Arxiv Dives - Toolformer: Language models can teach themselves to use tools

Large Language Models (LLMs) show remarkable capabilities to solve new tasks from a few textual instructions, but they also paradoxically struggle with basic functionality such as math, dates on a calendar, or replying with up to date information about the world.
As software engineers we have already solved these subset of problems with other tools such as a calculator, calendar or search and retrieval systems.
This paper introduces a model they call the Toolformer which has been trained to use external tools. The Toolformer decides which APIs to call, when to call them, and what arguments to pass in order to better answer user’s queries.
Paper: https://arxiv.org/abs/2302.04761
Team: Meta AI Research, Universitat Pompeu Fabra (Barcelona, Spain)
Date: Feb 9th, 2023
ArXiv Dives
Every Friday at Oxen.ai we host a paper club called "ArXiv Dives" to make us smarter Oxen 🐂 🧠. We believe diving into the details of research papers is the best way to build fundamental knowledge, spot patterns and keep up with the bleeding edge.
If you would like to join live to ask questions or join the discussion we would love to have you! Sign up below 👇

The following are the notes from the live session. Many thanks to the community asking great questions along the way. Feel free to watch the video and follow along for the full context.
Toolformer
The Toolformer architecture lets the use of tools be learned in a self-supervised way without requiring large amounts of human annotations. Once the language model learns to use tools, it should be able to decide when and how to use which tool, while maintaining it’s general knowledge about language.
The 5 tools they enable in this paper are:
- Question answering system
- Wikipedia search engine
- Calculator
- Calendar
- Machine translation system
Approach
Each tool that is available to the Language Model is represented by an API call. Since the language model is simply predicting sequences of text, they represent each API call as a text sequence.

Creating the Training Data
They create synthetic data bootstrapped with plain text sequences and augment them with API calls.
Three Steps
- Use N-shot prompting to generate some synthetic data with candidate API calls
- Execute these API calls and augment an existing language modeling dataset
- Filter the generated data by checking whether the obtained responses are helpful for predicting future tokens (they have a fancy filtering metric for this step)
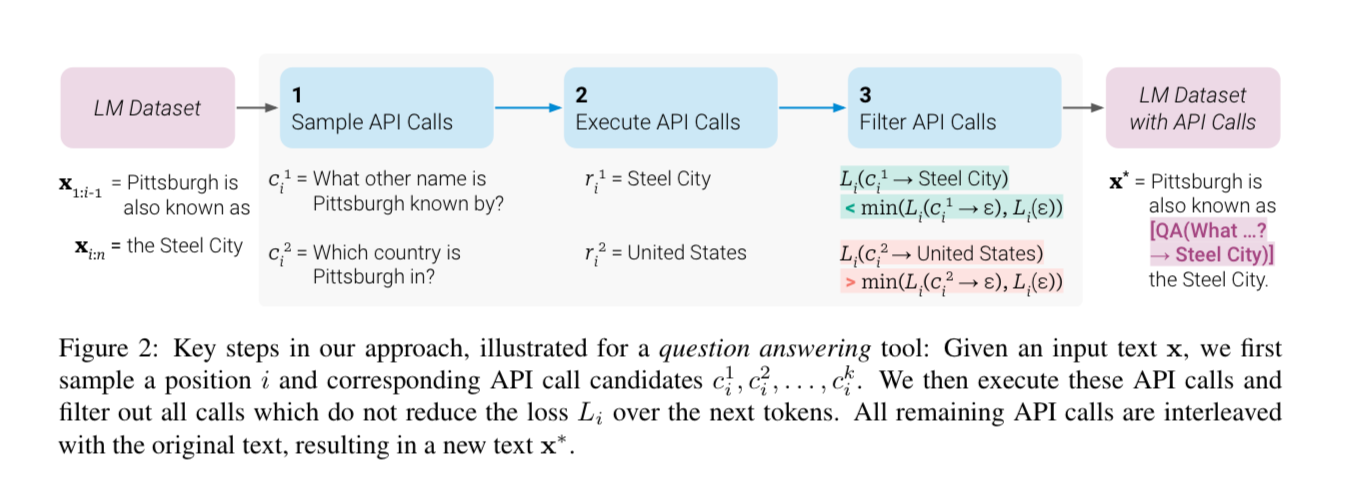
Injecting API Calls
The first step in generating the dataset is taking a random passages from your corpus like:
“Pittsburgh is known as the Steel City”
and injecting API calls in the middle of the sentences. The API calls should help you get information required to complete the text. You can call the API by writing [QA("what is xyz...")] where "QA" is the API you want to call.
They inject this data with an existing base LLM and N-shot prompting. An example prompt looks like:

They have a specific prompt for each tool they want to generate data for. All the prompts can be found in the appendix. In order to get the passages to augment, they start with a corpus called CCNet. You could use and corpus of text for this step such as Wikipedia, The Pile, Red Pajama, etc.
Since each passage may require certain tools, they use some heuristics to make sure each tool gets relevant text. For example, they only consider texts for the calculator tool if it contains 3 or more numbers in a window of 100 tokens and also contains an = sign, “equals” “equal to” “total of” “average of” followed by a number.
Executing API Calls
Once they have augmented passages that meet the criterion for each tool, they create 3 variations of the passages.
- the original passage, without api calls
- the passage, with the api call (but without a response filled in) - tool1(x,y)
- the passage with api call and the response filled in - tool1(x, y) → {response}
Examples of the third variation of fully flushed out passages with apis, parameters, and responses are in Table 10
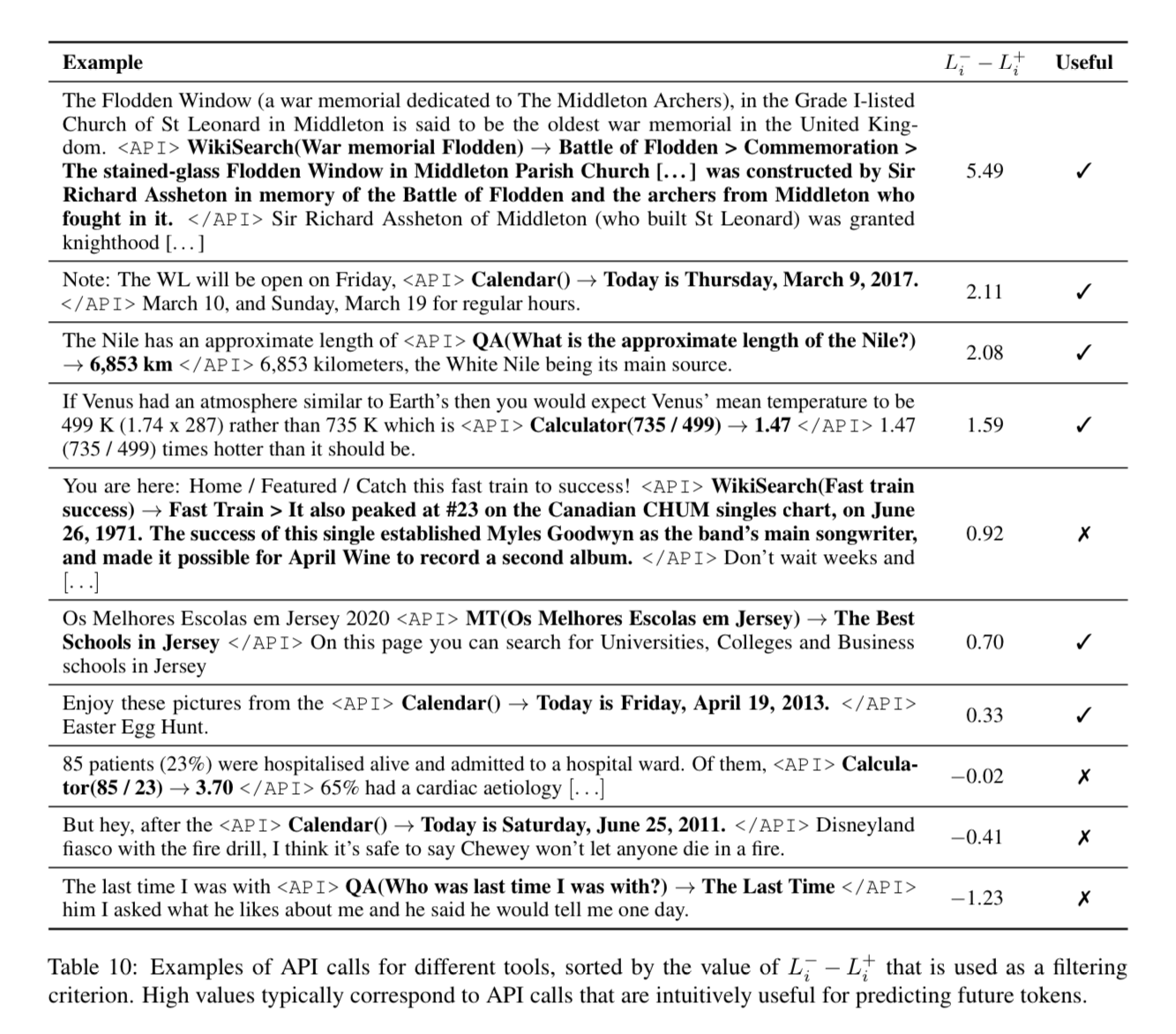
Note: although they use the strings <API> and </API> in these examples they actually just use [ and ] in practice.

Filtering API Calls
Each synthetic generated API call is not guaranteed to be helpful, since we are just starting with a corpus of data with some heuristics. The main novelty of this paper is defining this “fitness score” to filter which API calls we add to the dataset.
Don't let the math intimidate you, the score is relatively straight forward once you get past the greek letters.

Let's take an example passage:
During ArXiv Dives on Friday, February 9th, 2024 we will be going over the Toolformer paper.We want the model to inject tool usage after Friday, in order to look up what the current date is.
During ArXiv Dives on Friday, [Calendar() → 02/09/2024] February 9th, 2024 we will be going over the Toolformer paper.Under the hood a language model is predicting each token and gives a probability distribution associated with what token should come next. Taking the highest probability token would look something like this:
During (0.6) Ar (0.9) _Xiv (0.7) Dives (0.8) …Going back up to our equation, we are simply summing over the log probabilities of tokens given the previous token and some weighting.
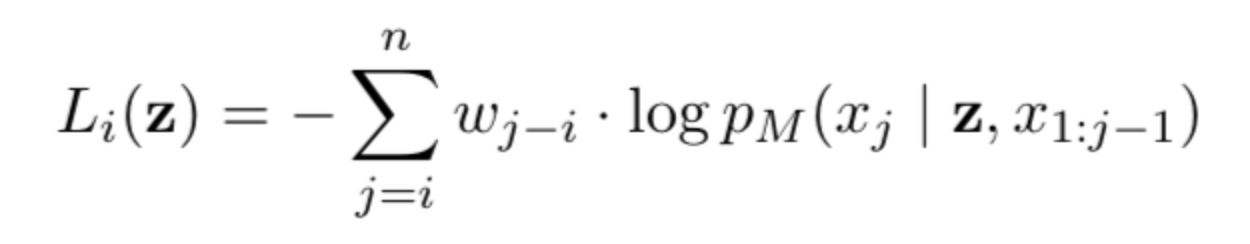
They split the sentence into before you add the API call and after
X1:j-1 = During ArXiv Dives on Friday
Xj = February 9th, 2024 we will be going over the Toolformer paper.Then have a z which could either be
- Empty
L_i(e) - The API call with no response
L_i(e(c_i, E)) - The API call with the response
L_i(e(c_i, r_i))
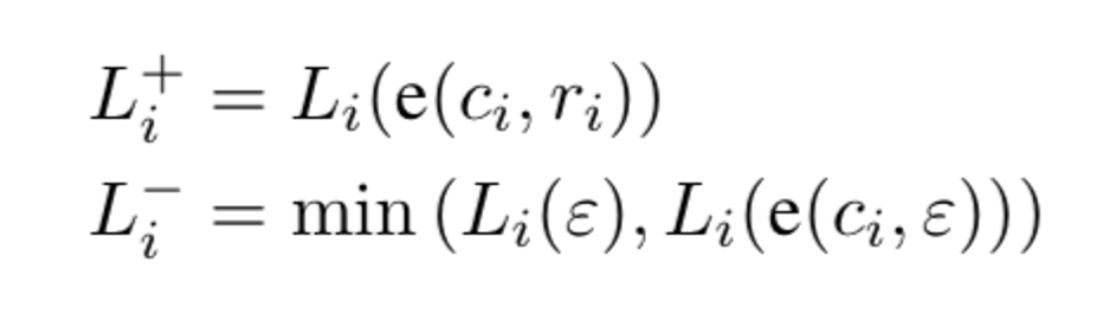
Then they filter any generated passage with an API call that does not add relevant information for predicting the surrounding words. If adding an empty string or the API call without a response allows you to predict the next words with higher probability than making the API call itself, do not add the API call.
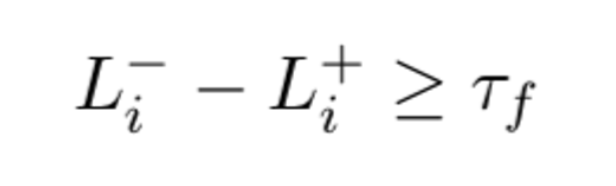
If you are wondering about the weighting mechanism

They make it so the score is only affected by the 5 next tokens with 1-0.2*t which is a hyper parameter you could choose.
If you want to look at the implementation of the math in practice, check out this github repo, I linked directly to the filtering function:
Model Fine Tuning
After they have augmented the data and filtered it down to API calls that actually help complete the passages, they simply fine-tune the model on this dataset with the standard language modeling objective of predicting the next token in a sequence.
The base model they start with is GPT-J which is a 6B parameter model trained on The Pile dataset and can be found on Hugging Face.

You could train any open source model you wanted here, and I'm sure by the time you read this post there will be many high quality base models to choose from.
Inference
Once you have this fine-tuned language model that can predict when it needs to make an API call, they perform standard decoding until the model produces the → token, indicating that we need to go make the API call. At this point they stop to decoding process, make the API call, insert the result into the context window, and continue decoding.
Experiments
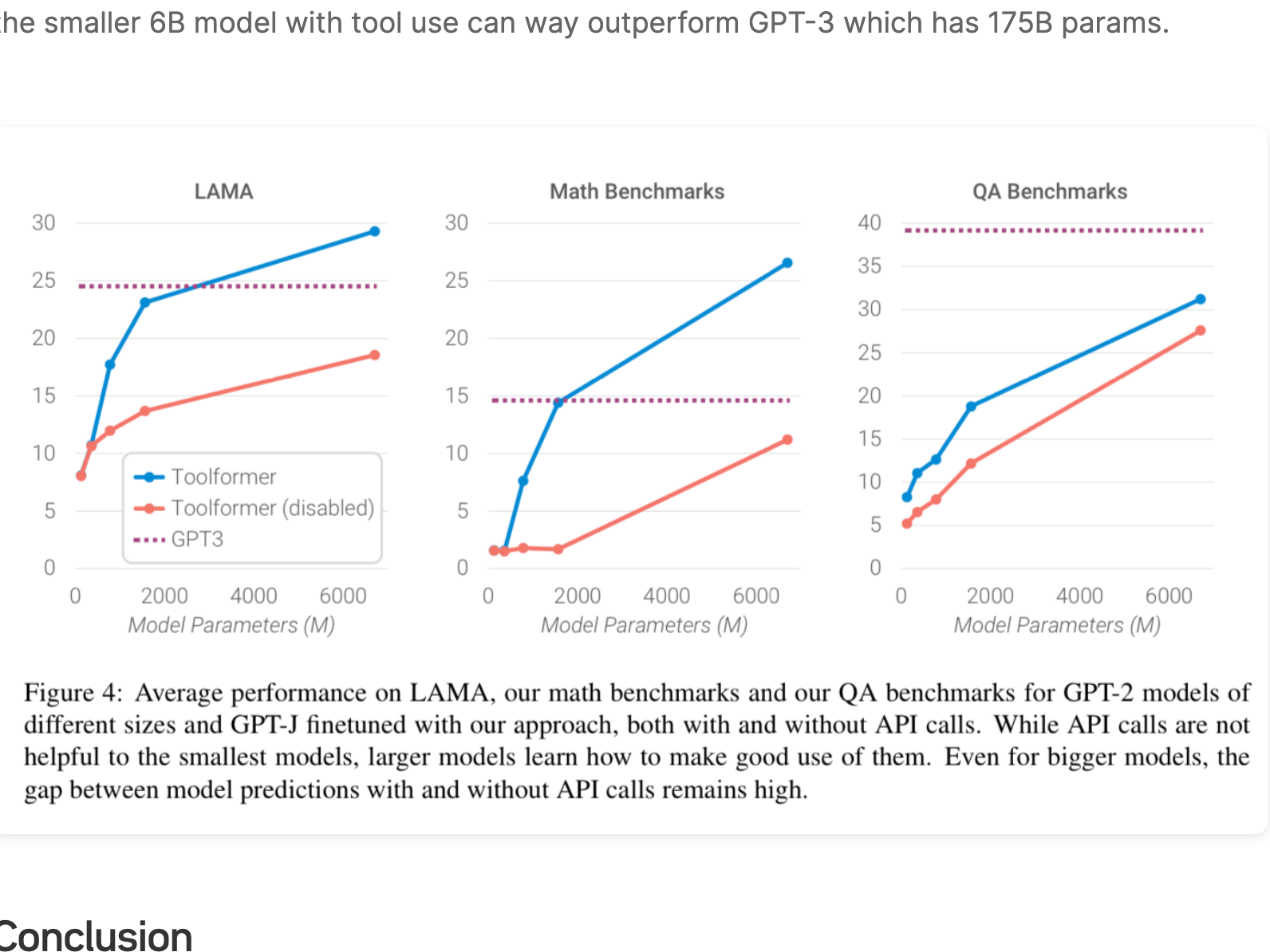
In their experiments, they want to see if the model can decide for itself when and how to call any of its available tools, as well as maintain it’s core language modeling abilities. The biggest boost in performance was on Math benchmarks, which makes sense given the nature of the problems. Question answering, translation, and other language modeling tasks do seem to get better as model scale increases.
Starting with Question Answering + slot filling type tasks, the see how well different models perform with zero shot prompting. The smaller fine-tuned Toolformer significantly beats the baseline and starts to become competitive with much larger base language models such as GPT-3.
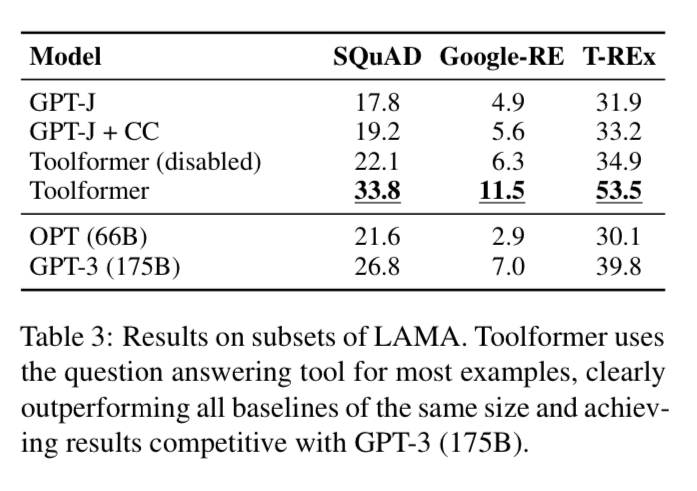
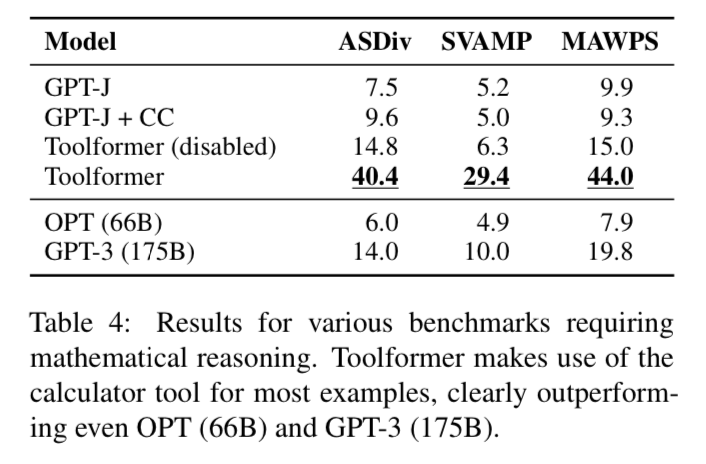
Math
Math is the biggest jump in performance compared to other tasks, which makes sense. To get a sense for the Math word problems we uploaded the ASDiv dataset here:
You can see the Toolformer blows models with much larger parameter counts out of the water on the math benchmarks.
Scaling Laws
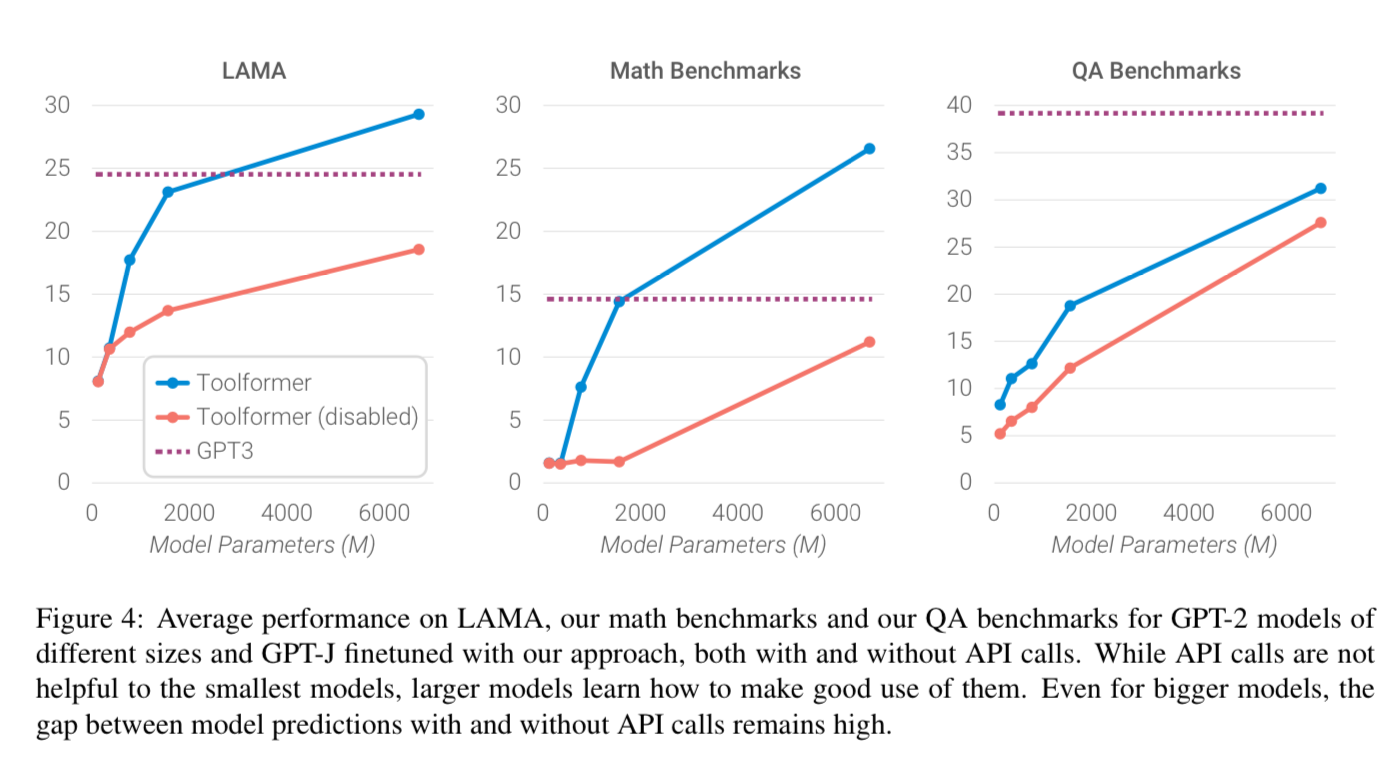
They also perform a fine tuning on the suite of GPT-2 models with 124M, 355M, 775M, and 1.6B parameters respectively.
They state that the ability to leverage the provided tools only emerges around the 775M parameter count. The smaller models achieve similar performance with and without tools. But the smaller 6B model with tool use can way outperform GPT-3 which has 175B params.
Conclusion
The Toolformer is a natural extension of a base transformer language model to add the ability to use external APIs and tools. All you need to do is fine tune the model with training data that contains sequences that represent which API you want to call, as well as the parameters to the API. The biggest contribution of this paper was the training data generation and data filtering techniques. Beyond that, it is a standard fine-tuning of a base language model.
Models such as OpenAI's GPT-4 have been likely trained in a similar fashion to enable features such as function calling to integrate into your existing tools.
Next Up
To continue the conversation, we would love you to join our Discord! There are a ton of smart engineers, researchers, and practitioners that love diving into the latest in AI.

If you enjoyed this dive, please join us next week live! We always save time for questions at the end, and always enjoy the live discussion where we can clarify and dive deeper as needed.
All the past dives can be found on the blog.


The live sessions are posted on YouTube if you want to watch at your own leisure.


Best & Moo,
~ The herd at Oxen.ai
Who is Oxen.ai?
Oxen.ai is an open source project aimed at solving some of the challenges with iterating on and curating machine learning datasets. At its core Oxen is a lightning fast data version control tool optimized for large unstructured datasets. We are currently working on collaboration workflows to enable the high quality, curated public and private data repositories to advance the field of AI, while keeping all the data accessible and auditable.
If you would like to learn more, star us on GitHub or head to Oxen.ai and create an account.
 Oxen-AI
Oxen-AI