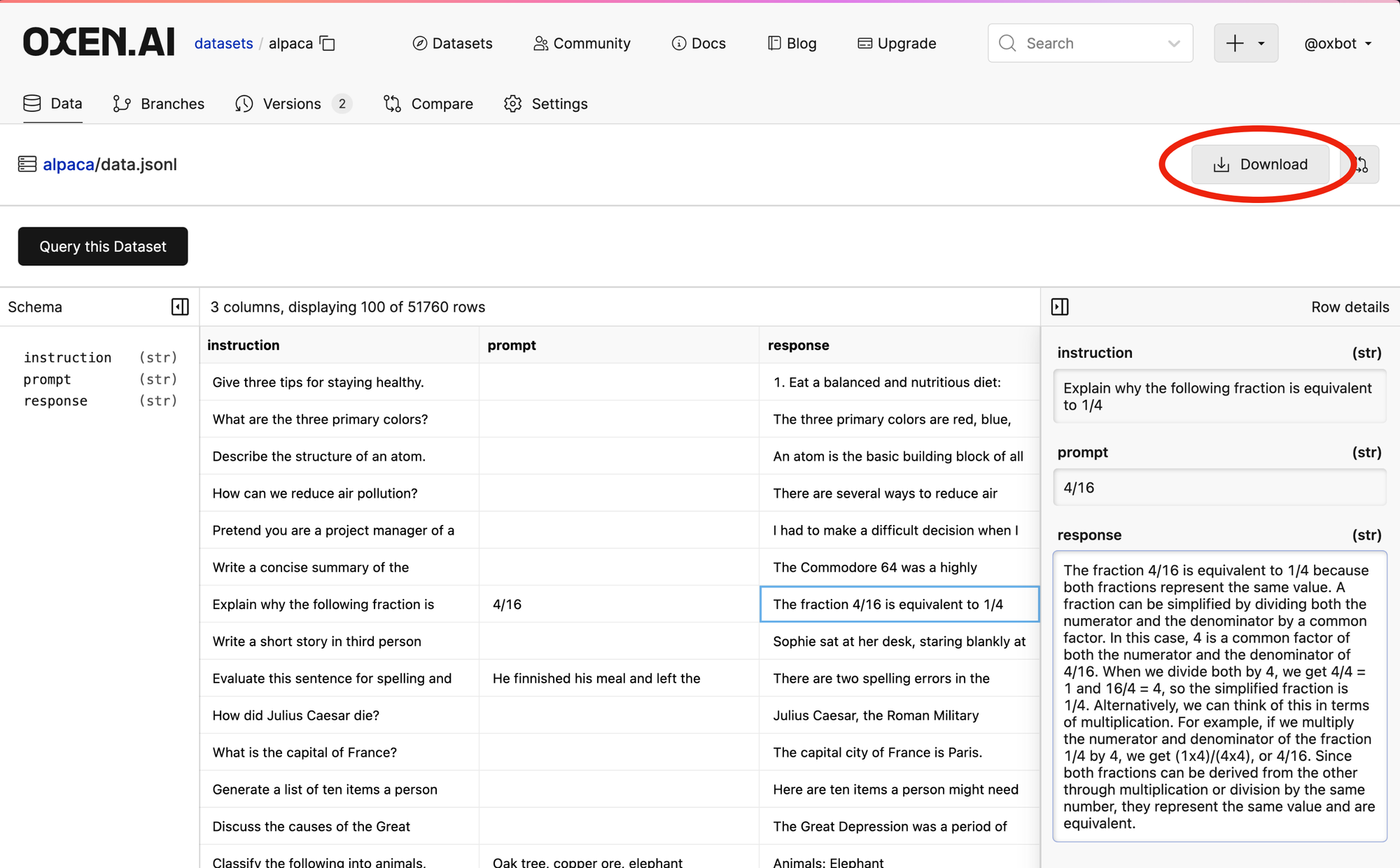
When exploring datasets, you can also download data directly from the Oxen.ai web interface by clicking on the file and then clicking download.
Next Up
Downloading data is a great first step, but the true magic of Oxen.ai comes in when you actually start iterating on the data itself. In the next tutorial we will walk through how you would create your own data repository, version the data, make changes, and upload it back to Oxen.ai to see what changed.