🌲 Merkle Tree 101


Intro
Merkle Trees are important data structures for ensuring integrity, deduplication, and verification of data at scale. They are used heavily in tools such as Git, Bitcoin, IPFS, BitTorrent, and other popular distributed collaboration tools. When we started working on Oxen we decided to build our own Merkle Tree from scratch so we had full control over performance down to the hashing algorithm, read/write access patterns, network protocols, and format on disk.
Why should you care?
You probably use version control like Git every day, but may have never thought about how it works under the hood. Even a basic understanding of Merkle Trees will make the concepts of the tools like Git sink in. In turn, it will make you a better developer and software engineer. That or maybe you are like me and simply enjoy The Pleasure of Finding Things Out. Either way - if you enjoy this post, let us know on our Discord or by tagging us on your social of choice @oxen_ai or @gregschoeninger.
This will be a series of posts that starts with Merkle Tree basics and builds up to some tips and tricks we use to make them blazing fast in the Oxen.ai toolchain. If you don’t have any idea how versioning works under the hood, or are just curious about Merkle Trees, this is the post for you.
What is a Merkle Tree?
A Merkle Tree is a data structure in which every node contains data and a hash. The hash value of each node is computed recursively by hashing all the values of the children. If a node is a leaf node, the hash is computed from the content of some data. Once you bubble up the hashes to the root, you’ll have a unique hash that can identify the state of the data.
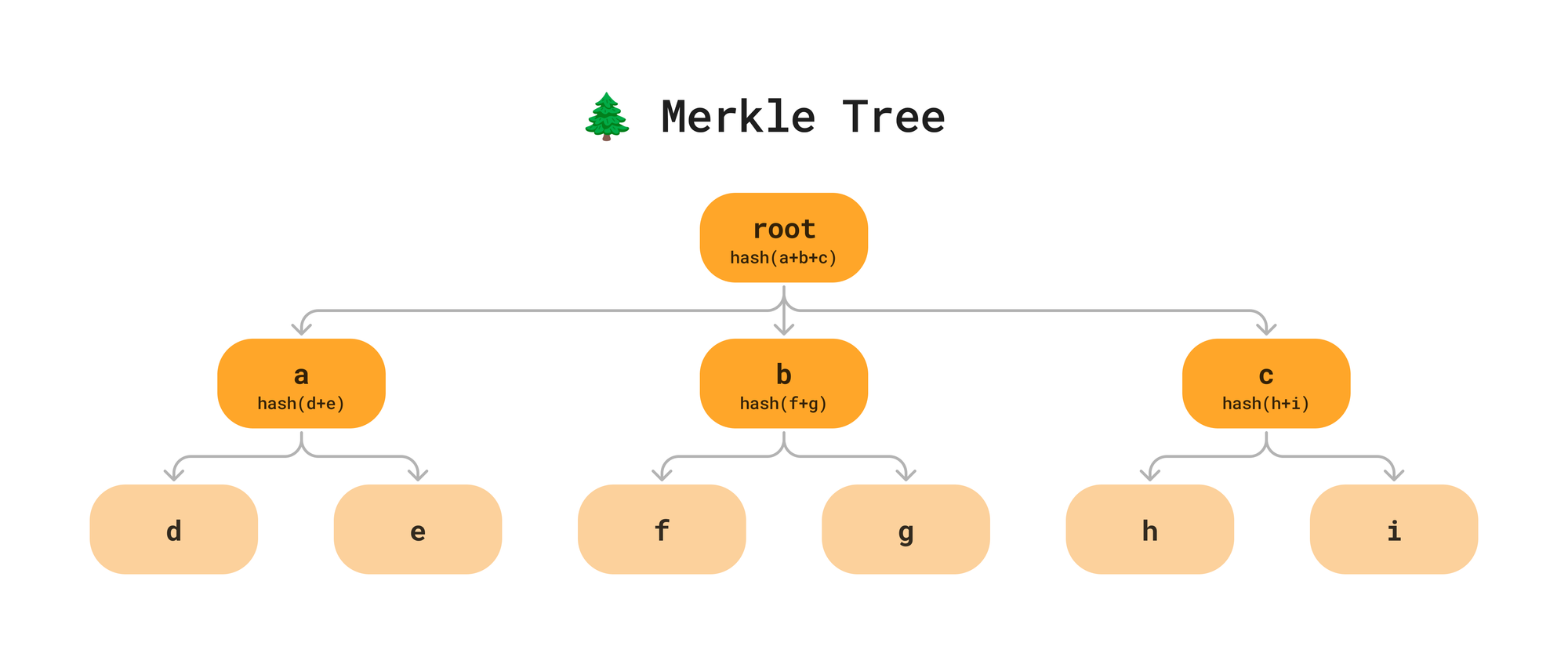
This data structure is an efficient structure to verify, deduplicate, and keep track of changes to data. Rather than describing it in theory, let’s see how works in practice by applying it to the problem of versioning a file system.
File System As A Merkle Tree
Here is a small file system we will use as an example. We have a root directory at the top, an images/ directory, and 5 files split between the two directories.
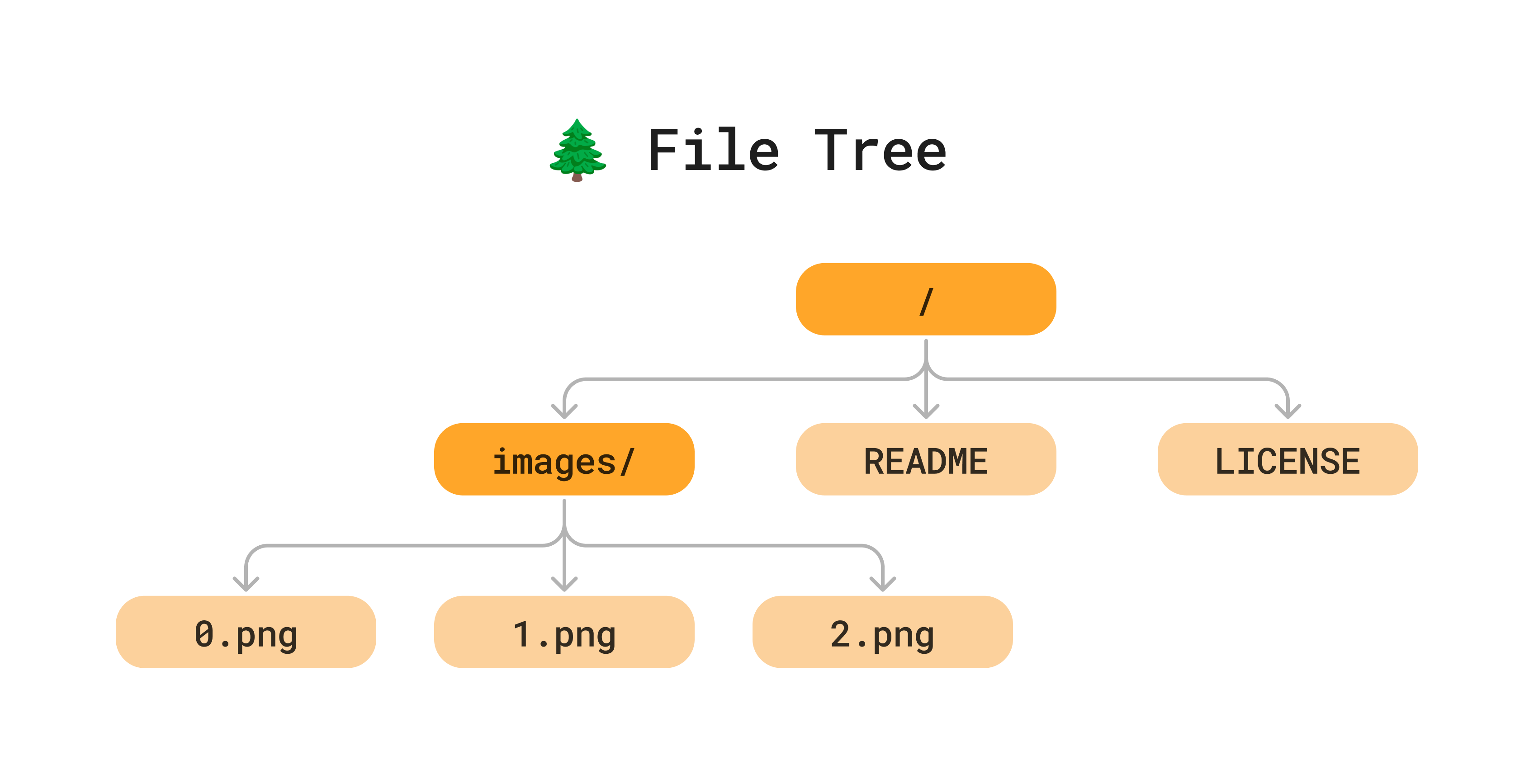
Since files and directories on disk are naturally represented as a tree, all we have to do to turn it into a Merkle Tree is add content hashes to each node.
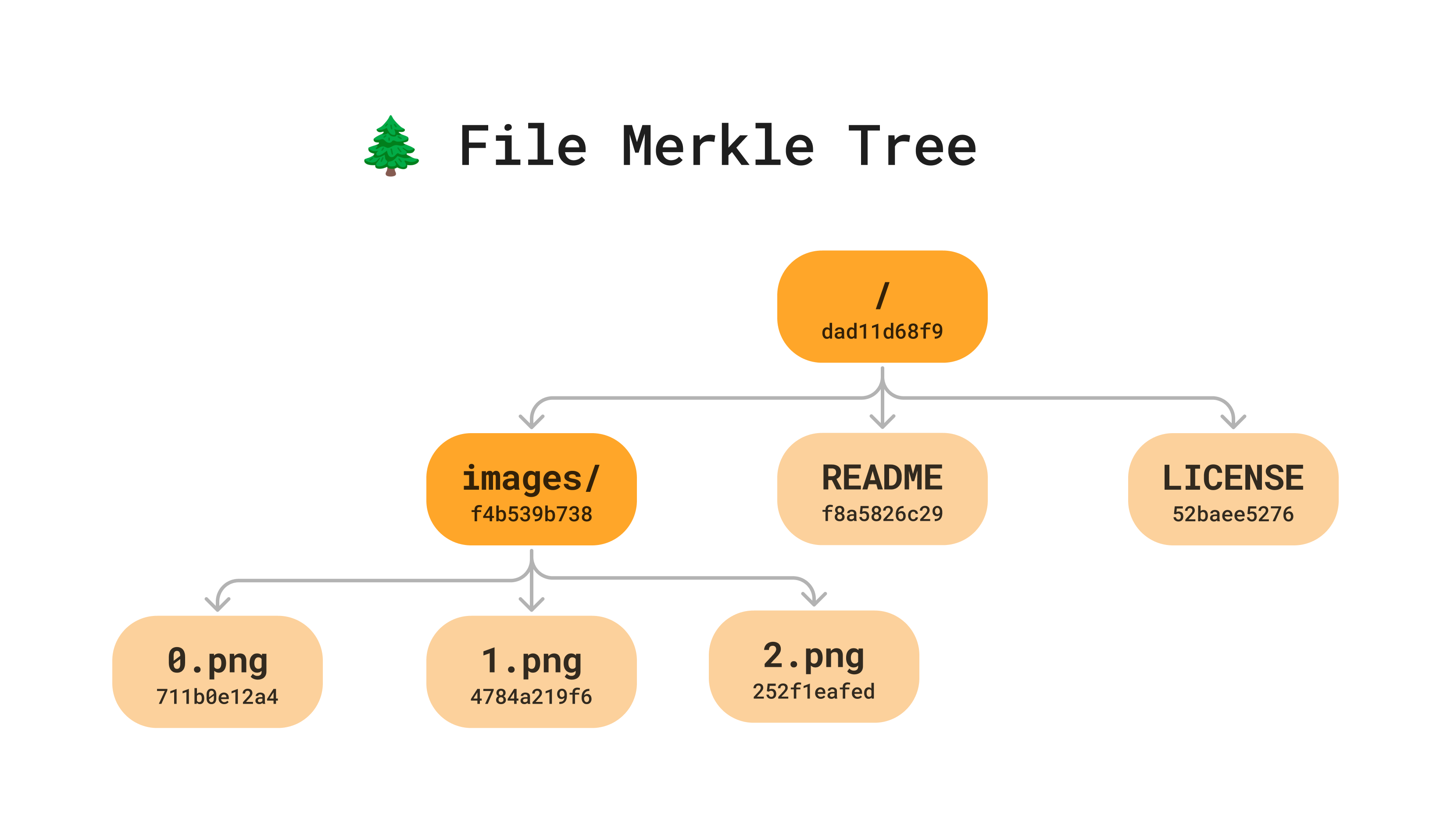
For the content hashes, we start at the leaf nodes (the files) and compute the hash based on the content of the file.
hash(0.png) == "711b0e12a4"
hash(1.png) == "4784a219f6"
hash(2.png) == "252f1eafed"Version control tools like git use sha256 to hash their nodes. If we were computing the sha256 hash for 0.png with a simple bash command, it would look like:
cat images/0.png | sha256With oxen you can view the hash of a particular file with the oxen info command.
$ oxen info README.md
f8a5826c29ad90d63f4e5216b5362e6f 7 text text/markdown md NoneOnce we have the hash of the files in a directory, the hash of directory is the combined hash of all it’s children.
hash(images) == hash(hash(0.png),hash(1.png),hash(2.png)) == "f4b539b738"Then we can recursively compute hashes until we get to the root.
The Power Of The Hash
This hash field is a small but powerful change to our file system. It may not look like much, but it will be the cornerstone of a versioned database of changes.
The Merkle Tree representation of the file system now allow us to:
- Create Unique Identifiers (Branches/Commit Ids)
- Deduplicate File Content
- Detect Atomic Changes
- Minimize Data Syncs
- Ensure Data Integrity
We will dive into each one of these benefits with some examples to bring the concepts to life.
Unique Identifiers (Commits, Branches & File Versions)
Let’s build up a repository from scratch start to see how all these concepts tie into creating commits, branches, and tracking different versions of files. First we will add a single README to our tree.
echo "# Merkle" > READMEWhen the file is added, we will need to compute the hash of the file contents itself.
hash(file_contents(README)) == hash("# Merkle")Since this file is in the root directory, we will also want to compute the hash of the root directory which is the hash of the hashes of all the children. In this case we only have one child so the directory hash is simply the hash of the file hash.
hash(/) == hash(hash(file_contents(README)))With this, we have a very small Merkle Tree as a starting point. The root directory has a hash which represents all the files contained, and the README file has a hash which represents the file contents.
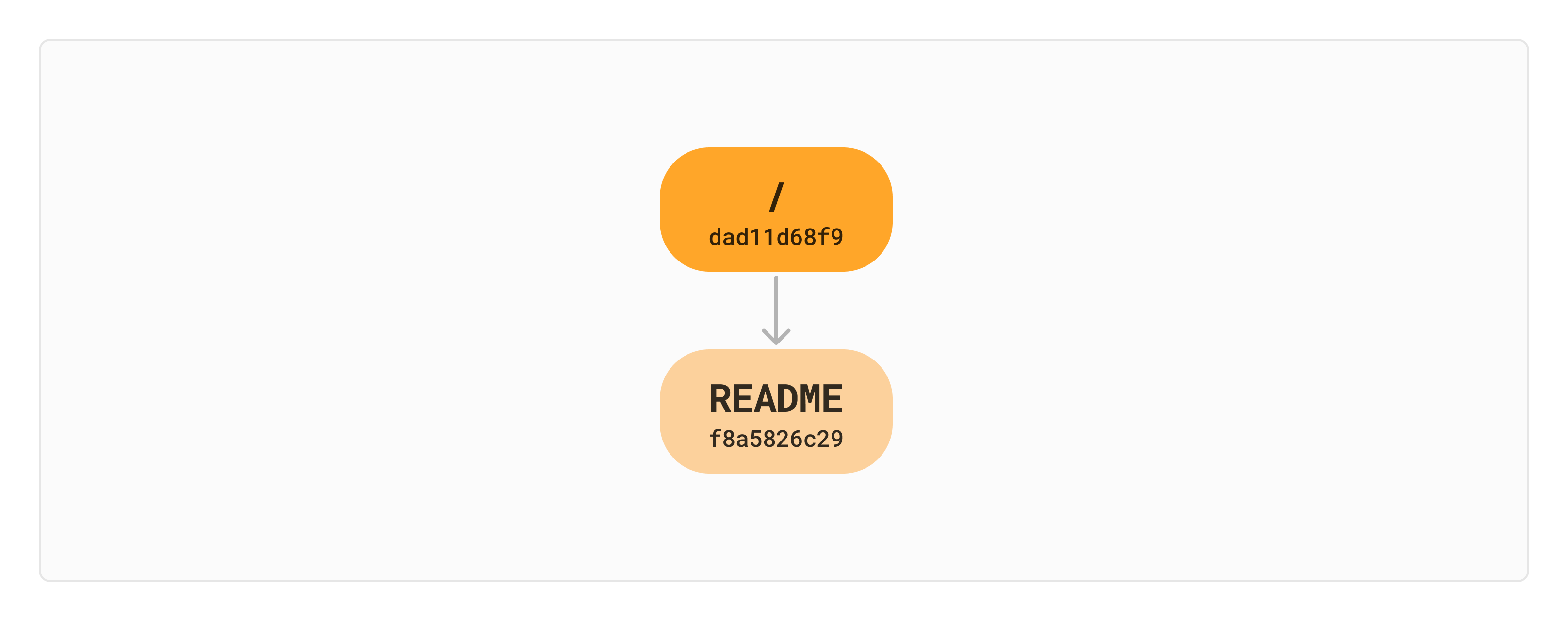
Now let’s say we want to change the content of README to "# Merkle Tree". We would re-hash the file contents and then compute a new hash for the directory. This results in a total 4 nodes and 4 different hashes.
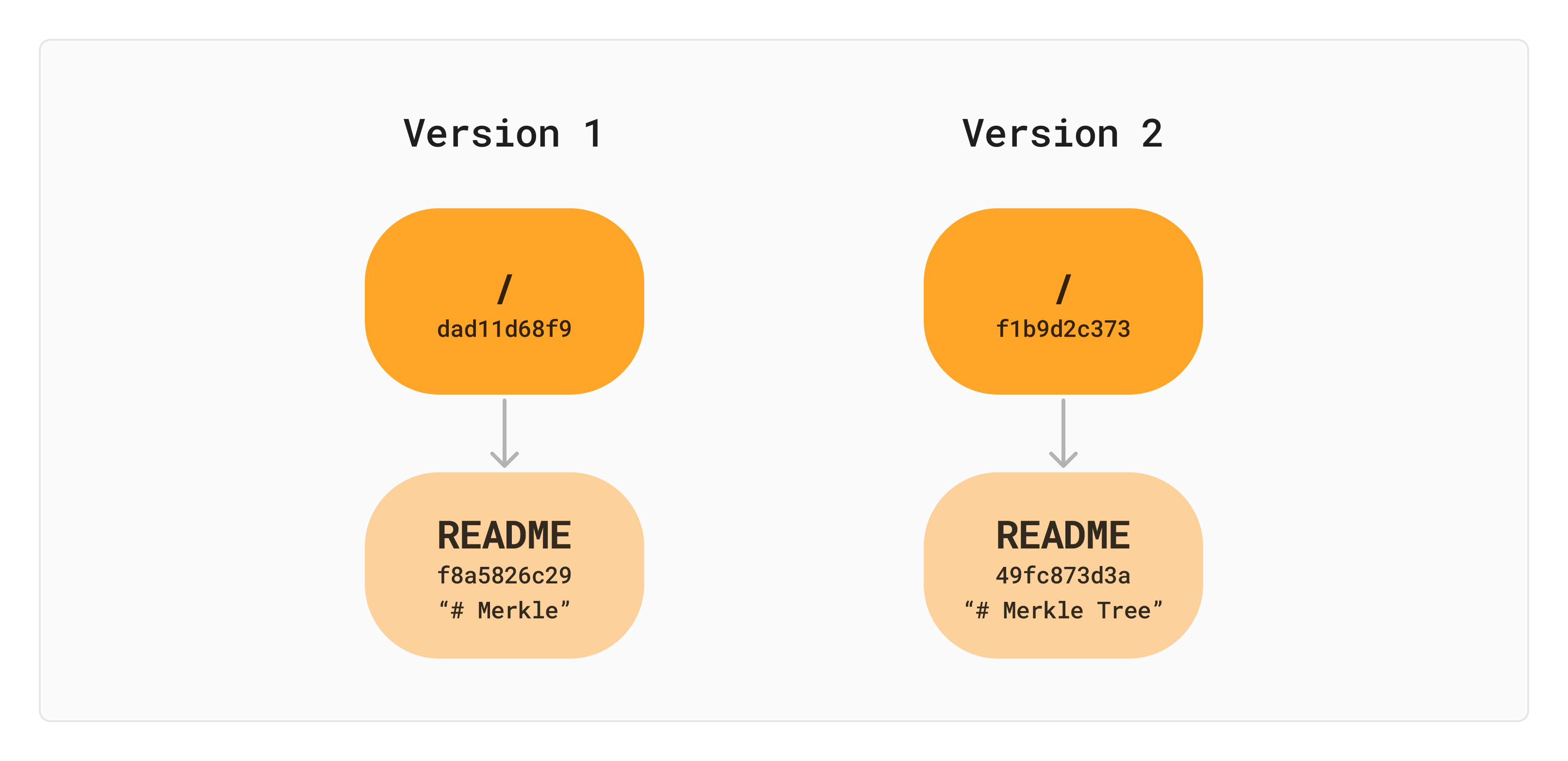
At this point, we have two separate “trees” (or maybe more like saplings) but they are kind of just floating in space. How can we identify which version is which and know when they were added?
Commit Nodes
We have been working with two types of nodes above: File and Directory. File nodes represent our raw file data and Directory nodes contain children which can either be a File or Directory. In order to return to specific revisions we will want to add a third node type of a Commit.
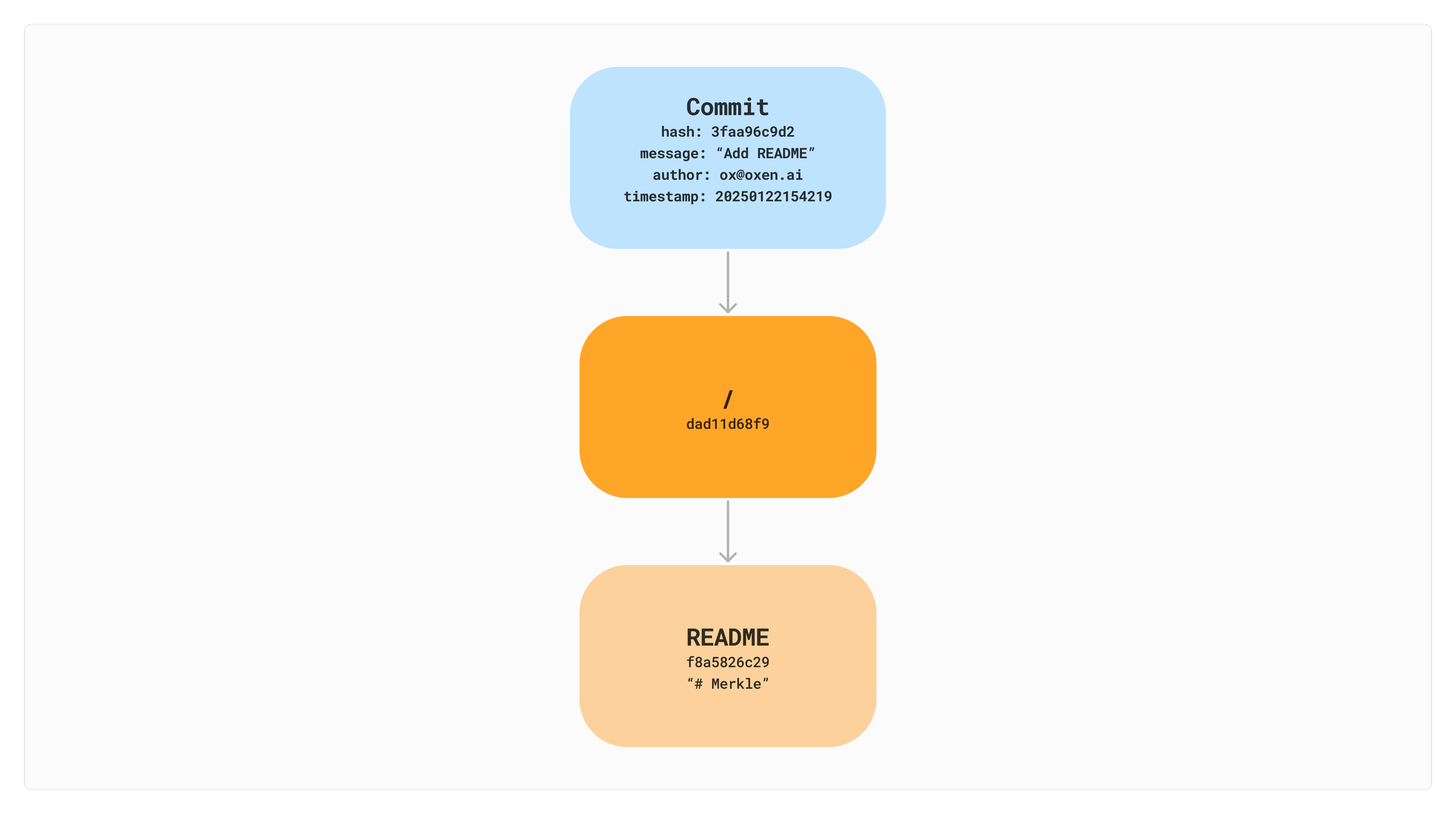
The Commit node will have a message, timestamp, authors, and a pointer to the root directory. Commit nodes will also have an optional parent that can point to previous commits. We can then hash all these attributes to create a unique identifier for the commit.
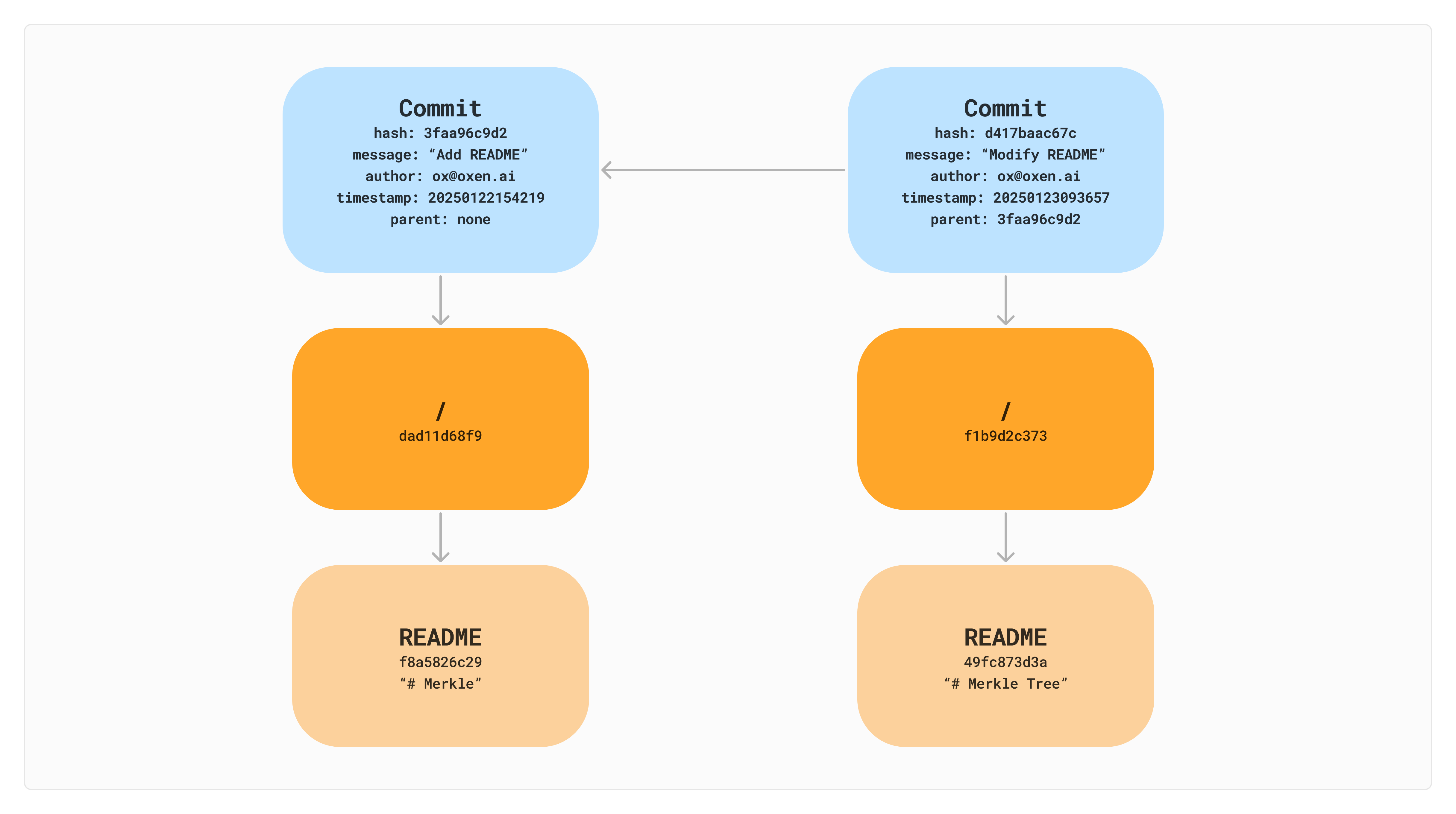
This structure now gives us a unique identifier (a commit hash) that we can use refer to back to different states of the file system. Using the commit hash (d417baac67c) we can get back a pointer to the root of the file system at that point in time. The link between commits to their parents also gives us lineage of changes.
To add another file, we will compute the new file’s hash, and then recompute the parent hash while leaving the other nodes (README) the same.
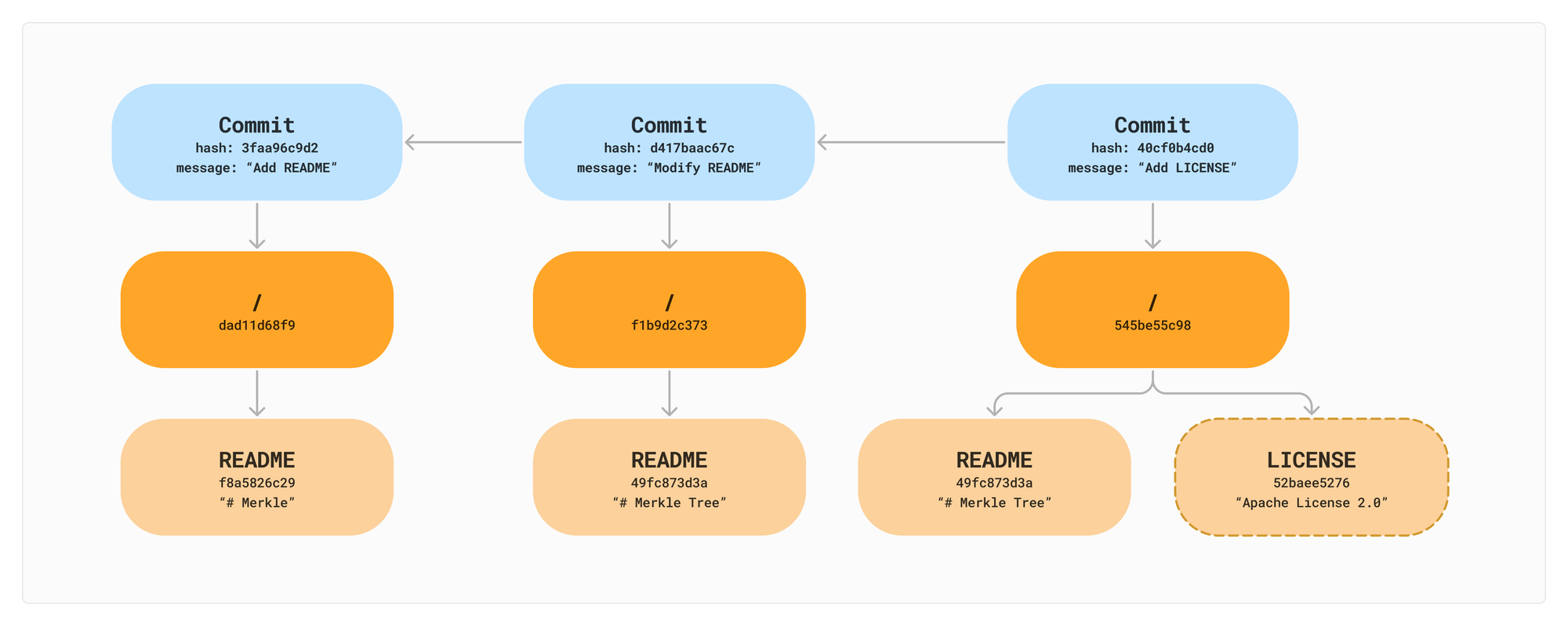
It’s not a far stretch to add branches from here. Branches are simply named references to a commit id. It is a very lightweight operation to create a branch because you do not need to copy any data, just create a new pointer to a specific commit id. You can have multiple branches point to the same commit. They are just different names for the same point in time.
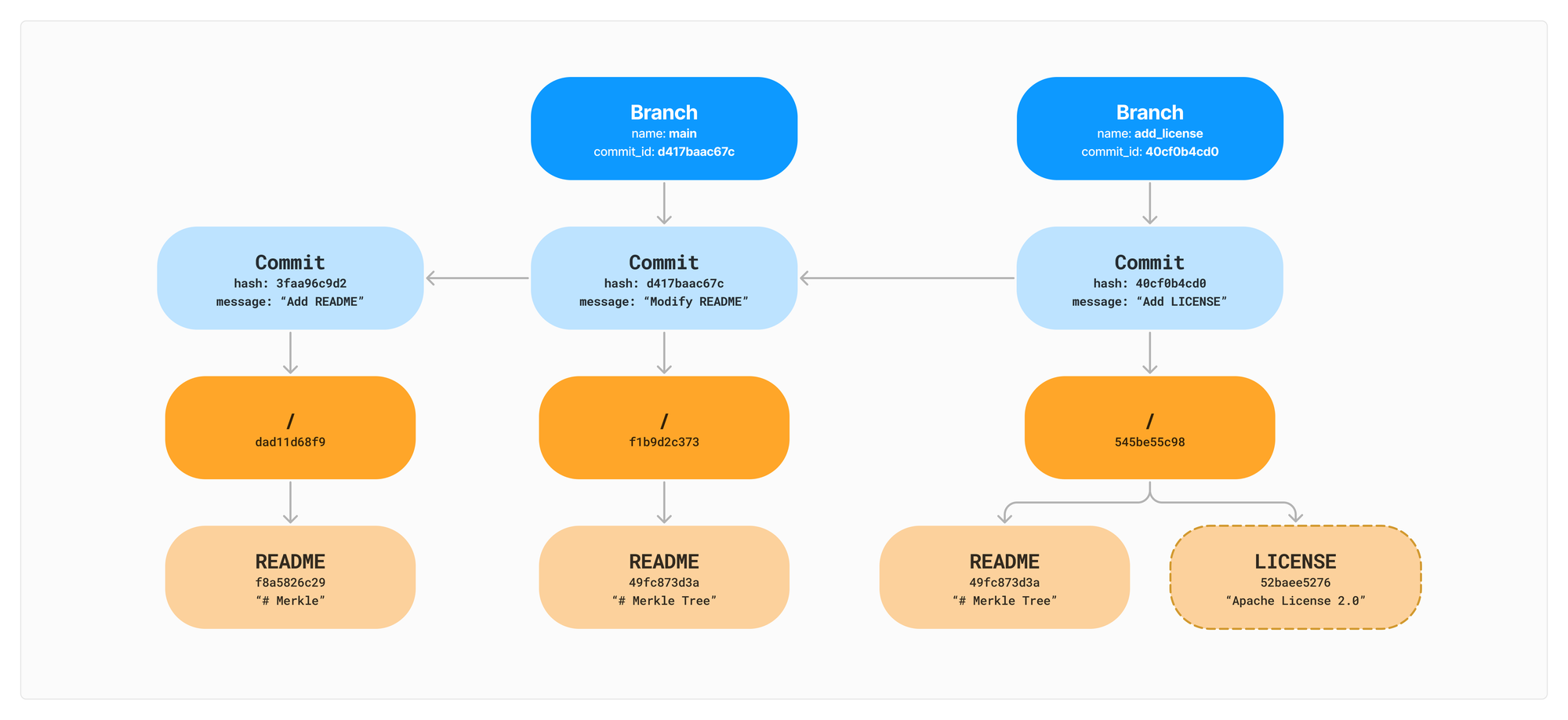
If you look closely at the README between the final two commits you will see that the node contents are identical. This leads us into the next benefit of a Merkle Tree: deduplicating content.
Deduplicating Content
The most naive way to version a file system would be to simply duplicate the whole thing and back it up to a new folder. That’s kind of what it looks like we are doing in the image above. In reality though, the content of README has not changed, so we do not need to make a copy.
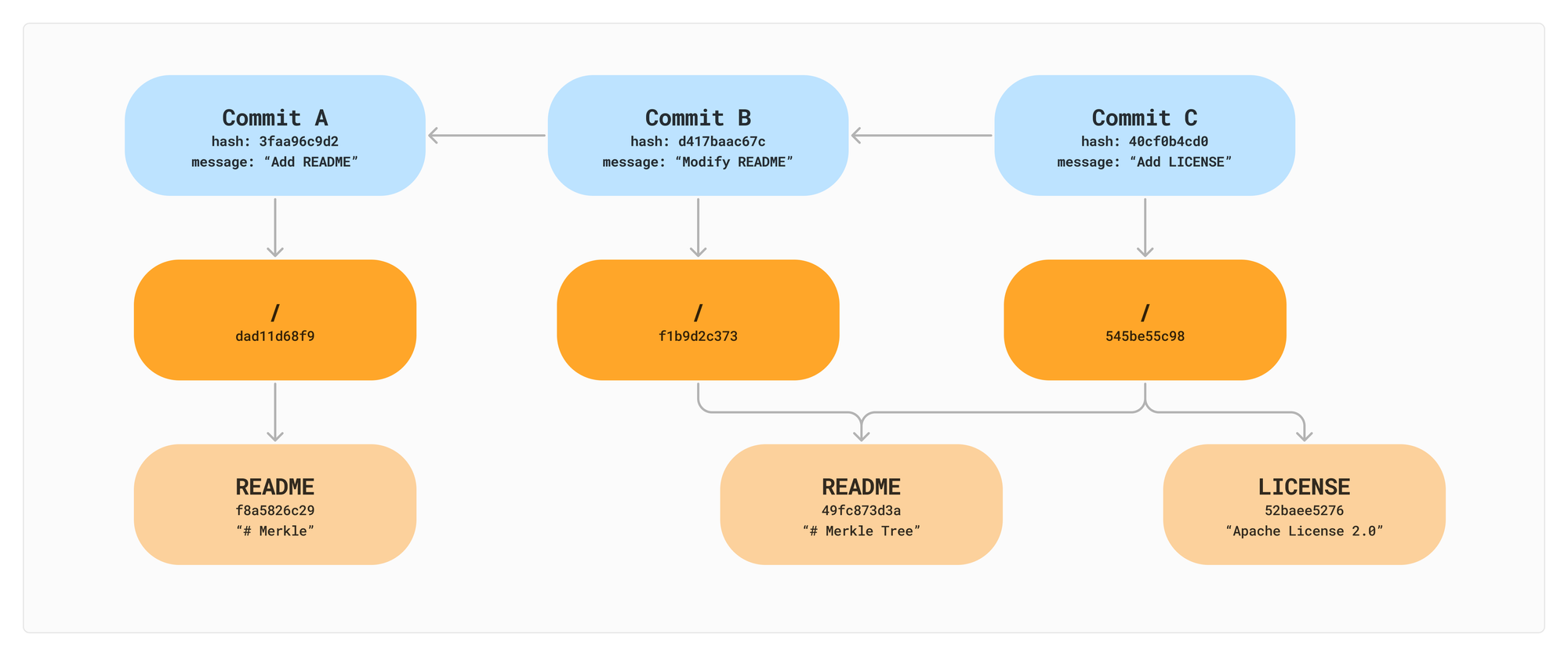
A clever trick to reduce this duplication under the hood is called a “Content Addressable File System”.

Since each file has an associated hash, we can use a hash map to quickly go from the hash of a file to the contents. The contents now only need to be stored once even though it’s referenced across two commits. Some version control systems implement this as a hidden directory on disk in which you can refer to each file and it’s metadata by it’s content hash.
.oxen/
versions/
f8a5826c29 -> {name: README, contents: "# Merkle"}
49fc873d3a -> {name: README, contents: "# Merkle Tree"}
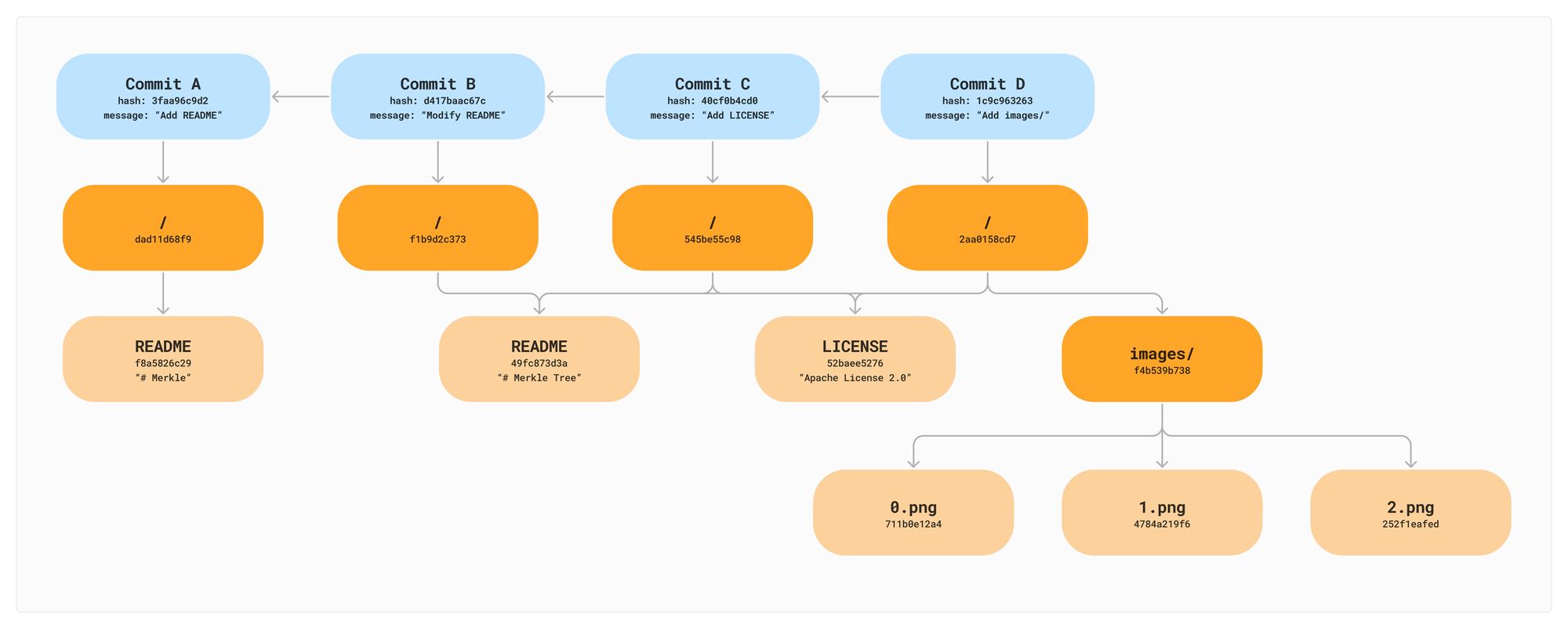
52baee5276 -> {name: LICENSE, contents: "Apache License 2.0"}To complete our Merkle Tree from the initial example, let's add our three images in a final Commit D. We share nodes between Commits B, C, and D because the README and LICENSE haven't changed.
Detecting Changes
Now that we have the basics down, let’s see how we can detect changes between different versions.
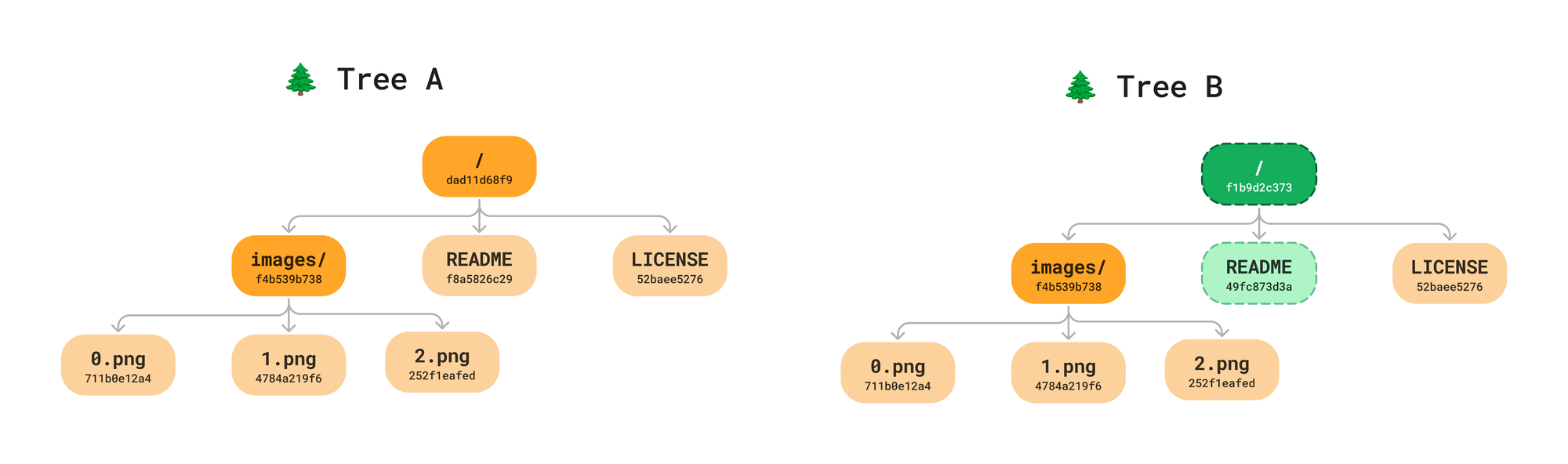
To detect changes in our tree we always start at the root, comparing the root hash. If the root hash has not changed, we do not need to go any further. The beauty of the recursive nature of the hash values is that it helps us know if a subtree has not changed. Remember, the hash of a directory is the recursive hash of all it’s children. If the hash of a directory high in the tree is the same across commits, we know we do not have to search any further for changes.
If the root hash has changed, we traverse down to the next level and compare each of the hashes. If a a File node hash has changed, we mark it as modified. Directories with the same hash do not need to be traverse further.
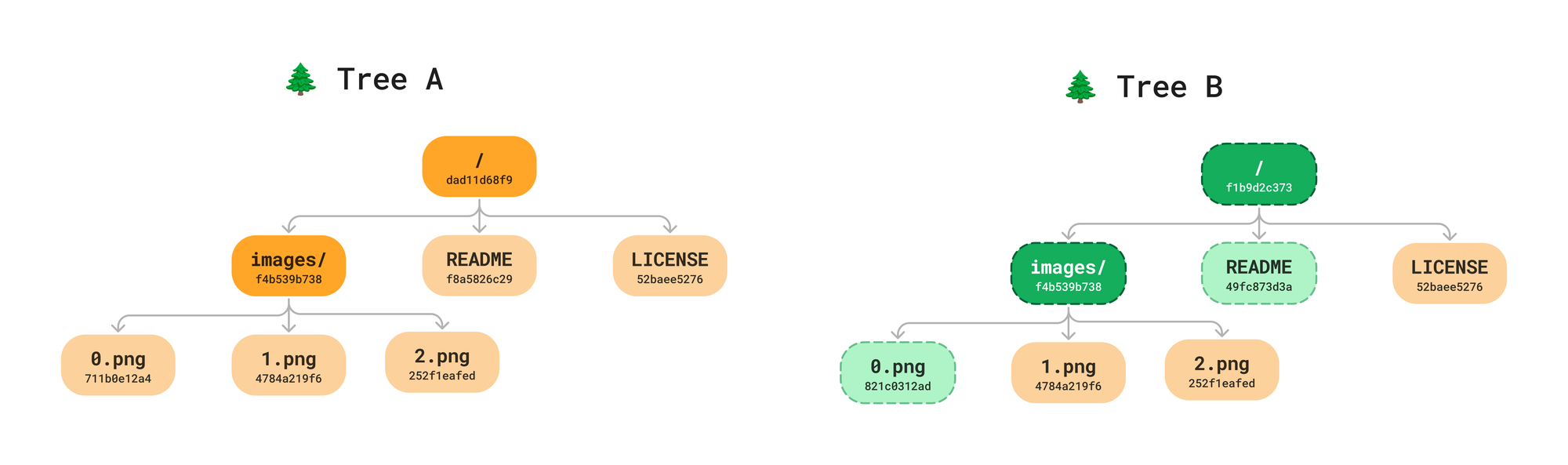
This can be an expensive operation if there is a single change deep in the tree. The next post in this series will introduce a concept called a “VNode” which speeds up these comparisons in Oxen.
Syncing Data
Everything we have talked about so far is a benefit of using a local Merkle Tree to backup your data. This is a great start, but typically you will want to sync your data via some sort of remote server. What’s great is we can share the same file structure on the server and the client.
It is a very lightweight check to send the hash of the root node to a server to see if we need to send any changes. Once we have established that there are changes that need to be synced to the server, we do the same recursive traversal between trees to understand the minimum data that needs to be sent. No need to check or send children from nodes with matching hashes.
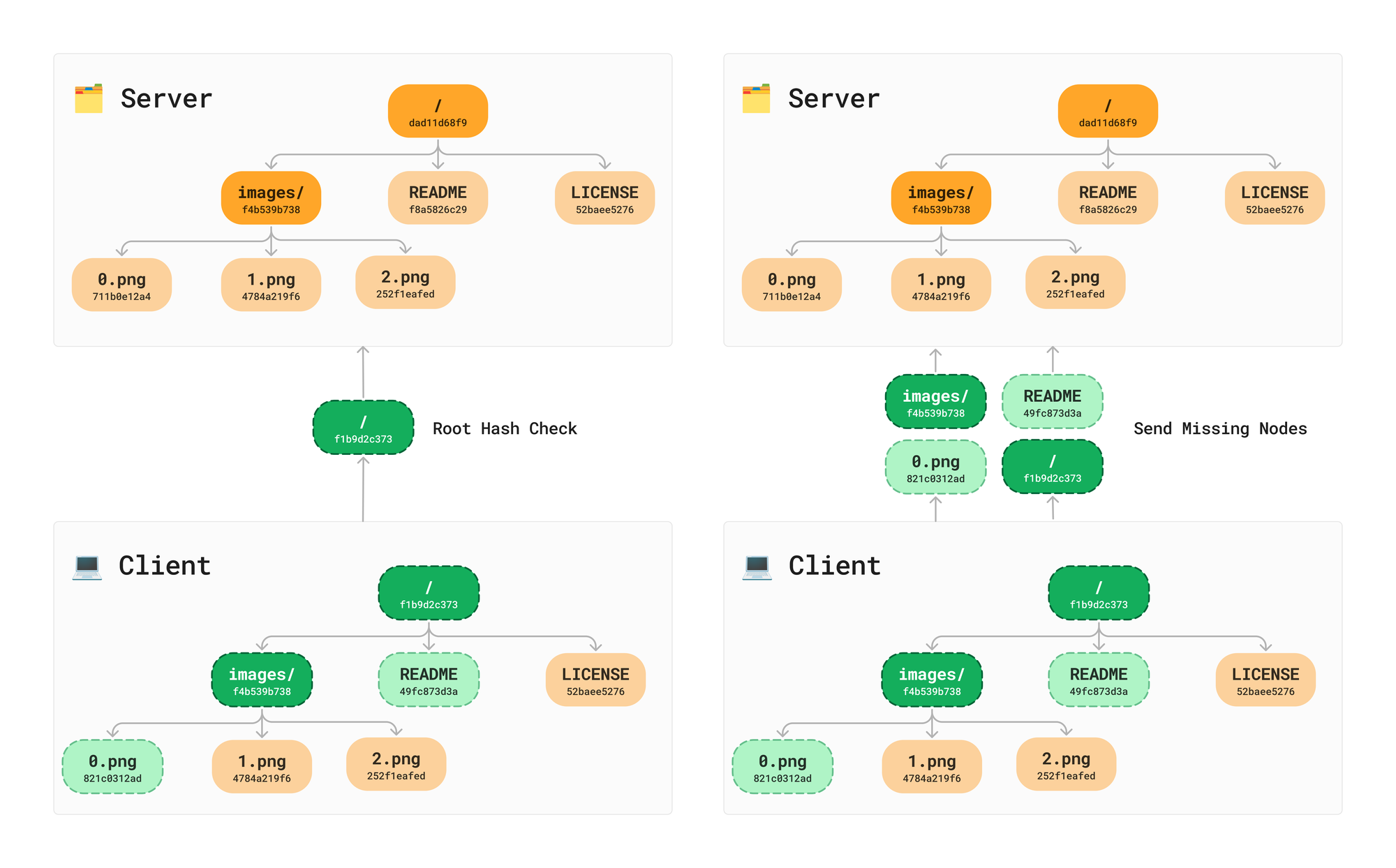
Ensuring Data Integrity
Once the all data arrives on the server, we can then recursively hash the received data up the the root making sure we didn’t drop or receive any corrupted data along the way. This makes distributed file systems more reliable and easy to verify. If the data was tampered with at any point in the chain, it’s the server’s responsibility to hash and verify it has every node and that the data is valid.
Next Up: Making It Fast
Hopefully this post has given you a sense of the beauty, power and simplicity of a Merkle tree data structure. At Oxen.ai we use Merkle Trees under the hood of our “blazing fast version control” tools. Want to dive in deeper? Along the way we have encountered some tips and tricks to speed them up for our particular use case. The next section will get more into the specifics and answer common questions like “but what makes Oxen so fast?”. Read more here:

If you love the nitty gritty low level details of data structures and file systems, feel free to checkout the open source project. Or even better… We are hiring! At Oxen.ai we believe that the more people that contribute to the data that powers AI, the more aligned it will be with us. We want to enable buttery smooth, easy to use, and fast workflows to help anyone contribute to large datasets and improve AI.
If this sounds like you, come apply to join the Oxen.ai Herd 🐂