ArXiv Dives: Evolutionary Optimization of Model Merging Recipes

Today, we’re diving into a fun paper by the team at Sakana.ai called “Evolutionary Optimization of Model Merging Recipes”. The high level idea is that we have so many open weights models out there, is there a world in which we breed these models together and use an evolutionary algorithm to keep the fittest models rather than continuing to train them from scratch or fine tune them for your use case.
Teams: Sakana.ai
Publish Date: March 19th, 2024
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
These are the notes from our live session, feel free to follow along with the video for context. If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

Introduction
What if you could improve model performance with minimal compute resources, while leveraging all the open weights models that other people train?

Enter model merging. Not just model merging, but an evolutionary algorithm to try to figure out the best model merges.
Model Merging
Model merging has become an interesting development in the open source LLM community. The idea is you can take two or more models and merge their weights into a single more powerful model without any additional training, making it cost effective to develop new models.
Useful links:
https://github.com/arcee-ai/mergekit
https://sakana.ai/evolutionary-model-merge/
The merging is a bit of black art or alchemy. It kind of blows my mind that it works at all. There are some evaluations at the end of the paper that kind of break my brain. Super interesting line of research. Feels like very approachable research even with limited compute.

What’s cool is you can take a set of two model weights, take the “best” from both, and merge them into one set of model weights. All on a single CPU.
It relies a lot on the model makers intuition about which models to merge and how to merge them. Human intuition can only go so far, this paper explores a systematic approach to discovering new model combinations.
The current Open LLM Leaderboard is filled with merged models.

This paper proposes an evolutionary algorithm to discover more effective model merges. They open source the EvoLLM-JP and EvoVLM-JP in the name of open science 🎉.
Different Types of Merging
There are a few Different model merging techniques:
- Linear weight averaging
- SLERP (Spherical linear interpolation)
- TIES-Merging (resetting minimal parameter changes, resolving sign conflicts, merging only aligned parameters)
- DARE (zeroing out small differences between the fine-tuned model and original base)
More info on these merging techniques and how to merge can be found here:

Many of these techniques rely on the same model architecture (ie Llama or Mistral) but there are some that have been proposed that people call Frankenmerges that allow you to experiment with stacking different layers from multiple models. Frankenmerging is pretty trial and error and very under-explored.
They aim to apply evolution to not only merging recipes with a fixed architecture, but also to stacking layers from different models, potentially creating entirely novel architectures from existing building blocks.
Merging Methods
The goal is to create a framework for merging that results in the merged model surpassing the performance of each individual model.
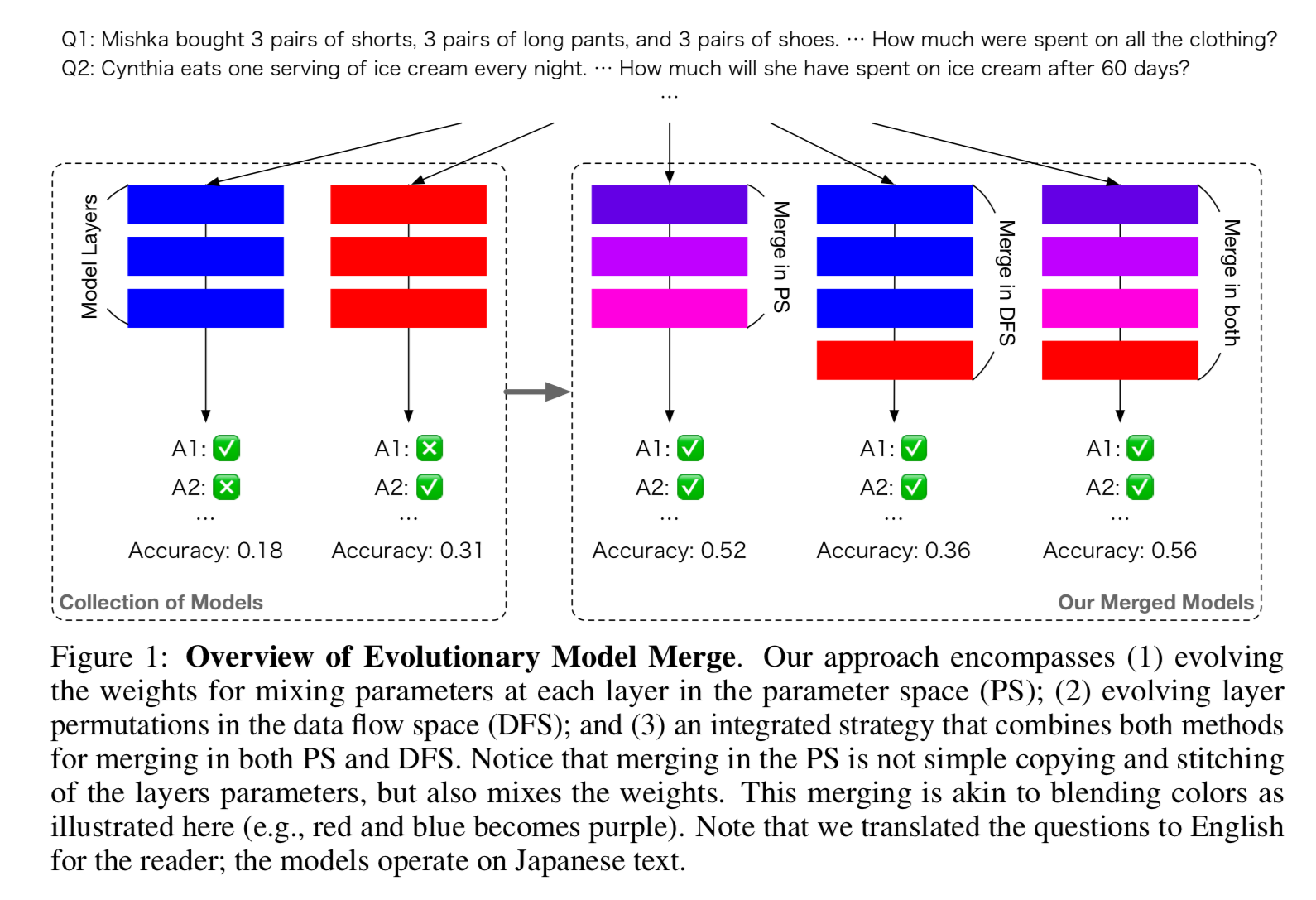
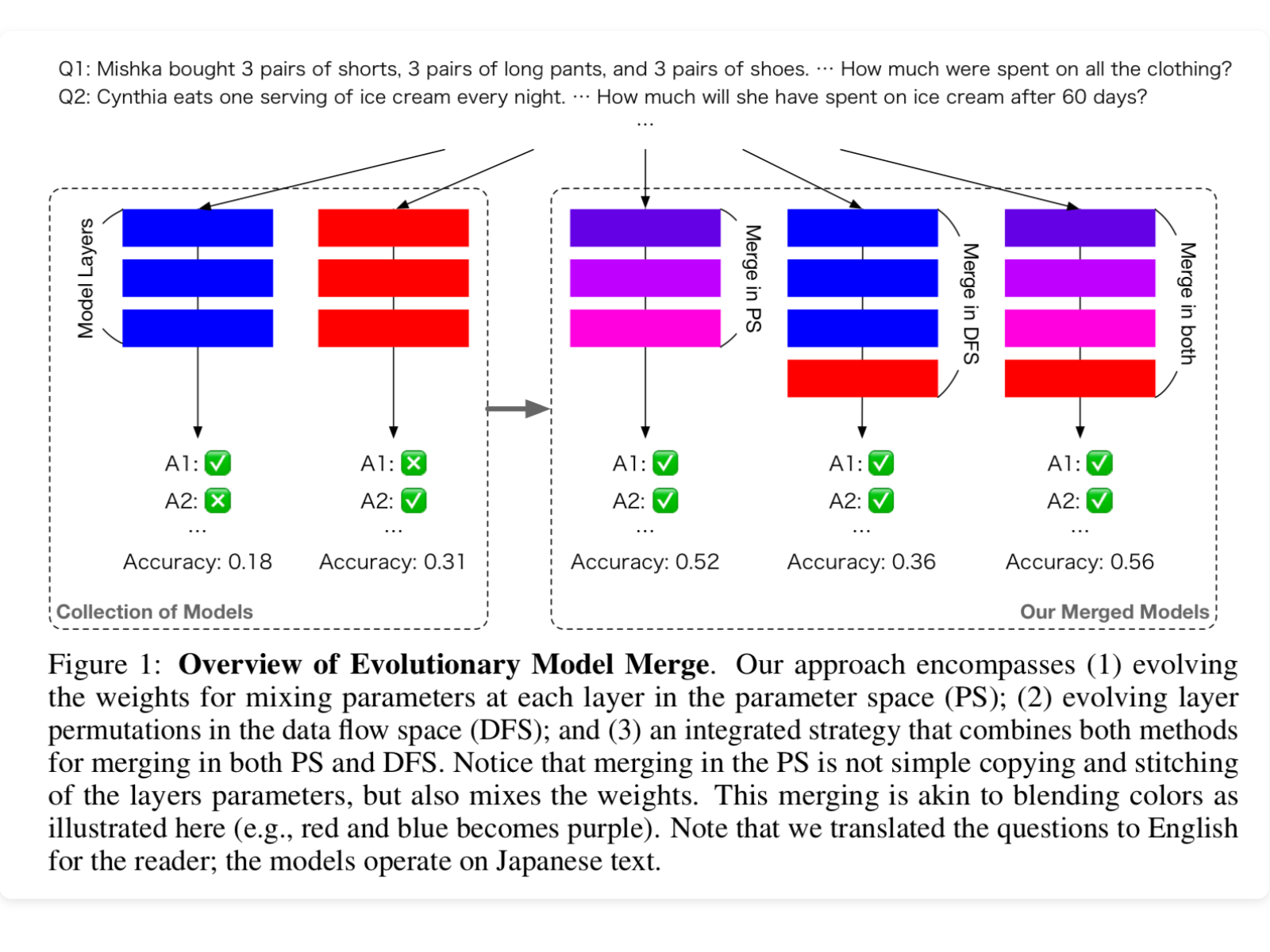
There are two ways that they perform the model merging.
- Parameter Space (PS)
- Data Flow Space (DFS)
Merging in parameter space (PS) is similar to blending colors when painting. It mixes the weights from the two models into new weights. They specifically enhance TIES-Merging Technique with DARE, but use an evolutionary algorithm to pick the hyper parameters when merging.
On the other hand, Data Flow Space merges preserves the original weights of each each layer from the models. DFS looks for the inference path that tokens follow as they traverse through the network. This is a giant search space, given how many models and layers there are to consider.
You can apply the parameter space merging and the data flow merging together to get the best of both worlds, even though they are orthogonal ideas.
Evolutionary Algorithms
To determine the best merges, they use the CMA-ES Algorithm (Covariance matrix adaptation evolution strategy) which is a strategy for numerical optimization.
Evolutionary algorithms are ideal for settings where you do not have a ground truth set of actions to take. For example, in this scenario, we do not know the exact parameter merges that would lead to an optimal model.
They discover the optimal merges by experimenting with merges, and getting some sort of signal for how well we are doing.
The steps for CMA-ES are as follows:
- Create a “population” of models (could be from LLM leaderboard)
- Loop:
- Evaluate each model in the environment, returning the average accuracy over the training data (in this case 1069 examples)
- Breed the model weights from the ones with the best scores to create new members of the population. The breeding step could use a variety of merging techniques adding some randomness to the system.
- You could also add a randomness to the parameters, like genetic mutation (note they did not state this in the paper, but I think it would be interesting, and seen it done in other CMA-ES algos)
- Update the population pool by adding the newly created high performing models and removing poorly performing models.
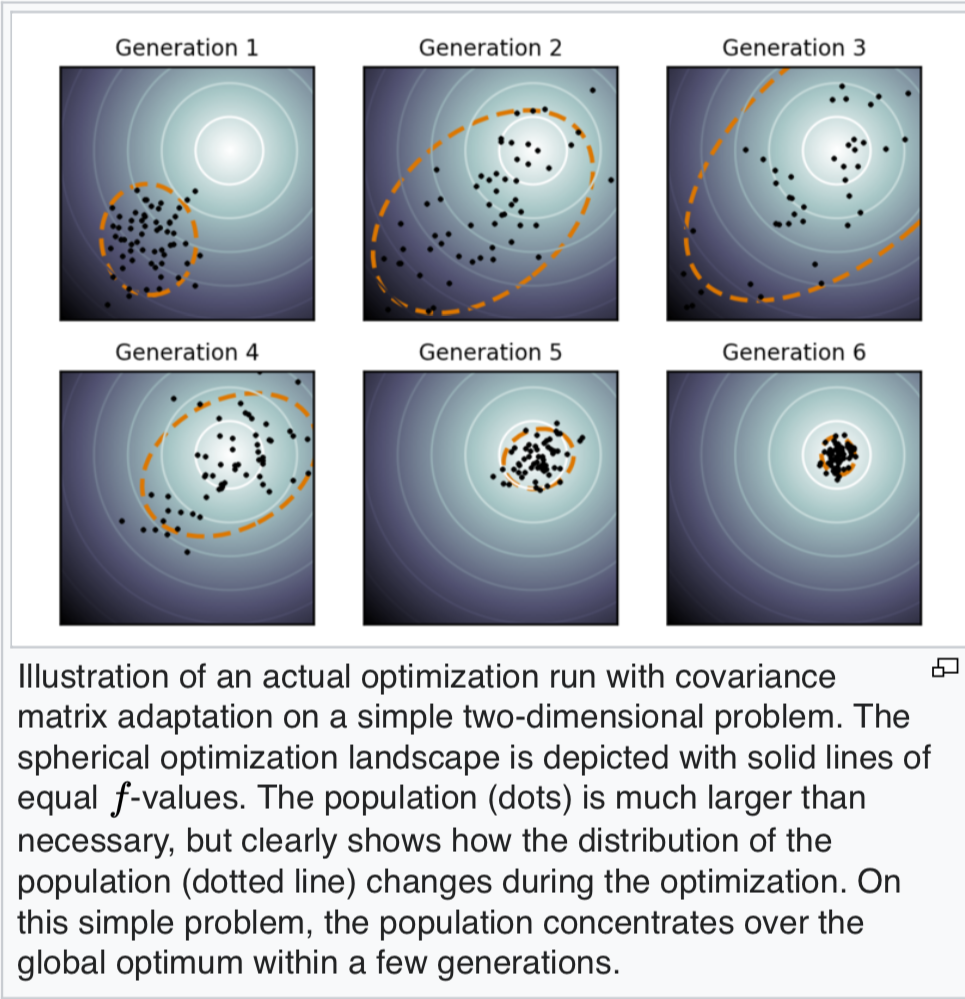
So you can see we start out with a set of models that all get different scores. With each generation the scores spread out, we kill the weak, and converge down to the local minima as we kill out the old ones and keep the good merges.
Improving Math Reasoning
What they use for a score is they take a multi-lingual version of the GSM8k dataset and run the merged models through it to get a score.
They then keep the models that do better and discard the ones that do not.
What is absolutely crazy about this is the performance on tasks such as math after performing both the PS and DFS merges.
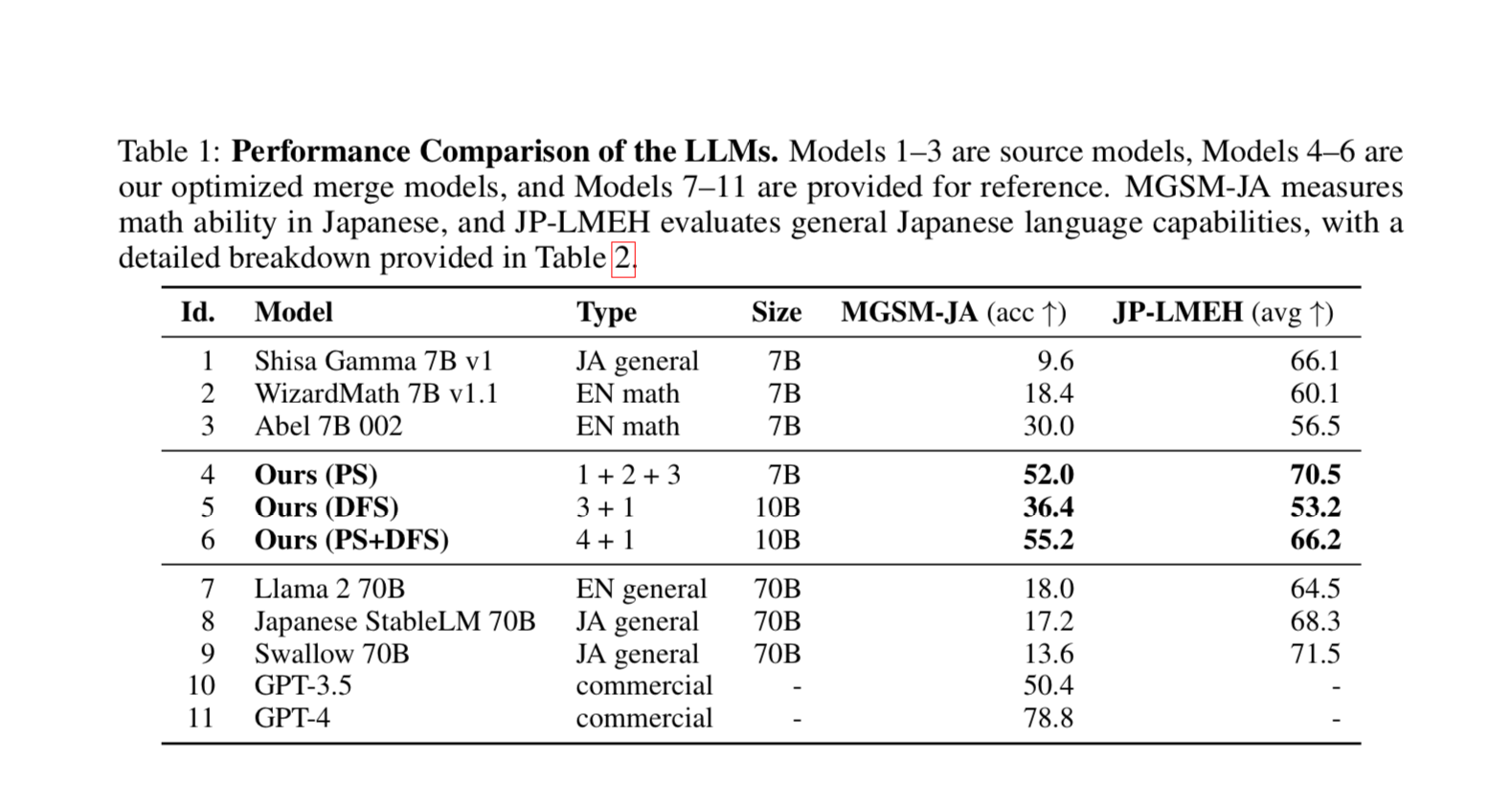
None of the individual models get above 50% but when you merge them together to accuracy sky rockets. The performance beats much larger models and gets on par with GPT-3.5 simply by merging.
From blog post:
This kind of serendipity is a common recurring theme in our explorations when applying evolution to foundation models. As we later see, evolutionary algorithms naturally “just want to work”. We are able to obtain successful results when attempting to apply the approach to other areas such as VLM and diffusion models even at the early stages of experimentation.
What is cool about this approach is you could imagine applying it to the open LLM leaderboard and tasks you are interested in and creating a model that is optimized for your task without any fine tuning.
You could even have human in the loop for the scoring, like the llm-boxing gym ranking the models and merging the top ones together.
They say they use a population size of 128 for a total of 100 generations. The number of offspring usually depends on the number of variables you are trying to optimize and they use 4+(3*log(N))
If they are running the model through 1000 examples the compute bottleneck would be here for us to reproduce, just like we saw in the SRLM paper.
They cite some recent work called Automerge, that takes two random models from the top 20 models on the open llm leaderboard, applies SLERP or DARE-TIES to create new models. Then some of these models will make the leaderboard and become a new part of the population.
I think we need better evaluation techniques than the OpenLLM Leaderboard, but interesting non the less.
Note: These techniques do not only have to apply to LLMs but work with any neural network, vision, generative images, etc. The explosion of fine tunes in the LLM space make this interesting and tractable work.
Limitations
Knowing the training data:

Inheriting the good and the bad: While the evolutionary merging does integrate some diverse expertise, it also does inherit their limitations. There are additional steps one might have to take after a merge to really get the model behavior they want.
Next Up
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.

All the past dives can be found on the blog.
The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI