How DeepSeek R1, GRPO, and Previous DeepSeek Models Work
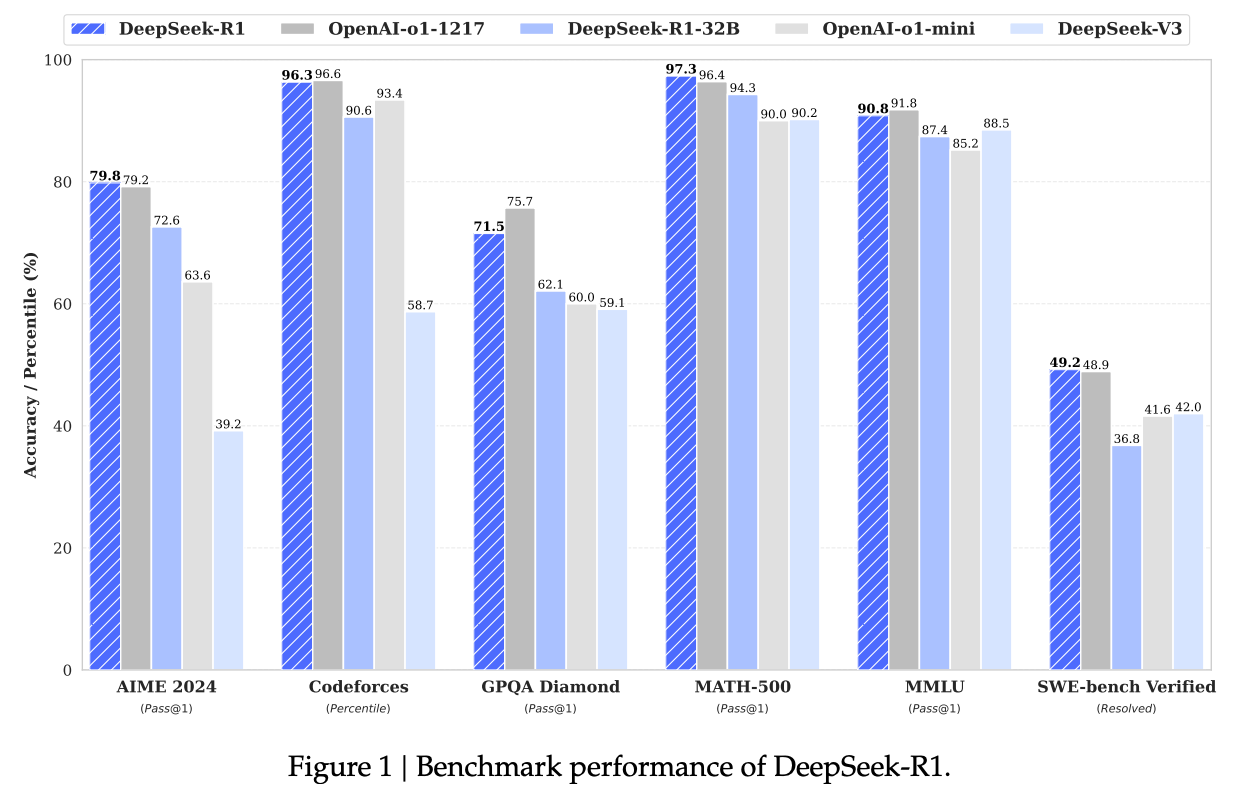

In January 2025, DeepSeek took a shot directly at OpenAI by releasing a suite of models that “Rival OpenAI’s o1.”
From their website:

In the spirit of Arxiv Dives we are going to dive into not only DeepSeek R1, but give you all the nitty gritty details of how they made the preceding models and how you can apply it to your own work.
DeepSeek-R1 Reading List
While doing research for this dive, I put together a reading list of the dives we have gone into in the past and papers I think are relevant to this work.

Greg spends full workdays diving into research papers and writing the Arxiv Dives. He does this to empower engineers to hack on their own AI and use Oxen.ai to set up their data. If you like this blog, try Oxen.ai today, and get $10 free compute!
Why are people so excited?
The top reasons DeepSeek R1 is disrupting the AI world:
- Less compute ($5 million for base model)
- Flattening the Closed AI monopolies
- R1 at home (running models locally)
- Full access to reasoning traces
- Model distillation enables smol models
The most immediate value of R1 in my point of view is generating synthetic data for the next generation of models.
Gwern agrees

For the rest of us, who don’t have access to the amount of compute needed to train a foundation model, R1 looks like it will be amazing for distilling small models for your specific use cases. The end of the paper has some concrete numbers and takeaways here.
An interesting analogy is thinking back to the era of personal computing. It feels like OpenAI, Google, Anthropic, etc are like big mainframes we have to pay for shared access to, and you can do little to customize them. DeepSeek, Meta and other open models are like the home brew computer club where we can download them customize them, run them locally, and really tinker with them to solve personal problems.
Favorite quote from a consultant I chatted with yesterday:
"Do you hear that? That's the sound of everyone clamoring to fine-tune R1, but realizing they don't have the right data."
If you’re curious how you can use R1 to generate synthetic data and customize your own models, Oxen.ai has some great tooling for this. We’re also working with some compute providers to make it cheap and easy as possible. If you want to be a design partner to test out the pipelines and get some cheap distillation data, let me know.
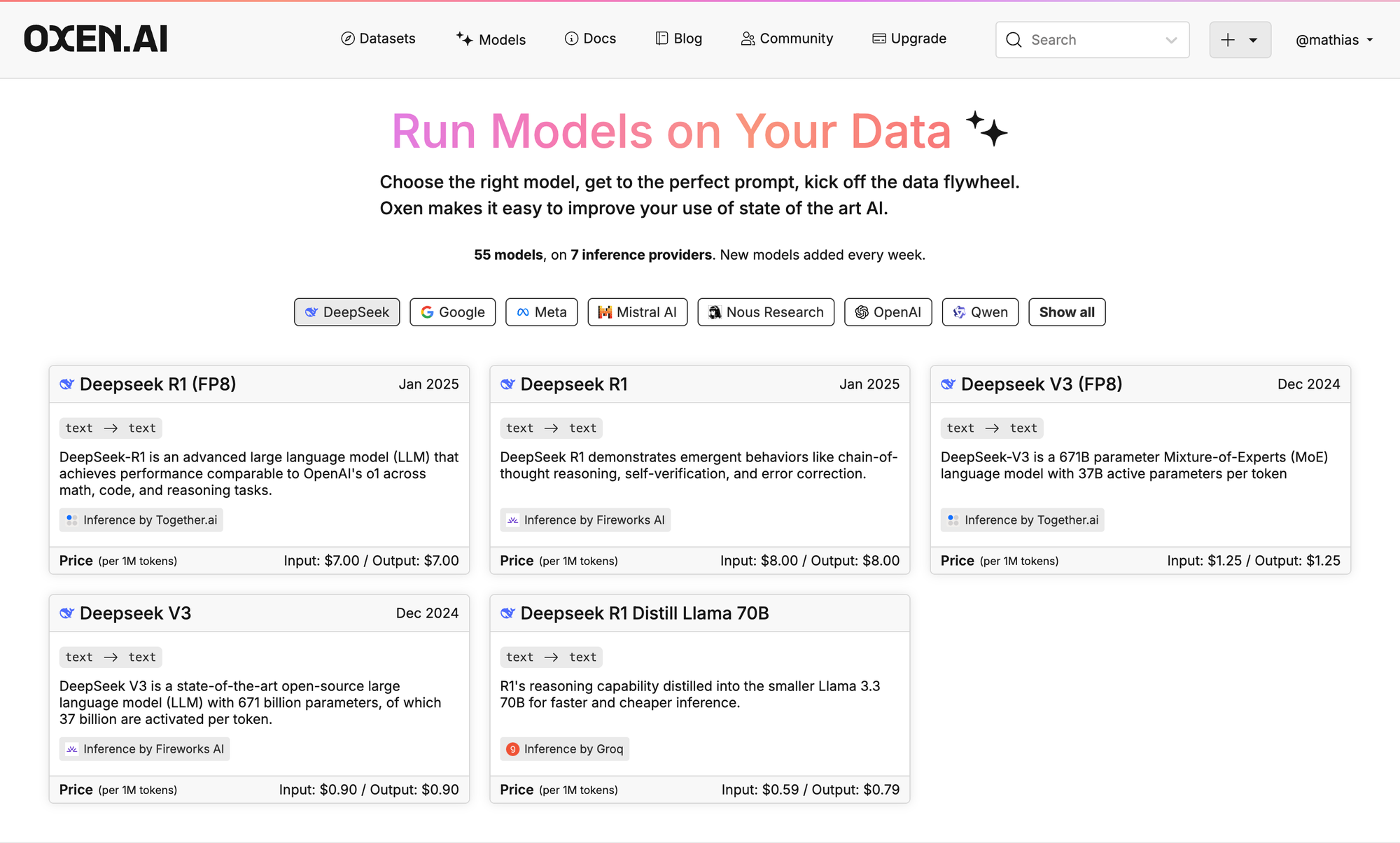
For now, checkout our available models on Oxen.ai

Okay, on to the paper.
What is a “Reasoning” Model?
It’s pretty simple: think before you speak.
Here’s me asking deepseek-r1:14b what it thinks.
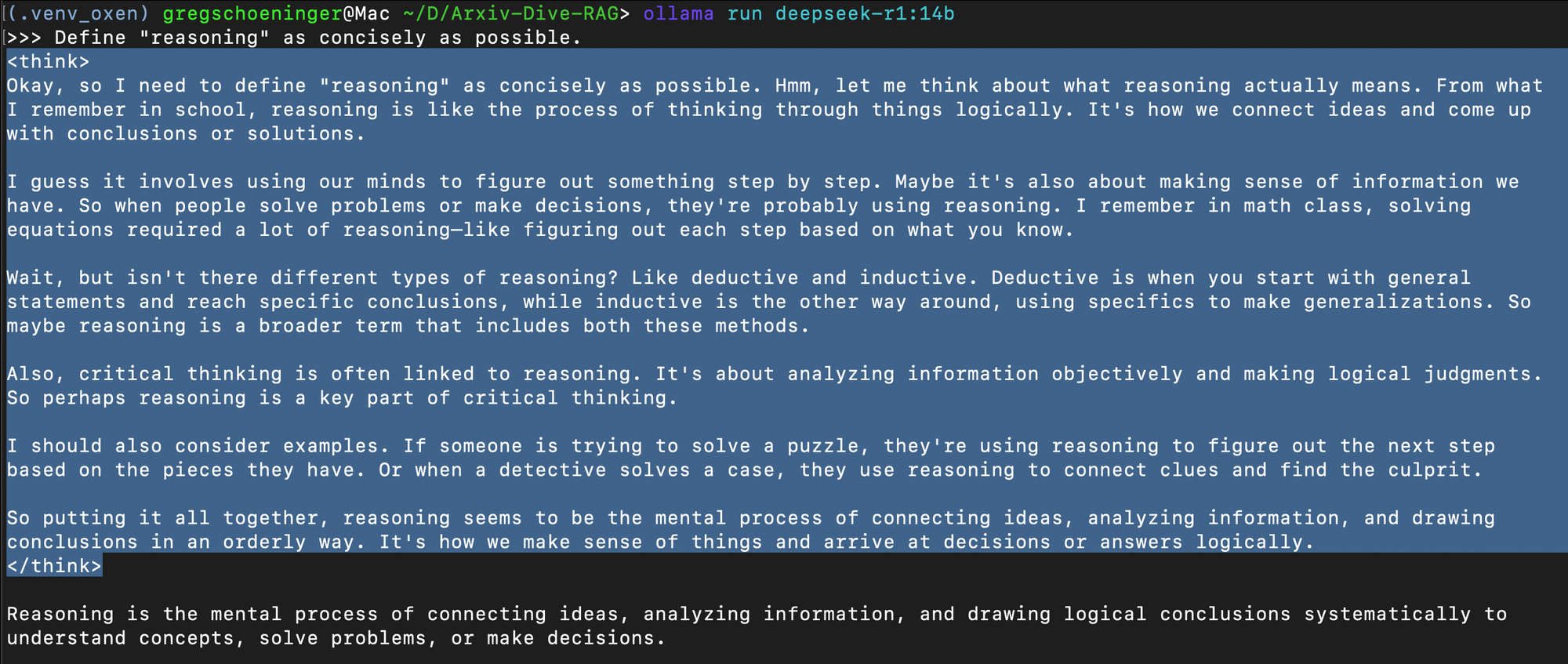
You’ll notice these special <think></think> tokens. These help the model work through problems with multiple steps before responding. OpenAI o1 hides these thinking steps, but with R1 we have full access.
What are DeepSeek-R1’s Contributions?
- Post-Training: Large Scale RL + Base Models
- Distillation: Smol Models the rest of us!
The stated goal of the paper is to extend models reasoning capabilities without any supervised data.

Yann was really onto something with his cake analogy in 2016:
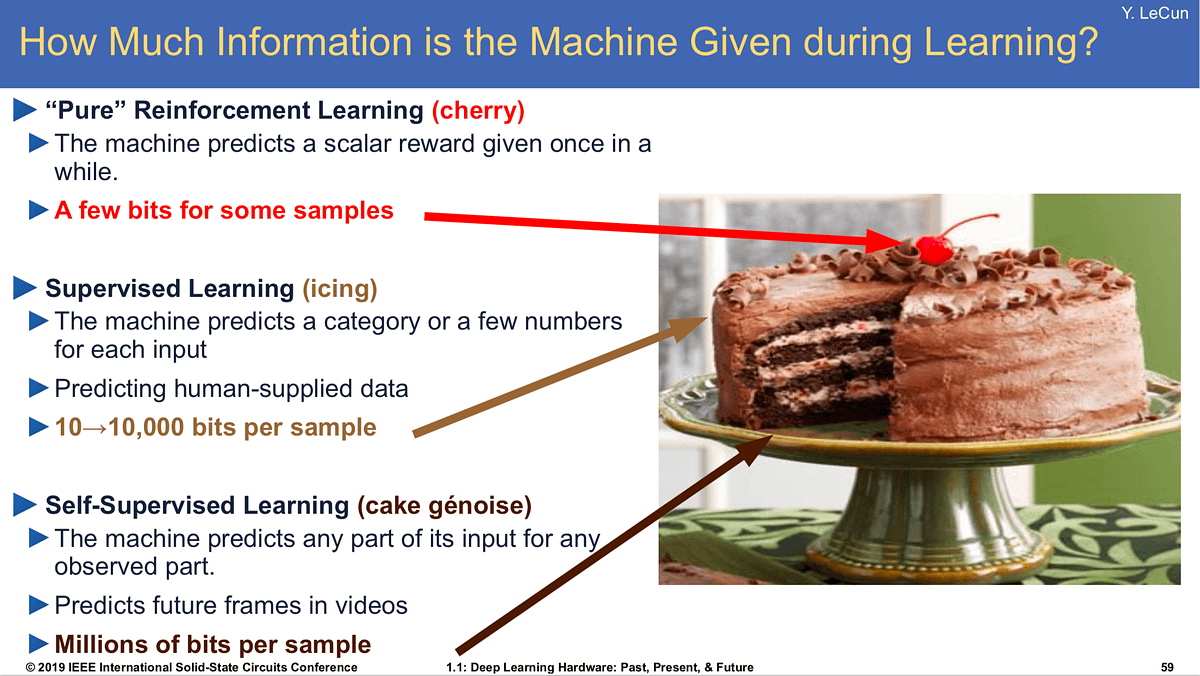
When you look at this cake, it is important to understand how many “examples” the cherry takes to learn in an RL setting.
The most surprising part of DeepSeek-R1 is that it only takes ~800k samples of 'good' RL reasoning to convert other models into RL-reasoners. Now that DeepSeek-R1 is available people will be able to refine samples out of it to convert any other model into an RL reasoner. pic.twitter.com/iFwIMxiVy9
— Jack Clark (@jackclarkSF) January 27, 2025
When thinking about children learning in the real world reinforcement learning feels like it should only take a couple examples per concept. I show you an apple from one angle, do you need to see all variations of all apples to understand the next green apple you see is in the same category as the yellow and red apple? No. My question is: How many “samples” are we actually getting throughout our lifetime through our pupils and other senses? Feels more than 800k across all concepts… (not every example is about an apple).
Quick Guide To The DeepSeek Models
To help you navigate the open source weights that you can download and “run at home”, there are the set of frontier models which are all 671 Billion Parameter MoEs, with 37B active parameters per token. They have a context length of 128k.
- DeepSeek-V3-Base = Pre-training
- DeepSeek-V3 = Supervised Fine Tune
- DeepSeek-R1-Zero = RL Model
- DeepSeek-R1 = Improved RL Model
Note: These take up 670+GB of disk space when downloaded, and a cluster of GPUs to run.
Then there are the distilled smaller models that you can run locally:
- DeepSeek-R1-Distill-Qwen-1.5B (smallest)
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
DeepSeek-v3
Before we get into R1, it’s good to set the stage with V3. This is the base pre-trained model that simply is trained to predict the next word.
If a standard transformer looks like this:
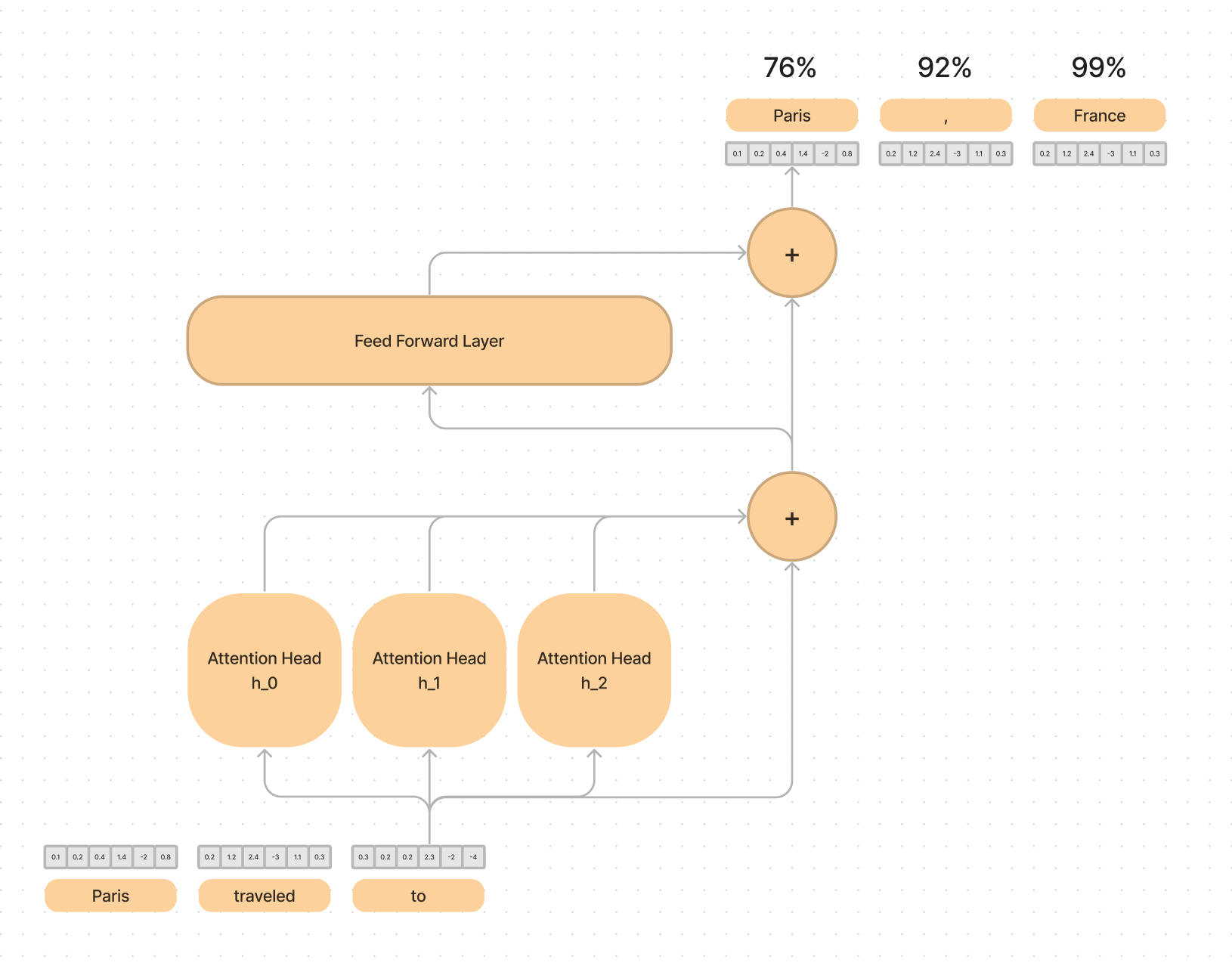
A MoE looks like this:
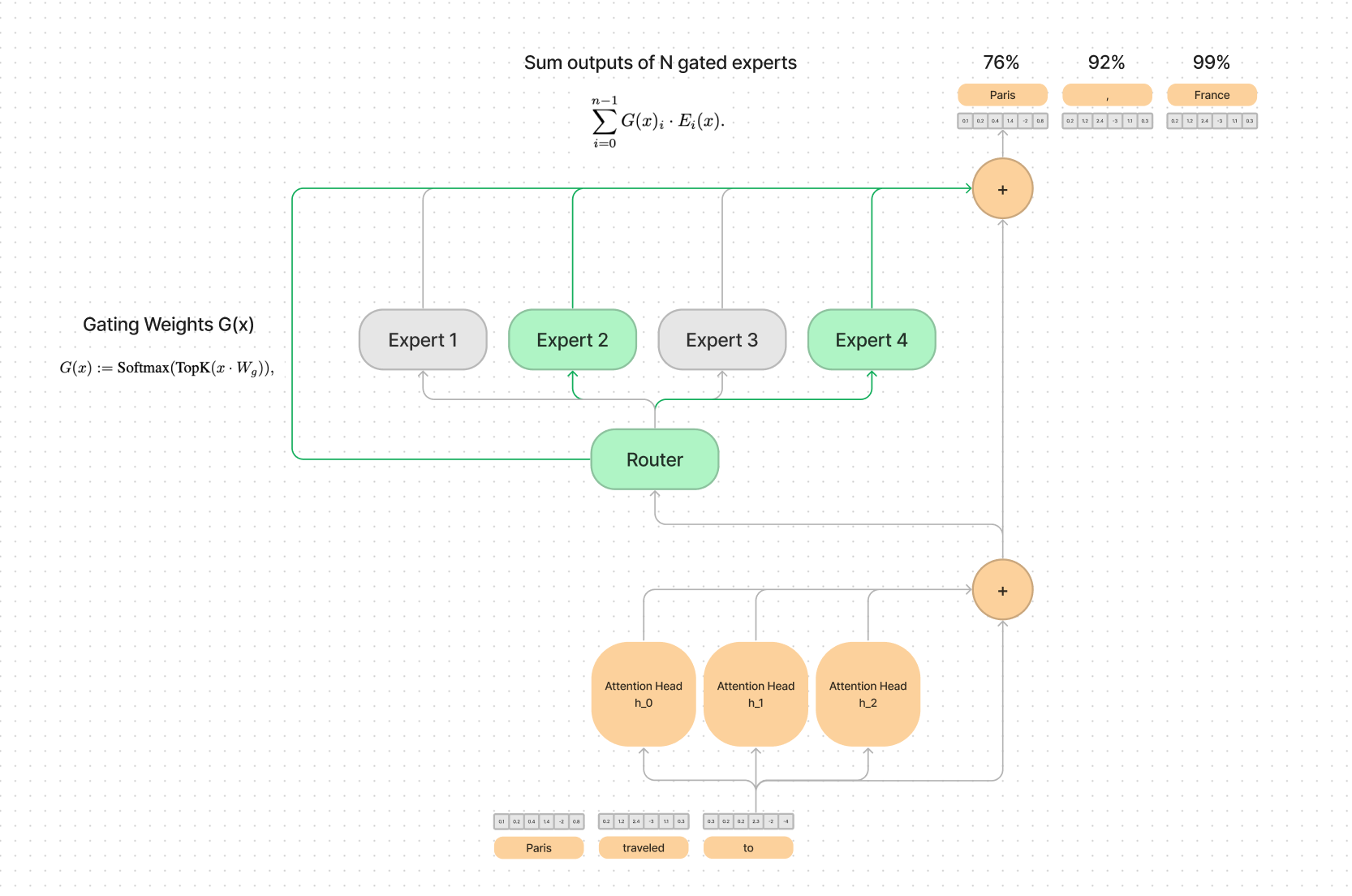
Where you replace the single dense feed forward layer (where a lot of the compute is done) with a sparse mixture of smaller feed forward layers. The intuition is that based on the context, the router module has learned which smaller expert would be best suited to handle the next token.
One expert might know more about geography and Paris, France and one expert might know more about pop culture and Paris Hilton.
A few of the benefits of MoE’s are stability during training as well as the number of “active parameters”. They can be more efficient at training and inference time because there are less matrix multiplications done per token.
The one caveat I would add here is that you still have 671 total GB of weights that have to be shipped in and out of GPU memory.
From their GitHub:
Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
They made a few important optimizations in this paper to improve pre-training efficiency
- FP8 mixed precision training framework
- Low level optimization of the communication bottleneck in cross node MoE training.
What Hardware Do I Need To Run It?
On the lowest end you could get away with loading the 37B active parameters in and out of memory every token and have a really slow, but functioning local model.
More realistically, you would want a cluster of GPUs that can hold the entire set of model weights in memory. You need a cluster because no single consumer GPU has >670GB of memory. An H100 has 80GB of VRAM so with 8xH100 you could almost run the full precision model, but you’d actually want even a little more space for context. This runs ~$25/hr as of the start of 2025.
You could also network a bunch of smaller GPUs but ideally you don’t want to be splitting up the experts computation across a network. The final option is quantizing the model further, losing some of the precision or accuracy of the model which has unknown downstream affects on language modeling.
That being said, when people say “Run DeepSeek at home” they typically mean the smaller distilled models.
DeepSeek-R1-Zero
This name seems to pay homage to AlphaZero which required no bootstrapping and learned everything “on its own”. They show that reasoning capabilities can be achieved and improved without any supervised fine tuning or directly labeled data.
How does this work?
They start with DeepSeek-V3 Base and use a technique called Group Relative Policy Optimization (GRPO) which is a Reinforcement Learning Framework to help improve model reasoning.
This lead to DeepSeek-R1-Zero after thousands of RL steps. The paper that introduced GRPO was focused on Math, but can be applied to any RL setting.
If you remember from DPO or PPO or other RL algorithms, the idea is always: Given a user query, generate multiple parallel responses, and decide which one is better (or in RL terms, “which action to take, given your current state”). PPO is what InstructGPT which turned into ChatGPT originally used. DPO is a simplified version that is commonly used in Open Source, and is the easiest to understand.
This is the equation for GRPO, which is long, but is not too bad once you know what each element means.

The pi’s are the language models, which are producing o’s give q’s (outputs given questions). The A’s are the “Advantages” or rewards per token (determined by the reward model). Then there are a could sums over the tokens and the number of groups we are outputting and a subtraction of KL divergence.
If that is all Greek to you, here is a nicer diagram.
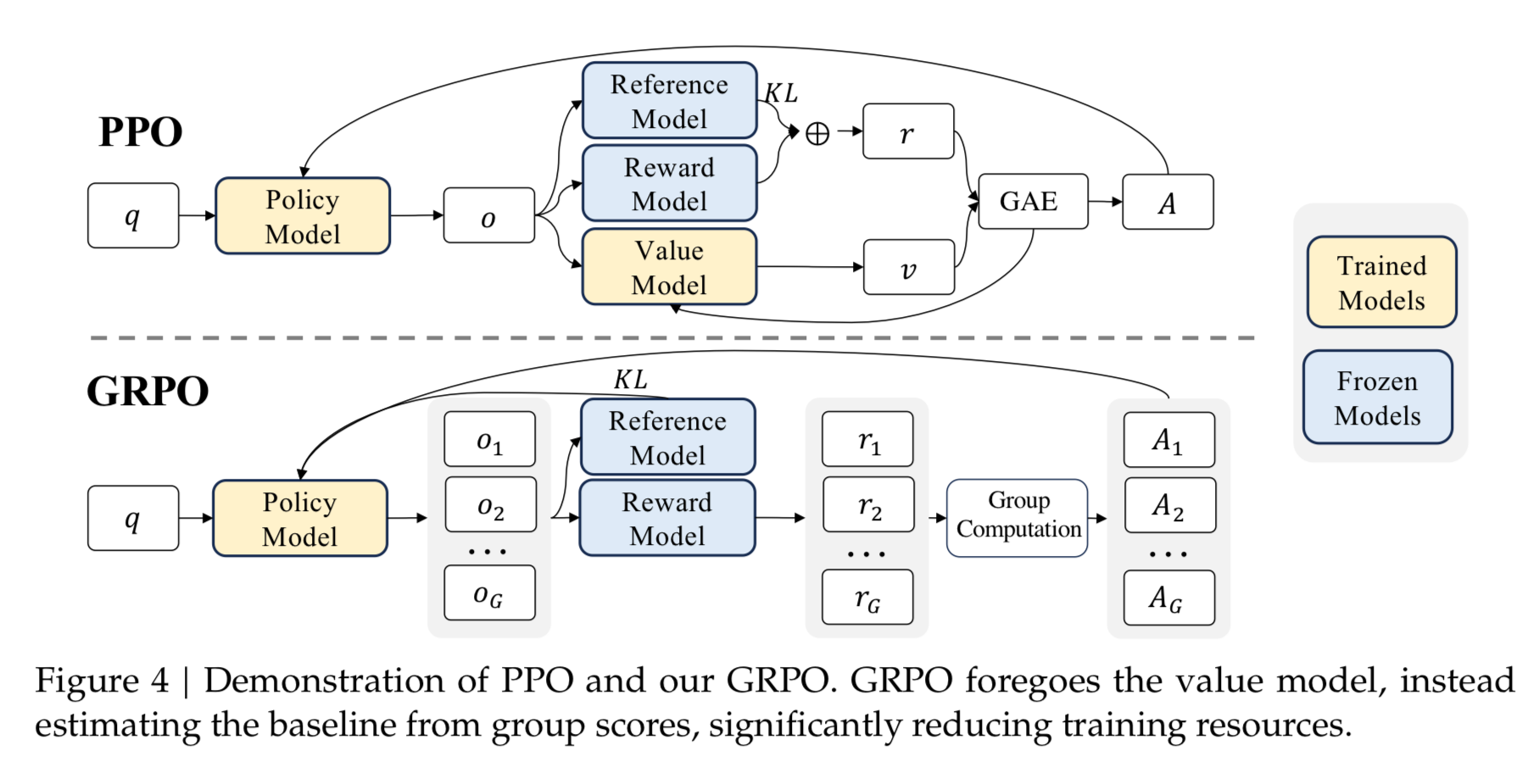
GRPO drops the need for the “value model” from PPO, which is typically another LLM of comparable size. This makes it significantly more memory and compute efficient to have 2 LLMs in the mix than 3 LLMs during this optimization.
Let’s walk through step by step.
In comes a user query, which you run through a “policy model”, which is just a fancy name for the LLM that we are currently training. This LLM produces N outputs per query. For each output you use a reward model (again, another LLM) that is ranking the outputs. These rankings are then averaged to give signal to the model of how well it is doing.
They constrain the policy model’s outputs to be close to the reward model’s outputs using a KL divergence constraint in their loss, so that the model doesn’t drift too much during the RL steps.

For any of this to work, you need a pretty good reward model as a starting point that gives you any sort of signal for how well you are doing. Reward models are typically trained with human labeled pairs of queries and outputs that have been ranked.
If you remember from the InstructGPT paper that is this middle step:
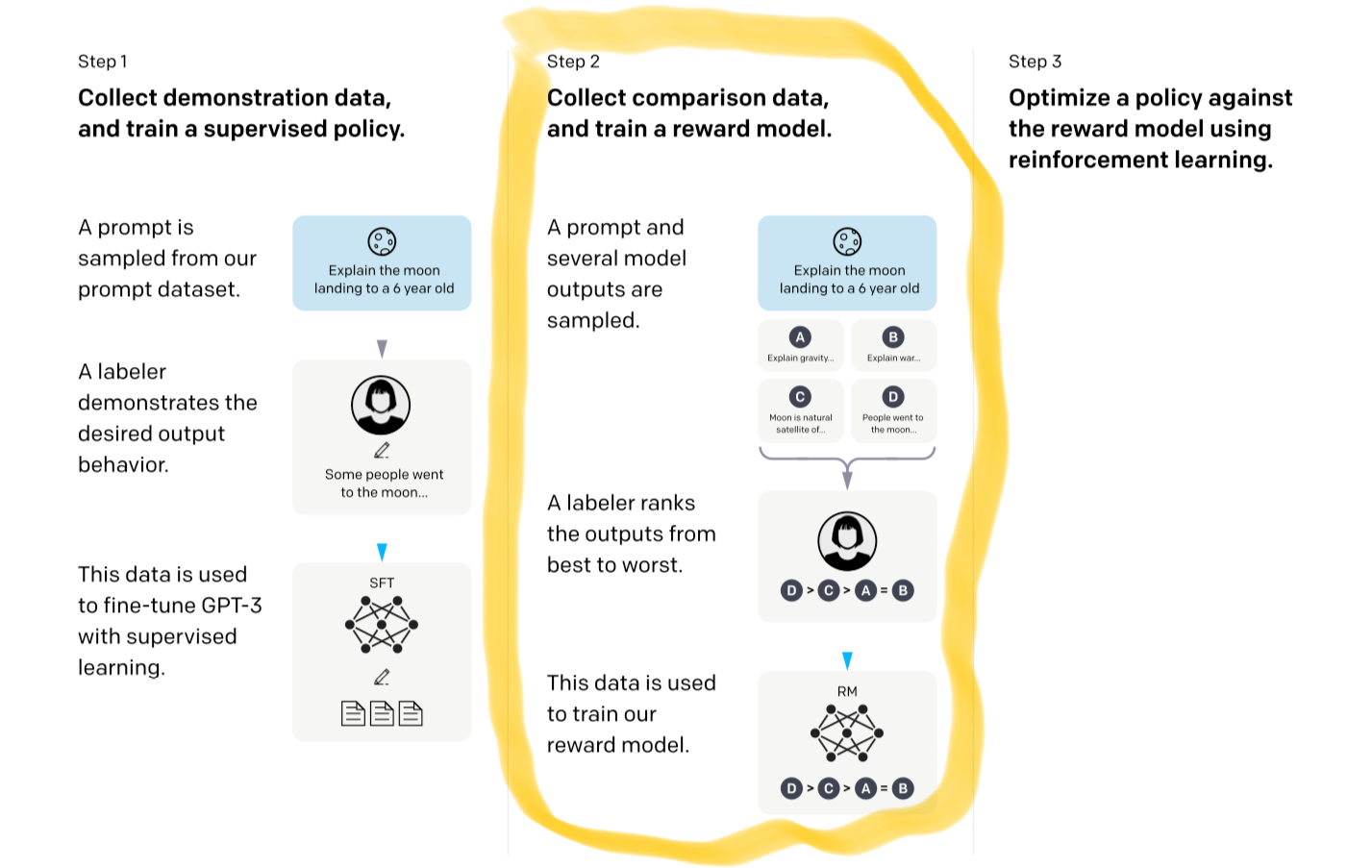
If you are curious how this compares to DPO we break DPO down here:

Whew, okay, now that we understand the basic RL algorithm, how was this used in DeepSeek-R1-Zero?
In DeepSeek-R1-Zero they have two types of deterministic rewards:
- Accuracy: is the response accurate? This could be deterministic for the cases of math and coding.
- Formatting: did we put some <think> and </think> tags and think before we spoke?
What is interesting is that there is no “neural reward model”. These are just deterministic rules that they use as signal.

When I read this, I thought this is kind of crazy…can they really just be using regexes as rewards? By looking up some sample GRPO code, the answer is yep.
DeepSeek-R1-Zero should have been named "Regexes as Rewards" pic.twitter.com/oUmETwer3O
— Greg Schoeninger (@gregschoeninger) January 30, 2025
Doesn’t this mean it only really gets better at reasoning about math and programming? Also, Yes.

Granted, there is also the prompt that you use to kick off an R1-Zero style model as well, that gives you a little more control and guidelines for the generations. But that’s it.

Aha Moment!
It wouldn’t be a reinforcement learning breakthrough if there wasn’t a “Move 37” like moment. This is when the algorithm discovers actions that are new and surprising even to humans. In AlphaGo, the system generated a move that had 1-10,000 odds to be played by a human, but in retrospect won the AI the game.
An intermediate version of DeepSeek-R1-Zero may not have had a “move 37” level of insight, but it did learn how to take steps that were not explicitly programmed in to solve math problems.
It took a second to pause, realize it was going down the wrong path, and correct itself saying “aha” along the way.

We saw this with our long division example above. This behavior is interesting because it learned to dynamically allocate more thinking time to a problem by re-evaluating it’s initial approach.
This is the beauty of reinforcement learning: rather than explicitly teaching the model how to solve a problem, give it the right incentives, and allow it to solve the problems on it’s own.
This is shown on some of the benchmarks where the longer it was trained in an RL setting, the better it became.
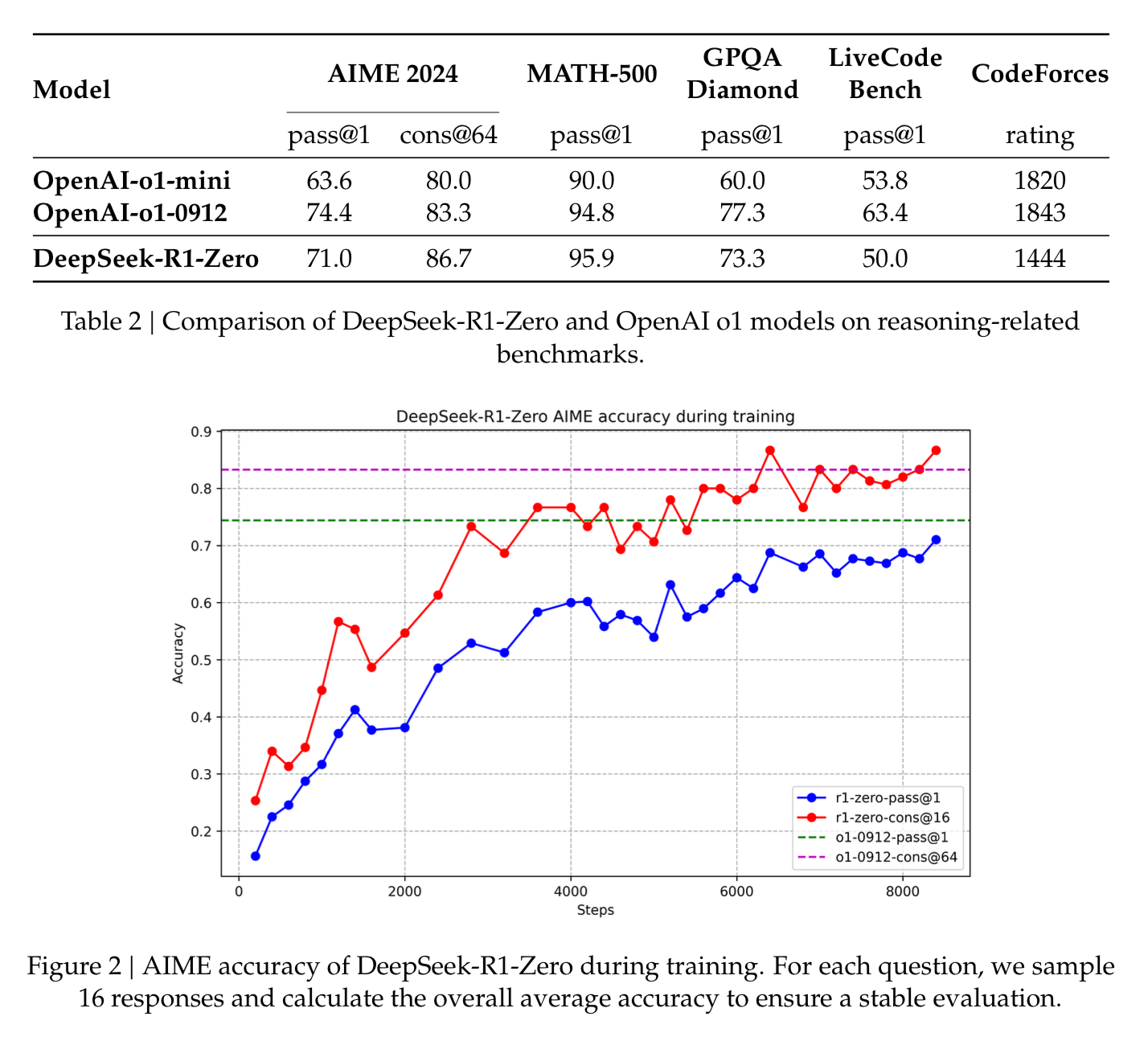
The AIME stands for “American Invitational Mathematics Examination” and the AIME_2024 dataset is actually only 30 examples, you can look at some of them here.

DeepSeek-R1
So turns out…Even though it was impressive that DeepSeek-R1-Zero worked at all, it was not great at writing coherent text and suffered from language mixing. To fix this they introduce DeepSeek-R1 which adds in some “cold-start” data and a multi-stage training pipeline.
After the cold start SFT, they alternate between RL and SFT by using rejection sampling to curate the data for each round.
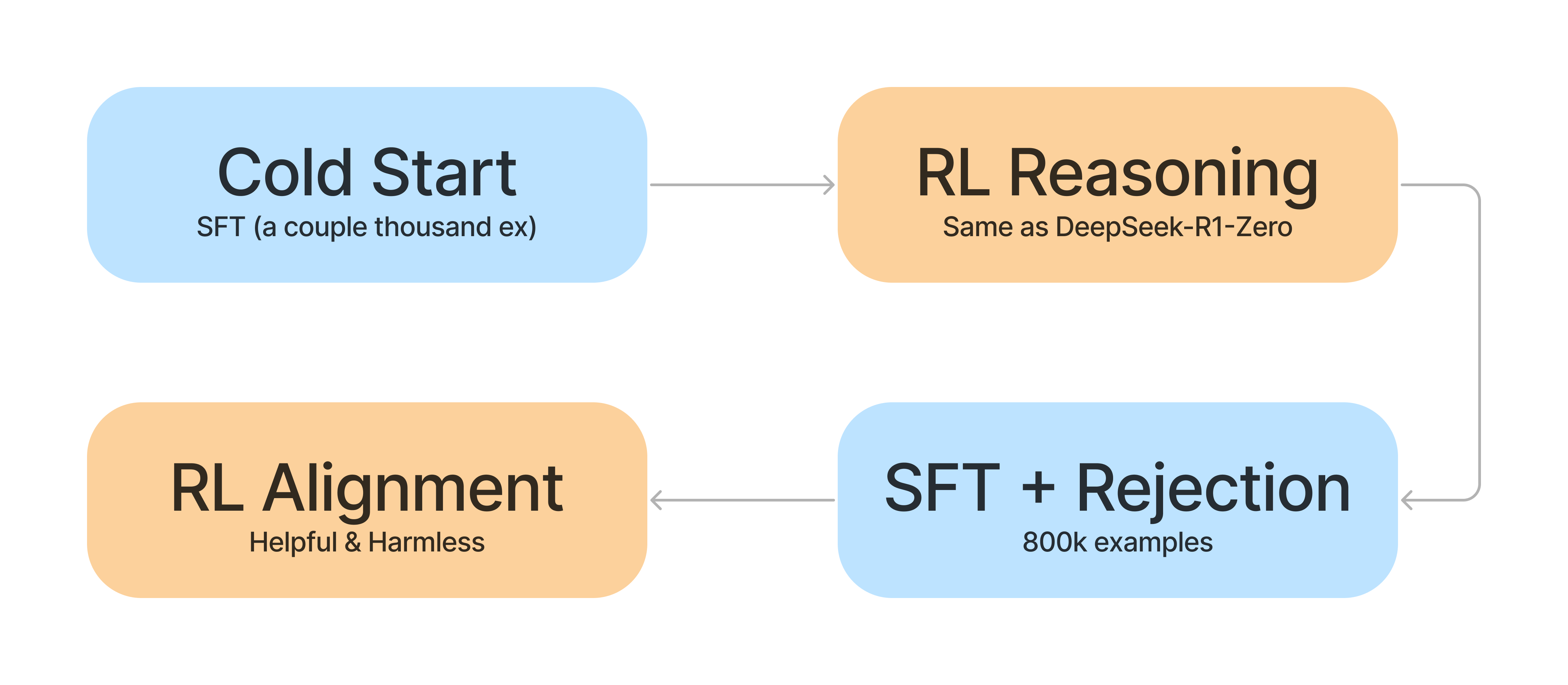
Cold Start Data
To collect the cold start data, they use a few approaches:
- Few-shot prompting with long CoT as examples
- Directly prompting models to generate detailed answers with reflection and verification
- Gathering DeepSeek-R1-Zero outputs and filtering by human annotators
They collect thousands of these examples to bootstrap and fine tune DeepSeek-V3-Base as the new starting point.
After bootstrapping with the cold start data, they apply the same large-scale RL training as they did in the DeepSeek-R1-Zero pipeline.
They add in a “language consistency” reward to keep the model more on track that is simply the proportion of target language words in the CoT. What’s funny is this actually degrades the model performance on some benchmarks, but is more readable by humans.
Rejection Sampling and SFT
Once the first round of RL finishes, they use the resulting model to collect SFT data for the next round. This is very similar to the Thinking LLMs or Self Rewarding LLMs papers.
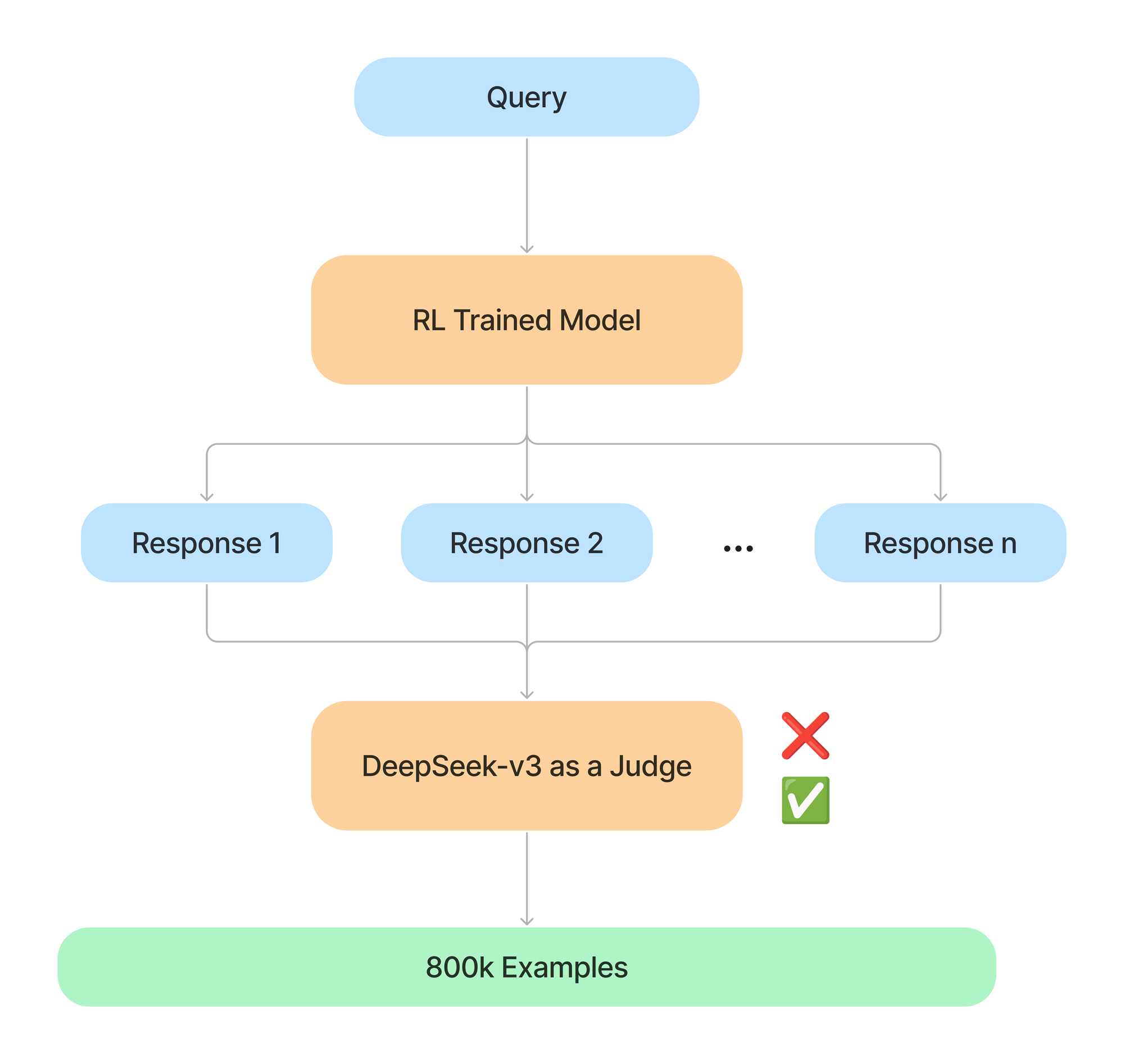
They generate two kinds of data: reasoning and non-reasoning. To generate the data they curate prompts and generate outputs with reasoning. Then they take DeepSeek-v3 as a judge to filter out incorrect responses. The reasoning data consists of 600k examples and the non-reasoning is another 200k.
For the non-reasoning data they use DeepSeek-V3 to generate more data like the SFT data that was used to fine tune DeepSeek-V3, but that are not related to reasoning like Factual QA or simple chat responses like “hello”, “hey”, “how are you?”.
Helpfulness and Harmlessness RL
The loop continues with other prompting and reward signals such as ensuring the model is helpful and harmless. Again, this is just a loop where they use DeepSeek-V3 to generate preference pairs that they can then train on.
This is where you have a lot of control on the style of the model. Give the rejection sampling some guidelines on what you want the model to do, and let it generate the data.
You could in theory continue this cycle of STF+RL and there are many people working on this “self improving” loop.
Distilling Smaller Models
For their suite of smaller models, they simply use DeepSeek-R1 to generate 800k examples to fine-tune other open source models with.
For example they took Llama 3.1-8B as a starting point, and do a full supervised fine tune on it given the synthetic data. No RL was done here.
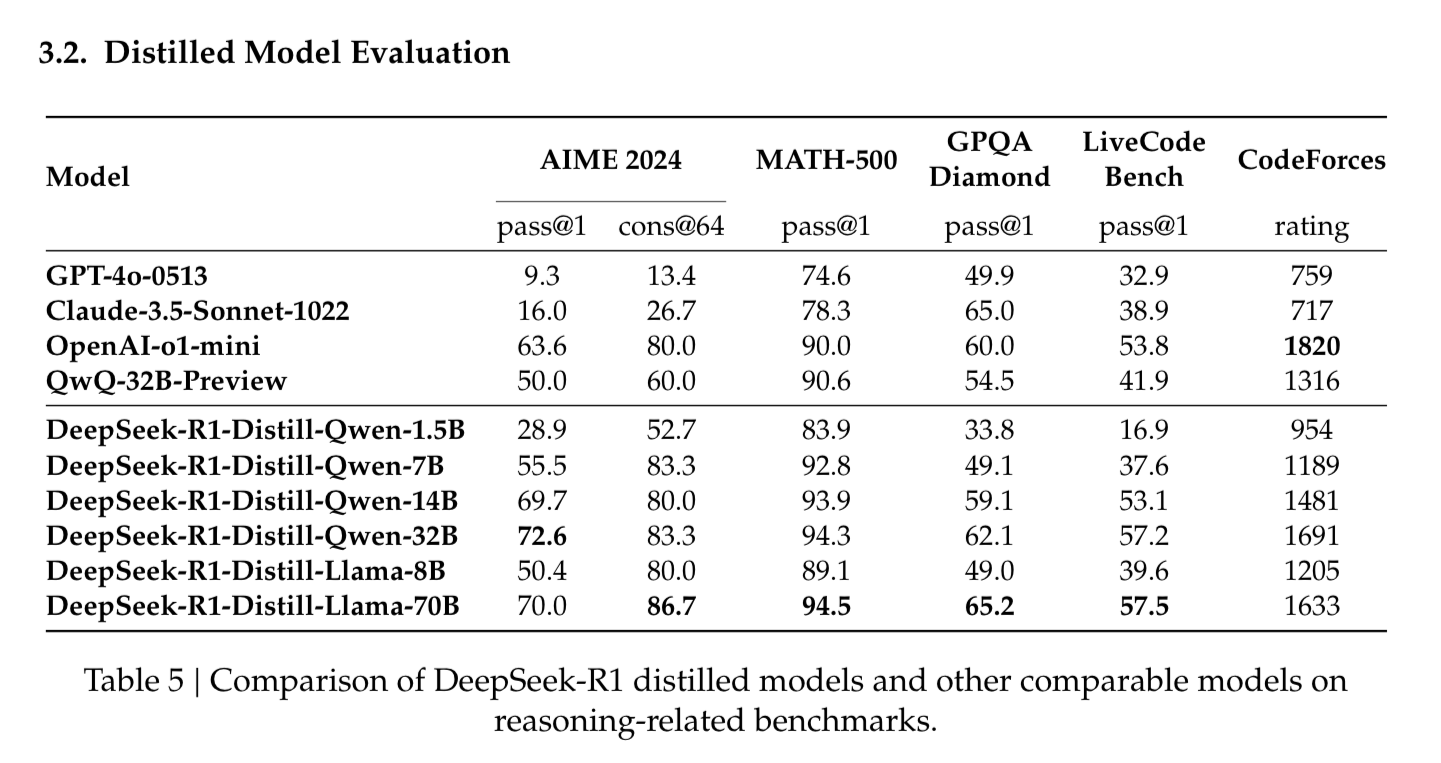
The distillation from R1’s outputs enables even 7B parameter models to outperform GPT4o and Claude-3.5-Sonnet on some benchmarks.
This is why I saw R1 is about generating synthetic data and distilling models.
Distillation vs RL
The results with distillation beg the question: can a model achieve comparable performance through large-scale RL without distillation?
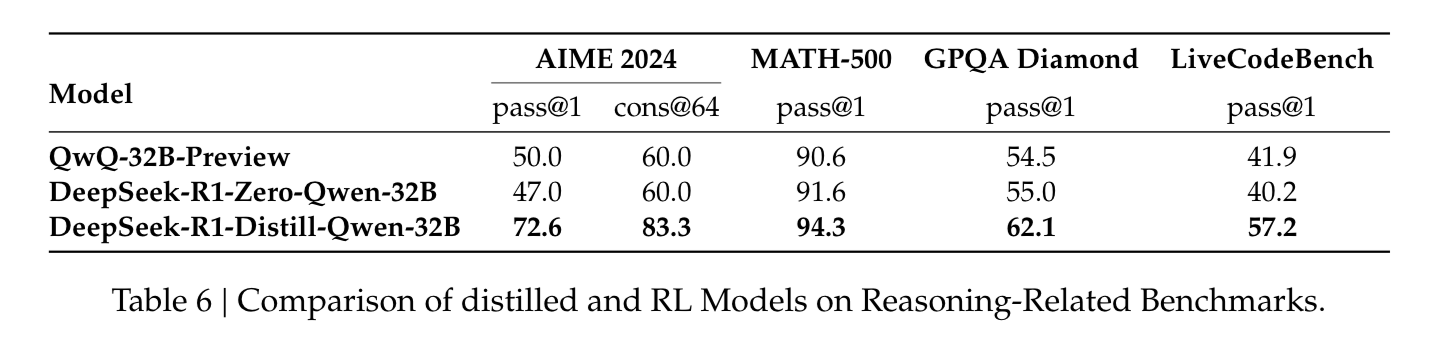
They did at least one experiment with the 32B parameter Qwen-32B-Base model and distilling from the larger model gave the bigger bang for the buck than purely R1-Zero style RL.
At the end of the day, my takeaway is that if you have a large model to have coherent chain of thought and reasoning, you can use that model to generate data in a variety of domains and improve smaller, faster models.
The other takeaway is that large scale RL really only seems to work with larger models. So let’s leave large scale RL to the big labs, and start distilling our own smol models.
Conclusion
We covered a lot today from the high level to the depths of RL. Hopefully this is demystified DeepSeek-R1 and given you a good picture of how you can actually use it “at home”.
Like I said, this is a big shift in the paradigm of who has access to the most powerful models. It’s an exciting time to be tinkering and hacking and see how these reasoning models can really solve real world problems and the smaller models are essentially free to run.
We are working on creating some example tutorials of generating synthetic data to distill models with R1. If you want to be the first to read/watch them, make sure to subscribe here!
Running R1 to generate synthetic data can be extremely slow and expensive by hitting APIs, so we are working with some compute providers to make it cheaper and more efficient. If that interests you and you want to be a design partner, let us know. Happy to get you some free synthetic data to help test out our pipelines. Feel free to just email us at hello@oxen.ai.