Arxiv Dives - Generating Speech from Text with Fast Speech-2

Every Friday at Oxen.ai we host a public paper club called "Arxiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge and keep up with the bleeding edge. If you would like to join the discussion live, sign up here.
The following are the notes from the live session. Feel free to follow along with the video for the full context.
Fast Speech-2 Resources
Paper: https://arxiv.org/abs/2006.04558
Examples: https://speechresearch.github.io/fastspeech2/
Why Text to Speech? (TTS)
Audio generation is fascinating, but doesn’t get as much attention as LLMs or Computer Vision.
Speech is the oldest form of communication between people. There are millions of hours of podcasts, and videos, and audio out there on the internet that capture nuanced interactions and tons of knowledge.
If you think about our sensory system as humans, sight and sound are two of the most important senses. (Smell, taste, and touch are hard to encode into a computer, until we have a smell-o-scope).

Jokes aside, I think the trifecta that currently are encoded into computers, and are everywhere, are vision (image & video), audio (podcasts, music, video), and text (which is just kind of a lossy encoding of human thought).
Generating audio could be a key component to intelligence. A great book on Generative Deep Learning States:

In order to generate something as complex as audio that has meaning, you have to have an underlying representation of that meaning.
If neural networks can generate speech or audio, we might be able to use the same network of knowledge for general intelligence.
Background Knowledge
If you have never done work in speech, we are going to try to get us from zero to hero in audio land, assuming very little prior knowledge (besides having ears 👂) to make the rest of the paper make sense.
Waveform = Way to represent raw audio. You may have 44,100 samples per second, for a total of 5,000,000+ samples for a 2 minute audio clip. Or a 5 second audio clip would be 44,100*5=220,500 samples.
 Luke Hande
Luke Hande
Mel-spectrograms = is an image with frequency on one axis, time on the other, and amplitude (decibels) as the color.
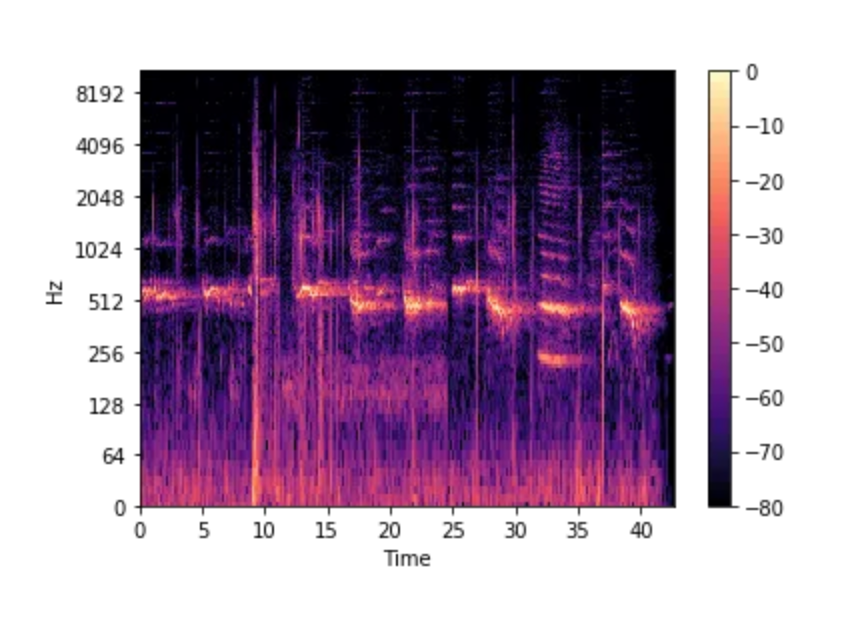

Humans can only hear in certain frequencies.
Dogs can hear in much higher frequencies.

Mel Scale is constructed such that sounds of equal distance from each other on the Mel Scale, also “sound” to humans as they are equal in distance from one another.
Where the difference between 500 and 1000 Hz is obvious, whereas the difference between 7500 and 8000 Hz is barely noticeable.
Phoneme = smallest unit of speech distinguishing one word (or word element) from another. Think of it like a token of text, but for speech. An example of two phonemes might be “ta” and “p” for “tap”, which can distinguish it from “tab” or “tag” or “tan”.
https://github.com/Kyubyong/g2p
Autoregressive = Predict the next thing given the previous thing. Work really well, but are very computationally expensive if the sequence is long.
Non-Autoregressive = Any other strategy. In this case a strategy similar to WaveNet from Deepmind
https://www.deepmind.com/research/highlighted-research/wavenet
Distillation = Taking knowledge and information from larger models and distilling it into smaller ones, by getting rid of “unnecessary knowledge” or dead neurons.

Conditional Inputs = just extra information you can feel into the model to help it make its prediction. In this case they feed “pitch”, “duration”, and “energy” into the model to help it create the sound better.
Why Non-Autoregressive?
Autoregressive can be slow, this is why we pick a non-Autoregressive for the waveform generation.
Training FastSpeech (the original) relies on an Autoregressive teacher model and knowledge distillation.
FastSpeech had some disadvantages
- Teacher student distillation pipeline was complicated and time consuming
- During the transfer from student to teach, the teacher model was not accurate enough, so the process suffered from too much information loss.
Fast Speech 2 aims to solve these problems.
- Get rid of the student - teacher, and just learn from the ground truth targets
- Introduce more variation information of speech (pitch, energy, duration) as conditional inputs. They take the pitch, energy and duration direction from the waveforms.
- Directly generate speech waveform from text in parallel, which has the benefits of end-to-end inference
Fast Speech 2 is 3x faster to train than FastSpeech. Is faster for inference. And “can even surpass Autoregressive models”
Introduction
Text to speech (TTS) has made a lot of progress in the recent years with the use of neural networks.
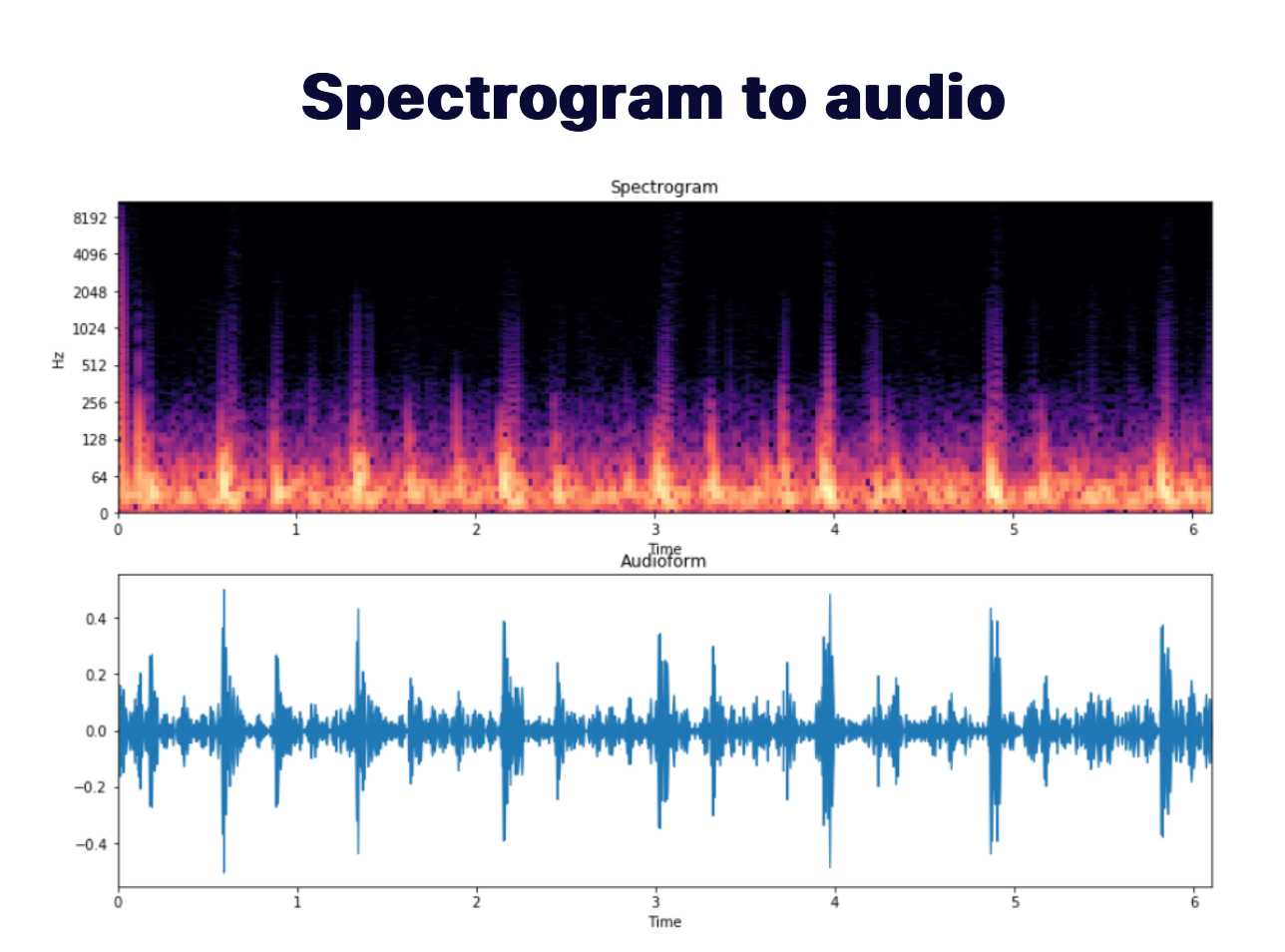
Previous neural TTS models first generate Mel-spectrograms autoregressively from text, then synthesize speech from the generated spectrograms using a separately trained vocoder.
Fast Speech 2 Text → Intermediate Representation → Predict Pitch, Duration, Energy → Spectrogram → Waveform
Fast Speech 2s Text → Intermediate Representation → Predict Pitch, Duration, Energy → Waveform
These autoregressive models suffer from slow inference speeds and robustness (word skipping, repeating).
Non-Autoregressive TTS models have been designed to address these issues.
Models like WaveNet have been shown to be able to reverse the spectrogram back to waveform.
They directly generate a speech waveform from text in inference, which speeds the whole process up, and simplifies the whole pipeline.
 Ilana Stolovas
Ilana Stolovas
Why Spectrogram vs Waveform?
[D] Waveforms vs. spectrograms as inputs to a Convolutional Neural Network: why do ML researchers tend to prefer the latter?
by u/Probono_Bonobo in MachineLearning

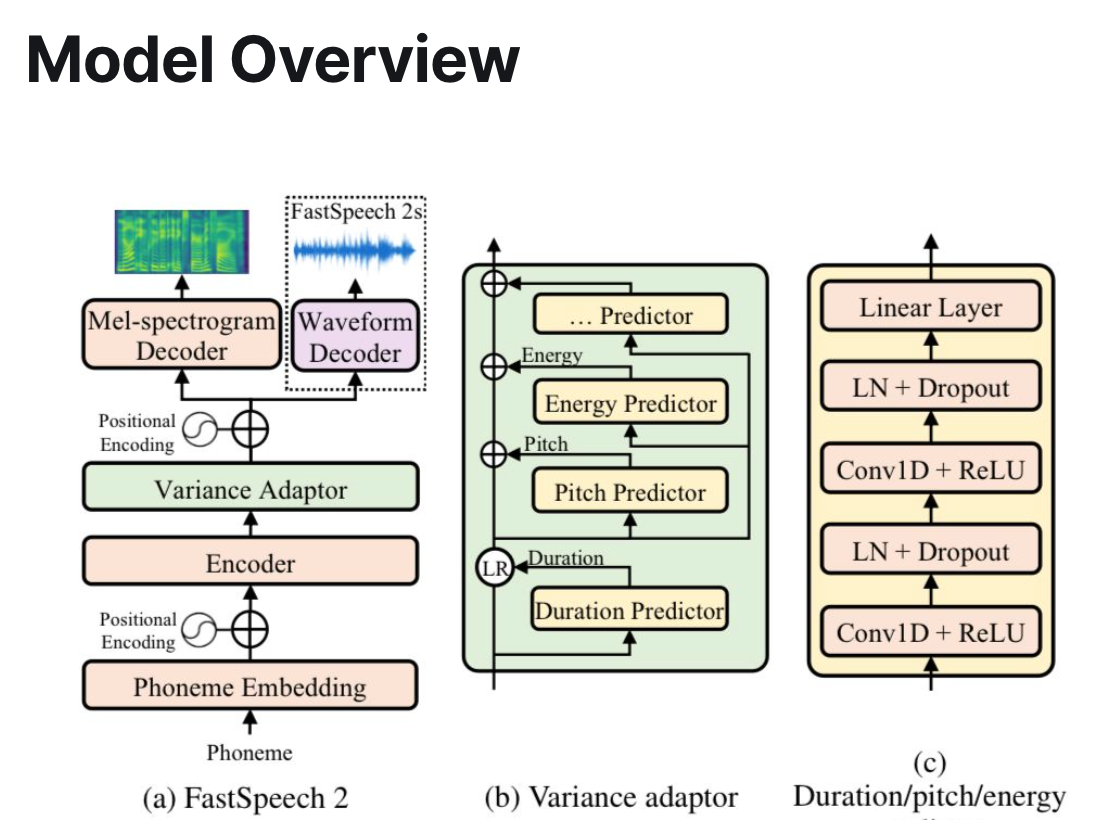
Model Overview

Text is a very low information input to capture all of this variation.
Everyone has a different voice, accent, pitch, volume, etc. All this information gets lost when generating audio just from text alone.
To address this issue, they add variance adaptors in the middle of the architecture.
There is an Encoder that converts a “phoneme embedding sequence” into a latent space.
Then a variance adaptor that adds in information about pitch and energy and duration into the latent space. They do this by having the model try to predict these variables from the latent space.
And finally there is a Mel-spectrogram decoder that converts the latent space into a Mel-spectrogram sequence in parallel.
In Fast Speech 2 they use a feed-forward transformer block, which is a stack of self-attention layers and a 1D-convolution.
For Fast Speech 2s they simplify even further to directly generate the waveform from text, getting rid of the Mel-spectrogram generation (acoustic model) and waveform decoder (vocoder).
Variance Adapter
This is how they capture all the nuance.
The duration predictor takes in the latent space sequence and predicts the duration of each phoneme. They use a tool called Montreal forced alignment (MFA) to extract the phoneme duration. Duration - specifically phoneme duration, represents how long the speech voice sounds
The pitch predictor tries to predict a pitch spectrogram for each frame. This is a key feature to convey emotions and greatly affects the speech prosody (pattern, rhythm and sound, think poetry reading), mathematically it can be measured as different values of frequency
The energy predictor takes a short-time Fourier transform of the frames as the energy and tries to predict the original values of the energy. From the hidden spaces. Energy is frame level magnitude of the Mel-spectrograms which affects the volume and prosody.
Fast Speech 2s
Get rid of the cascaded Mel-spectrogram generation and vocoder.
Challenges
Waveforms contain way more data than Mel-spectrograms. Which means it is difficult to get one component to translate all the information from text to waveform.
Waveforms are also a very long sequence, and we are limited by GPU memory. As a result you can only train on short audio clips that correspond to partial text sequences, so it makes it hard to capture the relationship between generated audio clips from the short text snippets.

They use adversarial training in the waveform decoder to force it to recover phase information, which has traditionally been hard to do.
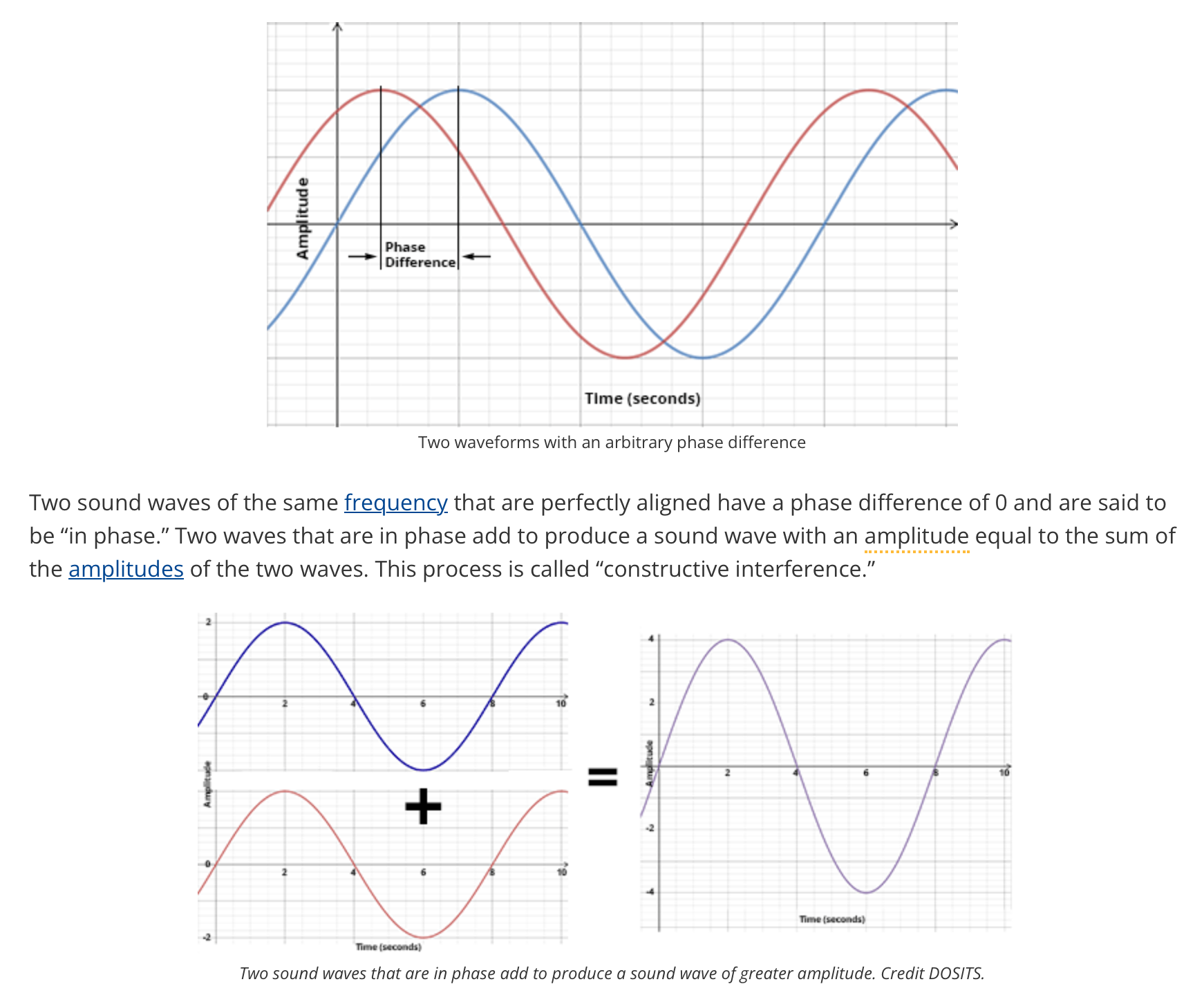
https://dosits.org/science/advanced-topics/phase/
They use the structure of WaveNet (seminal 2016 paper) for the architecture.
The waveform decoder tries to predict multiple resolutions of the Mel-spectrograms and the Short Time Fourier Transform (STFT) values and they use a Parallel WaveGAN architecture as well. They throw away the Mel-spectrogram decoder and only use the waveform decoder to synthesize audio.
https://github.com/kan-bayashi/ParallelWaveGAN
I wish they had a better picture of this full decoder, but we would have to reference the other papers.
Experiments and Results
They use the LJSpeech Dataset which has 13,100 English audio clips (about 24 hours of audio) and the text transcripts.
They use 12,228 samples for training, 349 samples for validation and 523 samples for testing.
They randomly chose 100 samples for subjective evaluation.

All the audio files are of a sample rate of 22050 and they chop them up into 1024 sized frames and skip 256 values as they move to the next frame.
Training and Inference Time
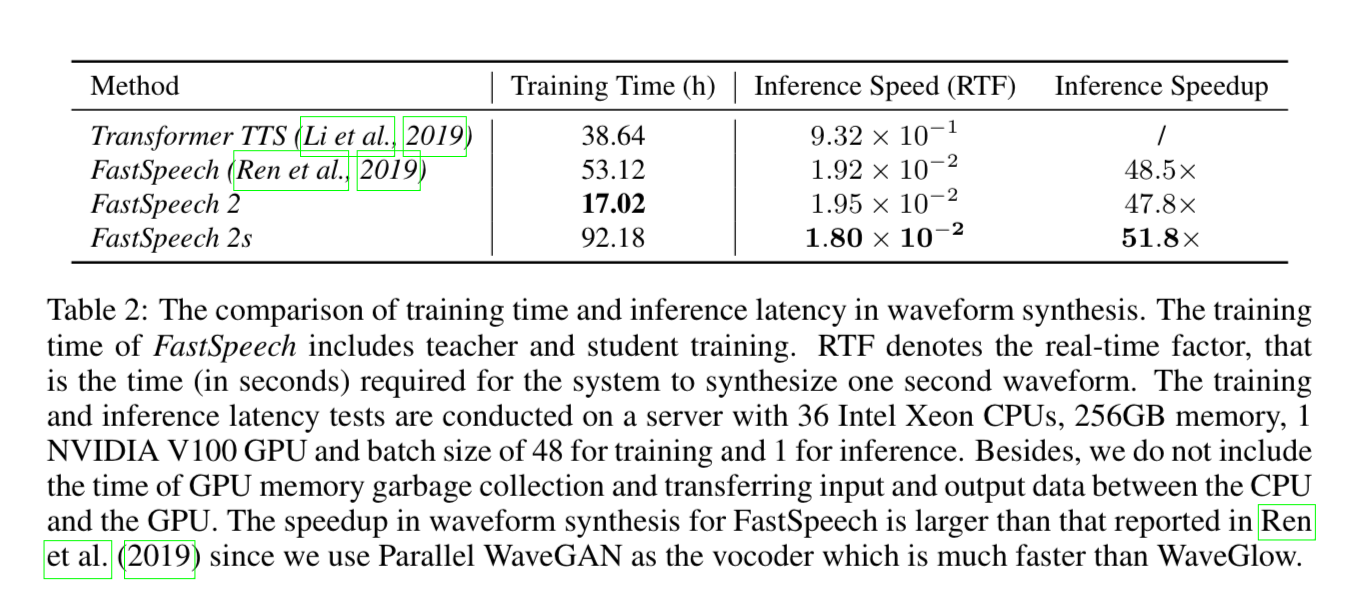
RTF = real-time factor, time in seconds required to synthesize one second of audio. So FastSpeech 2s takes 0.018 seconds to synthesize 1 second of audio on the hardware specified.
36 CPUs with 256 GB Memory
1 Nvidia V100 GPU (32 GB I assume)
To analyze they have some quantitative metrics of how aligned are the phoneme boundaries and how close the distributions are to the ground truth. For example Mean Absolute Error between the energy of the synthesized audio vs the actual audio.
Conclusion
End to end Text to Speech without external libraries is a very challenging problem, but is becoming achievable with these neural network architectures.
In my opinion they actually don’t train it on that much data compared to some of these foundation models for text. LJSpeech is only 24 hours of English audio. I’ve probably listened to more audio than that in the past week, and this model only took 17 hours to train.
You could imagine a pipeline that generates a large dataset from podcasts and videos using Whisper to translate the audio to text, and some sort of human verification or loop to validate the data.
I would love to see the stats on getting these models to run on CPU or mobile devices.
I would also love to see if we can use the internal representations of these generative models to improve speech recognition, text understanding, and other fields of AI.
Discussion Links
https://nypost.com/2023/10/13/everyone-freaked-out-by-metas-creepy-kendall-jenner-ai-chatbot/
If you enjoyed this dive, please join us next week!

All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.