ArXiv Dives - Depth Anything


This paper presents Depth Anything, a highly practical solution for robust monocular depth estimation. Depth estimation traditionally requires extra hardware and algorithms such as stereo cameras, lidar, or structure from motion. In this paper they create a large dataset of labeled and unlabeled imagery to train a neural network for depth estimation from a single image, without any extra hardware or algorithmic complexity.
Paper: https://arxiv.org/abs/2401.10891
Teams: University of Hong Kong, TikTok, Zhejiang Lab, Zhejiang University
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

These are the notes from our live session, feel free to follow along with the video for context.
What is Monocular Depth Estimation?

Monocular Depth Estimation (MDE) is the process of going from a single image of a scene and creating a depth map. This means for every RGB pixel value, you compute a depth D. The process of collecting data in this format is typically expensive and requires extra hardware such as lidar or stereo cameras.
This paper shows you can build depth maps from single camera stream and a neural network. Some applications of this may seem like science fiction and the barrier to entry has never been lower. The fact that there are open source models that can do things like this continues to blow my mind, and I hope you go out and play with them.
All the code for this project can be found on GitHub and they have models you can download and run on a single GPU at a very high frame rate.
 LiheYoung
LiheYoung
This means in theory you can run their largest model at over 50 FPS on a single GPU.
What is a depth map?
For every pixel in the image, the neural network is then trying to figure out how far away the point is in 3D space. You can think of this as giving you a D value along with every RGB channel.

The image above was run through their demo here and you can see the items closer to the camera are highlighted in a lighter shade than the ones farther away.
What is cool about a depth map, is you can project it into 3D space and turn it into a point cloud.
You can then use this point cloud to interact with digital objects in the real world. For example - here is a demo app I built using the point cloud from the TrueDepth sensor from the front of an iPhone.
This particular depth map required extra hardware to obtain, in this case the structured light sensor on the front of the iPhone.
Crash Course In Depth Sensing Techniques
Traditionally you need extra hardware or expensive compute techniques to be able to get a depth map of a scene. A few popular solutions include Stereo Cameras, Structure from Motion (SfM), and Depth Sensors (LiDAR, structured light, time of flight cameras)
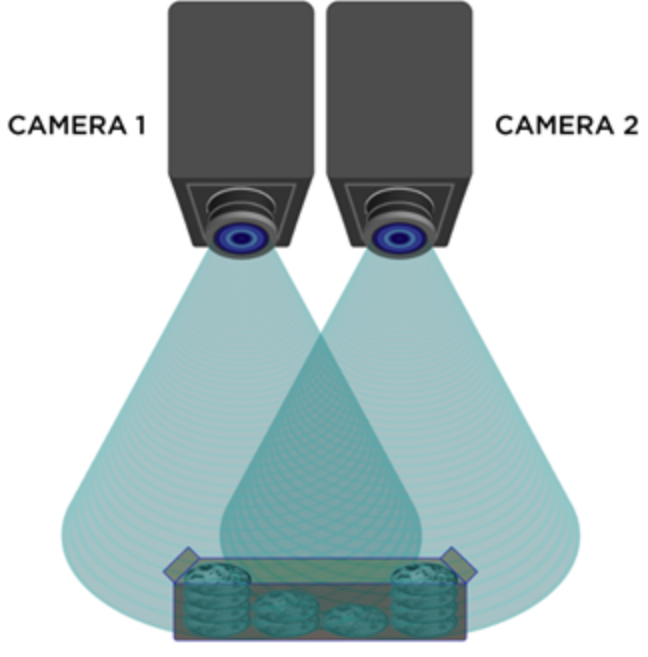
Stereo cameras are inspired by the human eyes, and require you to have two cameras side by side. These two cameras must be calibrated so that you know exactly how far away each camera is from each other. This allows you to triangulate points that match in each image.
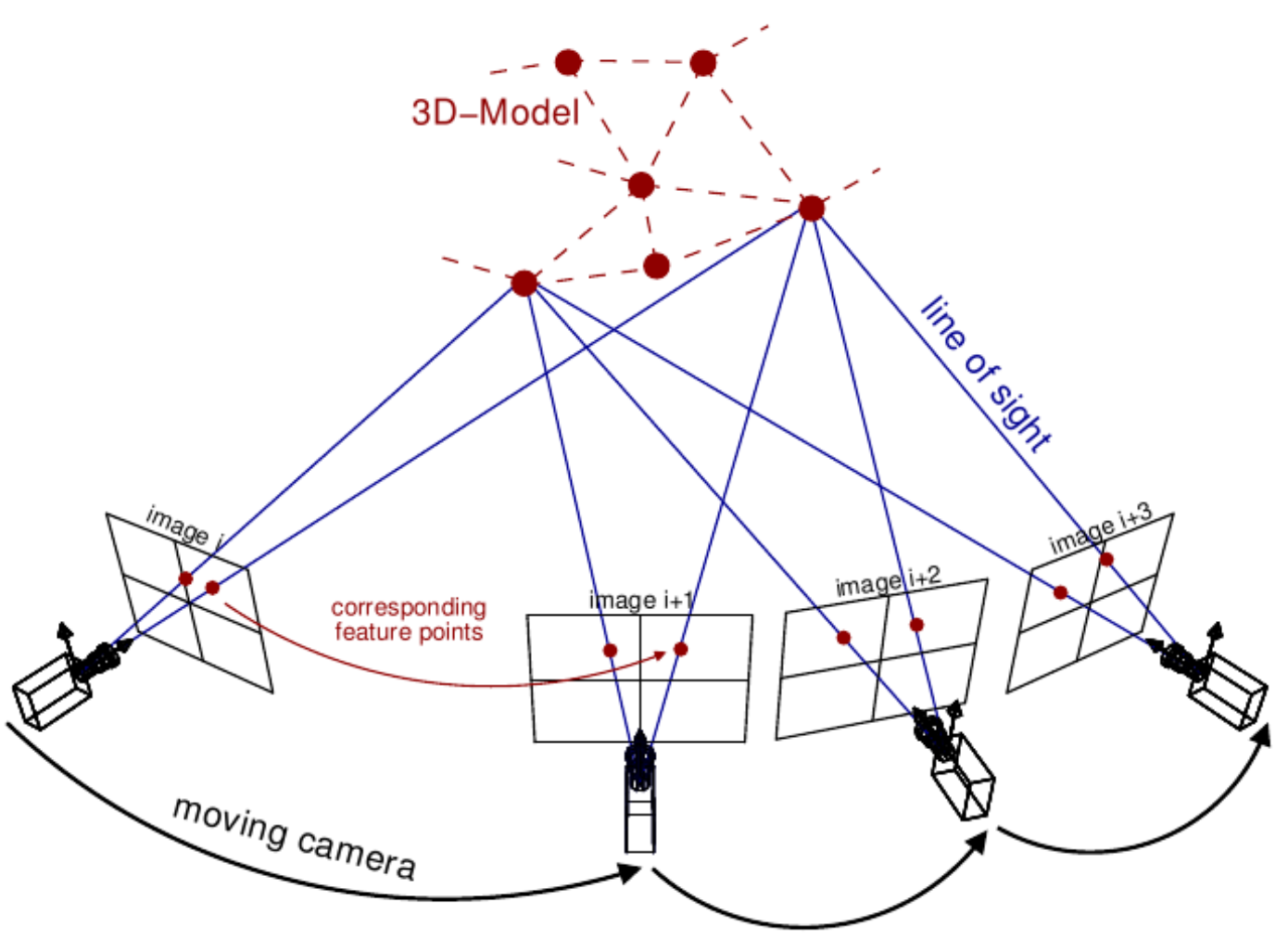
Structure from motion is a technique that similarly uses the ability to find corresponding points in sets of images. You must both estimate where the camera is and what points match in this case which can be a computationally expensive and hard to accurately compute for scenes like a large white wall. If you think of a white wall, there are no distinct features that can be matched between the images in order to triangulate.
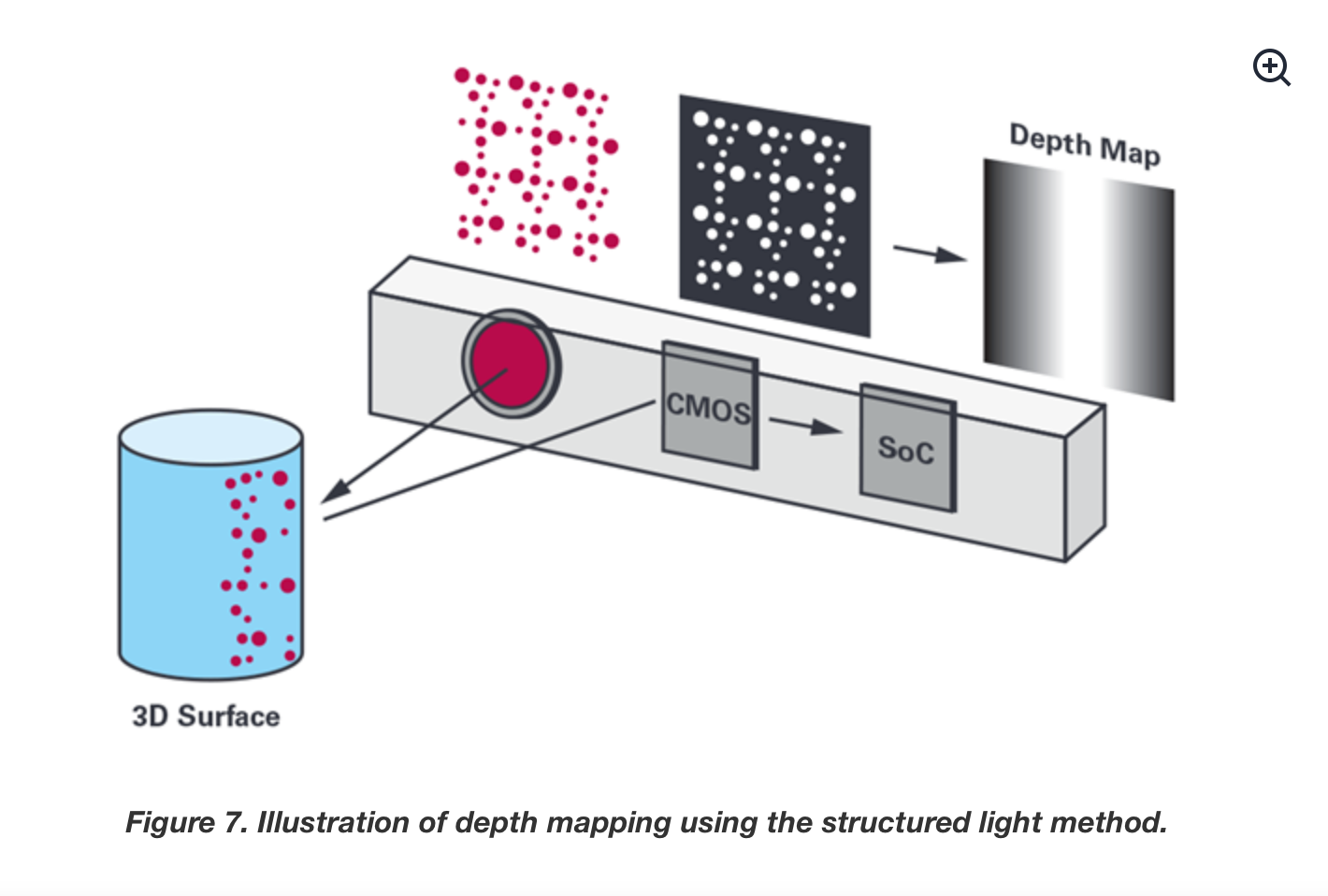
Depth Sensors such as time of flight sensors, structured light sensors, and LIDAR solve the problem with surfaces that have no distinguishing features from another by projecting light that the human eye can not see onto the scene. Then they use infrared cameras or the time it takes for the light to bounce back to compute depth information. These sensors can be expensive and have problems of their own. It is an on going debate whether self driving cars should be able to operate solely by cameras or adding additional sensors for more accurate sensing.
The ability to be able to do depth estimation from a single camera and RGB image would save a lot of money and reduce the barrier to entry for a lot of applications that require 3D knowledge about the world.
Depth Anything
To solve for the problems above, this paper trains a foundation model for Monocular Depth Estimation being able to go from a single RGB image to a depth value for every pixel in that image. Traditionally it has been difficult to create datasets for this task - because it requires calibrated sensors to collect tens of millions of image-depth pairs.
This paper is really a paper about a synthetic data engine, and a clever loss function to allow the scaling of data without further labeling. This seems to be a pattern lately that is important to take note of. All of these synthetic data papers have important steps within them to use an existing network to label more data without humans in the loop, but they always have some sort of filtering technique or additional loss metric to make it all work in practice.
Previous work had been done to collect a massive labeled dataset and train a model called MiDaS that they make many references to and comparisons to in the paper.
In order to create a proper dataset - they create a “data engine” for unlabeled images, enabling data scaling-up to an arbitrary scale. This is similar to the work in Segment Anything where they start with a smaller labeled dataset and progressively train models to automatically annotate the unlabeled images.
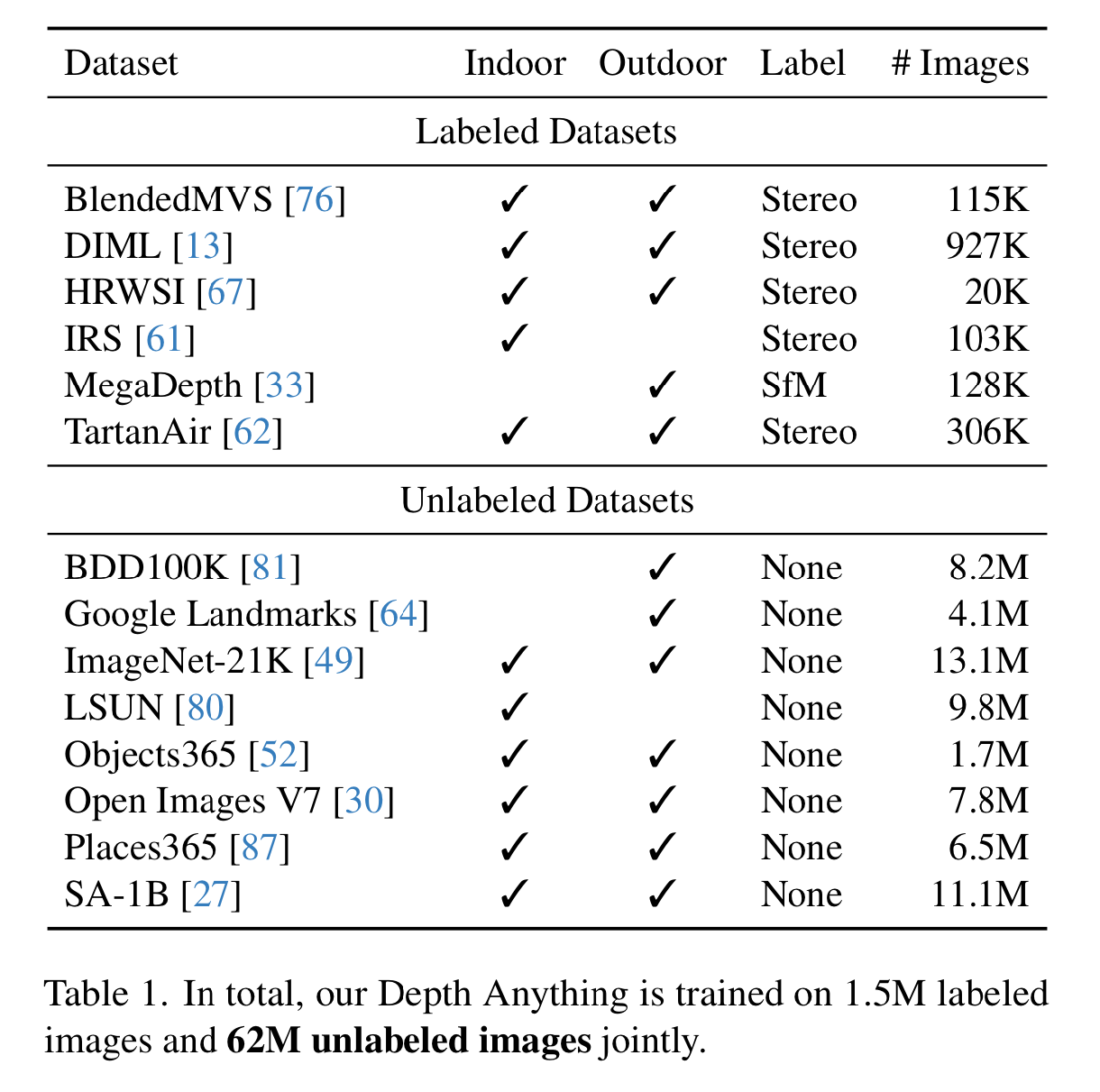
They claim that leveraging raw unlabeled images in their pipeline increases the models ability to generalization and robustness to new images. In total, they collect a total of 1.5 million labeled images and 62 million unlabeled images from a variety of datasets.
Unleashing the Power of Unlabeled Images
They started by training a base depth estimation model which uses DINOv2 as the image encoder then use a Dense Prediction Transformer (DPT) decoder for the depth estimation. This is your standard encoder-decoder architecture we have come to know and love in neural networks.

The DINOv2 backbone as the encoder gives the model a great starting point for depth estimation as well as semantic segmentation and many other computer vision tasks it was trained on. The DINOv2 paper would make for a great dive in itself.
They start by training an initial encoder-decoder model on the 1.5 million labeled images for 20 epochs. This is called the “teacher” model. Then they use this trained “teacher” model to annotate all the unlabeled images.
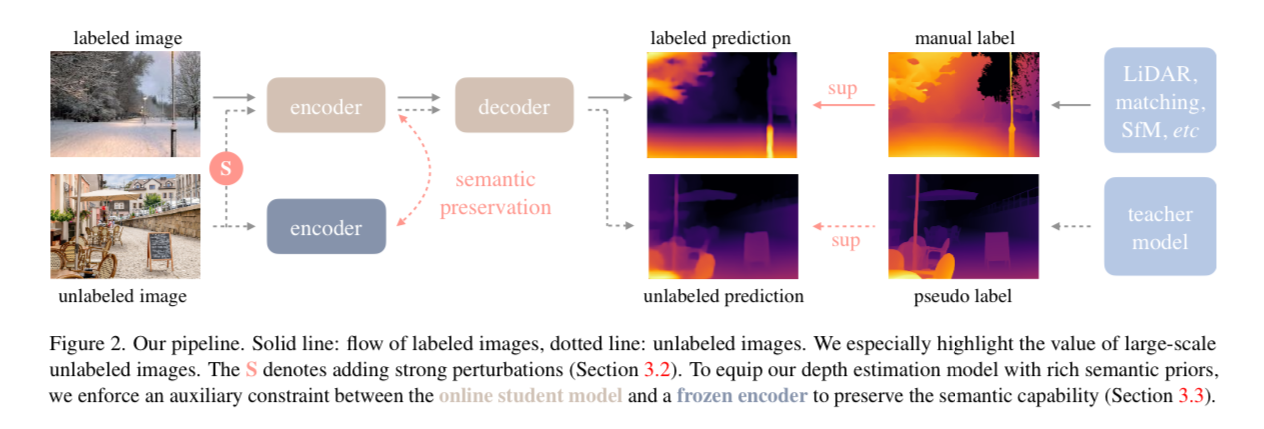
Once they have the new set of labeled images, they train a "student" model given a mix of the labeled and unlabeled data. The ratio of labeled to unlabeled images in each batch is 1:2. Now in theory they have a much larger dataset of labeled images - they have just been "pseudo labeled" by the teacher model instead of from ground truth hardware sensors.
Learning from the Teacher Model
The problem is you are not going to make the student better than the teacher model by simply training on the pseudo labeled data. Yes they are more diverse images, but the same mistakes the teacher makes will now be learned by the student. To address this problem, they add additional optimization challenges to the student:
- Strong perturbations to the unlabeled images during training (color distortions, Gaussian blurring, and other distortions like CutMix)
- Auxiliary semantic segmentation feature alignment loss
The data augmentation includes many of the standard tricks in computer vision like flipping the images, adding gaussian blur, and cropping and mixing data.

Specifically they mention a technique called CutMix which has been shown to increase the performance of many computer vision models.
The second technique of a "semantic segmentation feature alignment loss" is a little more interesting. They have intuition that knowledge about semantic segmentation would help depth estimation, since different classes of objects would likely be at similar depths.

First they tried having the same model try to predict both semantic segmentation and depth values. Unfortunately they did not get this technique to improve performance over the original depth estimation model. Their intuition was that decoding the image into the discrete class spaces loses too much information while decoding.
To combat this they instead add a “feature alignment loss”.

They take a frozen DINOv2 encoder which has been shown to perform well on a variety of tasks.
Then they ensure that an internal feature vector from the depth model we are training aligns to a feature vector in the DINOv2 encoder. They use the cosine similarity between the two feature vectors and make sure that they have a high similarity.
This means they have the original objective of predicting depth as well as the auxiliary objective of aligning feature vectors with a model that is good at semantic segmentation.
Since they also use DINOv2 for the encoder they are training - this reminds me a little of DPO where they want the downstream model’s capabilities to align closely with some original model’s capabilities, in this case the semantic knowledge such as segmentation. Feel free to read our post on DPO to get a better sense of what I mean here.
Evaluation
There are 6 datasets that they left out of the labeled data for the model in order to evaluate. KITTI, NYUv2, Sintel, DDAD, ETH3D, and DIODE.
What’s interesting is other labeled approaches include these datasets in their training data and split some out for testing. DepthAnything left all these datasets out of the labeled data, claiming “zero-shot” capabilities on the out of domain data.
They compare the model against the best model from MiDaS v3.1, which was trained against more labeled data than DepthAnything (MiDaS looks like it had ~3 million labeled training images vs DepthAnything’s 1.5 million)
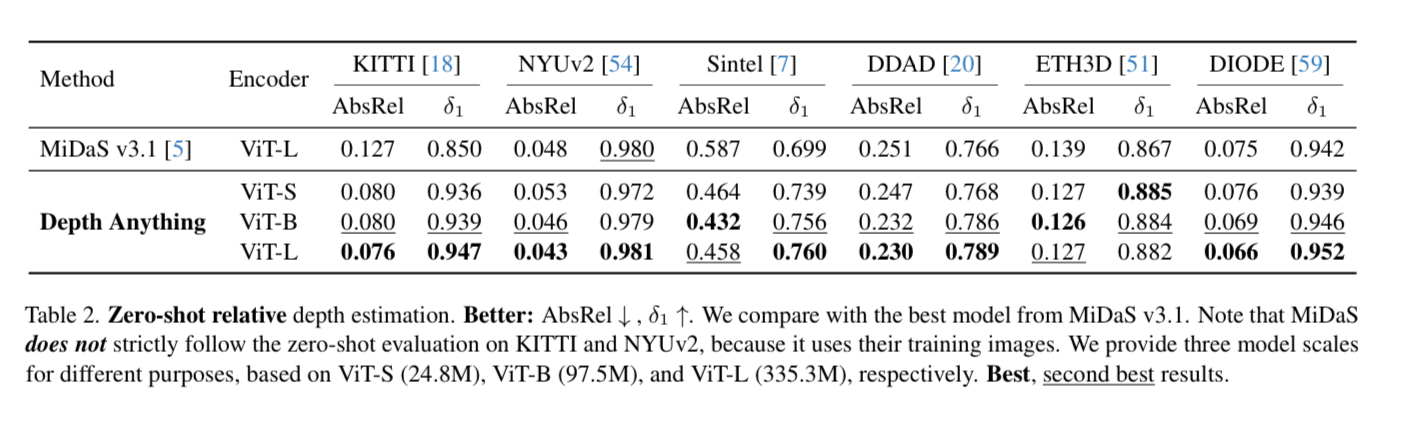
What’s more is even the ViT-S (smol) model which is 1/10th the size of MiDaS outperforms on several unseen datasets (Sintel, DDAD and ETH3D)
Since they include the “semantic priors” in the loss function for training the model, they also fine-tune the model to do semantic segmentation and show that they improve state of the art on the ADE-20k dataset.
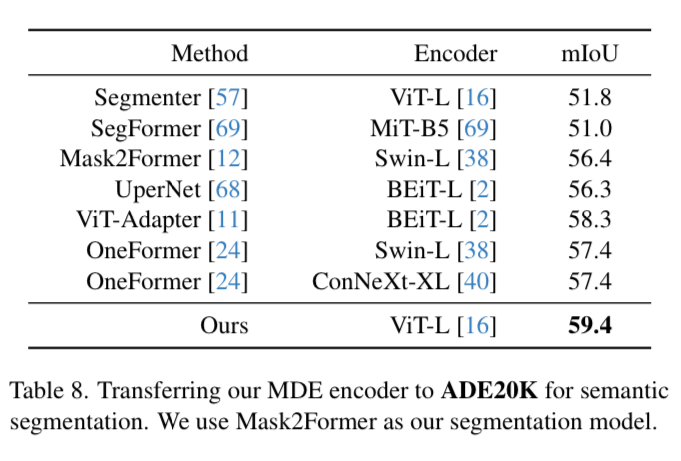
Their hope here is to highlight the superiority of their pre-trained encoder on multiple tasks and that DepthAnything can be a backbone for many visual perception systems.
Ablation Studies
Training data subsets
They decided to train 6 versions of the model using one subset of the training data at a time.
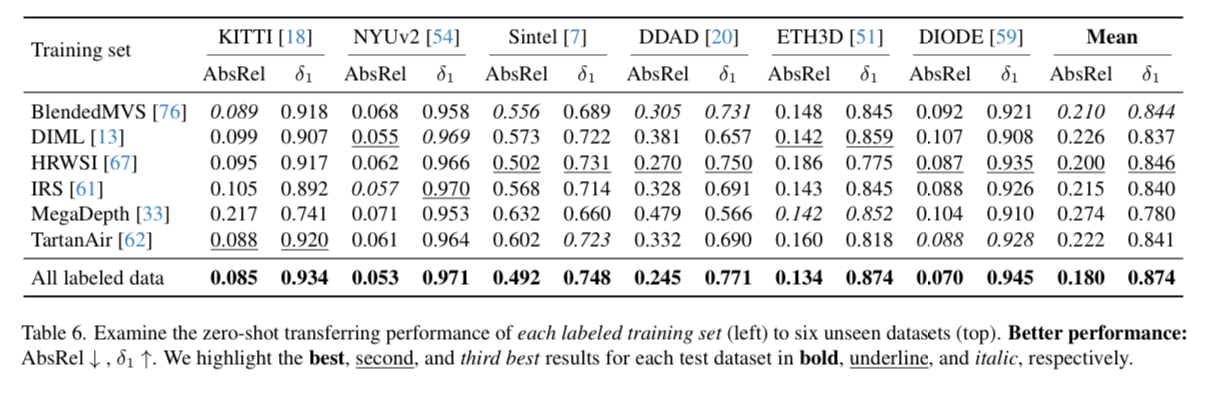
Then they evaluate each version against the set of evaluation datasets. What’s interesting here is that the HRWSI dataset scores highest across a wide variety of the test sets, even though it only contains 20k images. Check out this dataset on Oxen.ai to see the kind of images contained in the dataset:
This means dataset diversity counts a lot. Quality and diversity is all you need.
Labeled Data, Unlabeled Data, Strong Perturbations, Feature Loss
Earlier we mentioned that just mixing in the unlabeled data alone did not bring any gains to the model. It was the combination of the data plus the data augmentation plus the feature loss that really gave the model a boost.
It actually got worse in many of the cases when you just added the unlabeled data.
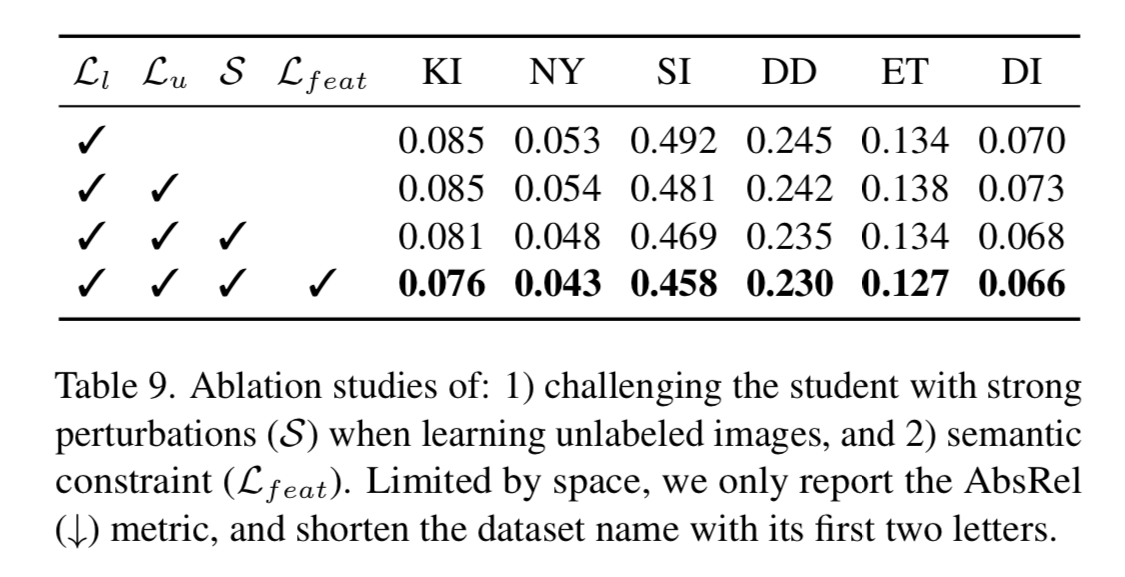
I was wondering what would happen if you added the perturbations and the feature loss to purely labeled data, and they answered this in section 7
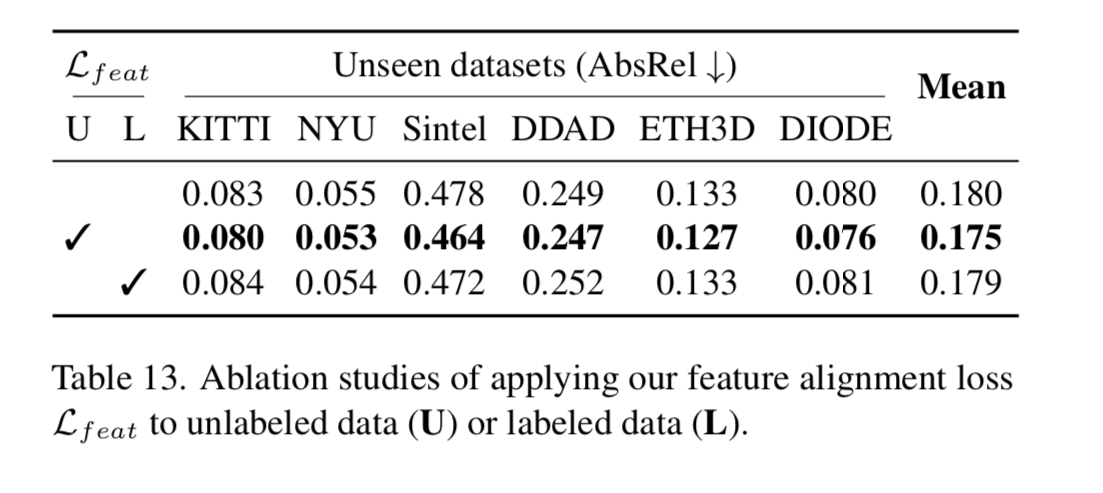
It does indeed only help if you add the unlabeled data and this feature loss together.
They say this is because the labeled data already has high quality depth annotations, where the pseudo labeled data may have some mistakes, be noisier and less informative. Adding the auxiliary constraint to with the unlabeled data can arm the model with other semantics in order to combat the noise.
Comparison with DINOv2
The performance on depth estimation also improves vs the baseline DINOv2.
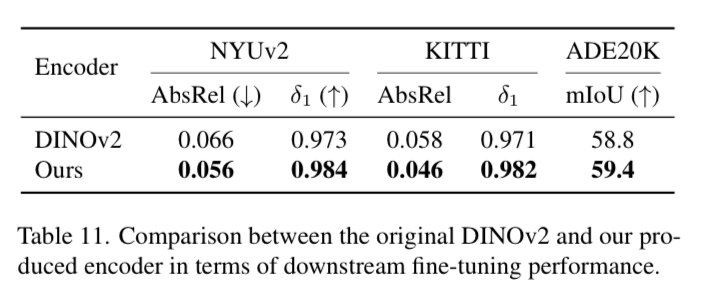
Since they use DINOv2 as the starting point for this model, and include it as the frozen encoder in the loss function, they show that this technique improves on downstream fine-tuning tasks.
Qualitative Results
There are many impressive qualitative examples in this paper with very complex scenes.

There are many more in the back of the paper if you are curious.
Limitations
The largest model they trained was ViT-Large, and they state that it would be interesting to train a more powerful teacher with a larger model (ViT-Giant).
Also everything was trained on 512x512 images, which isn’t super high resolution, so may not give practical depth maps for real world applications. They plan to retrain on larger resolution of 700 or 1000+.
My last question is the fact that every one of these datasets have different camera parameters - which means the scale of the depth is going to be different. How do they guarantee that the depth map which they normalize from zero to one generalizes to the new camera you took the photo from? In other words, what is the formula for going from the values of 0.0-1.0 to real world 3D coordinates?
If you have an answer to the above question, please join our discord and let us know!
Conclusion
It was fun to take a break from LLMs this week and go back to my augmented and virtual reality days to see how far the technology has come. I would love to see someone try to take this DepthAnything work and see how well it works in the real world for applications like augmented reality, special effects, generative images, or 3D reconstruction from 2D images.
Next Up
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
Oxen-AI