arXiv Dive: RAGAS - Retrieval Augmented Generation Assessment


RAGAS is an evaluation framework for Retrieval Augmented Generation (RAG). A paper released by Exploding Gradients, AMPLYFI, and CardiffNLP. RAGAS gives us a suite of metrics that can be optimized as we are tweaking knobs in our pipeline. There are many knobs to turn in a RAG pipeline. Knowing which ones to turn is one of the most important skills you can have as an AI Engineer. RAGAS gives us a north star that we can navigate our ships towards in the high seas of building a RAG application.
Here is the recording of the Arxiv Dive if you want to follow along:
Let’s Build
In the spirit of arXiv dives, we not only like to read the paper, but we like to get our hands a little dirty as well. I put together a little demo app that we can play with a RAGAS framework on. This will help us concretely see how each step works.

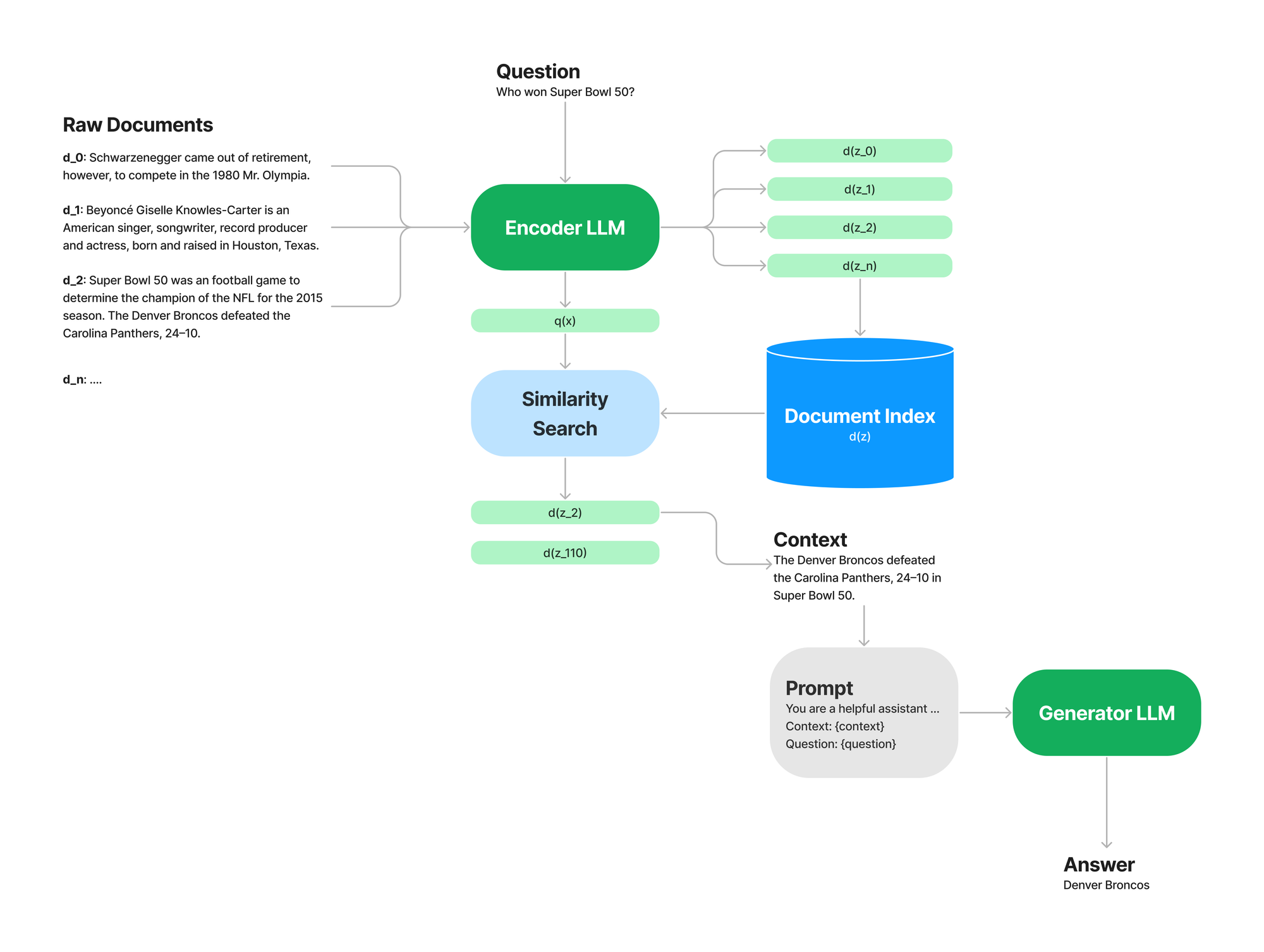
Let’s start by giving a 10,000 ft view of RAG to refresh your memory. If you are not sure what RAG is - we have a dive on it from about a year ago, and there are tons of tutorials online.
RAG 101
We perform RAG because some questions cannot be answered accurately without context. Either because there was no information in the training data, or it depends on the domain you are asking for. An example of not in the training data: A research paper that just came out yesterday.
The basic steps of RAG are:
- Embed your documents with an Encoder LLM
- Embed you question with an Encoder LLM
- Retrieve some context given the question & documents
- Construct a prompt with the context included
- Generate an answer with an LLM given the prompt
Check out this link for a more in-depth explanation.
🤿 🤖 ArXiv Dive Bot
To bring this to life I took all the papers that we have done an arxiv dive on, chunked them, computed embeddings, and built a smol little rag app on top of them.
Let’s drive home why RAG is important with this example. We will be grounding this paper in real data from this small app that I’ve put together to see how well the technique works in practice.
My goal is to have a pipeline where I can input a new paper and it will…
- Generate interesting questions about that paper
- Quiz me on the answers
- Act as a search index of everything we’ve learned so far 🧠
👨💻 Quick Demo App
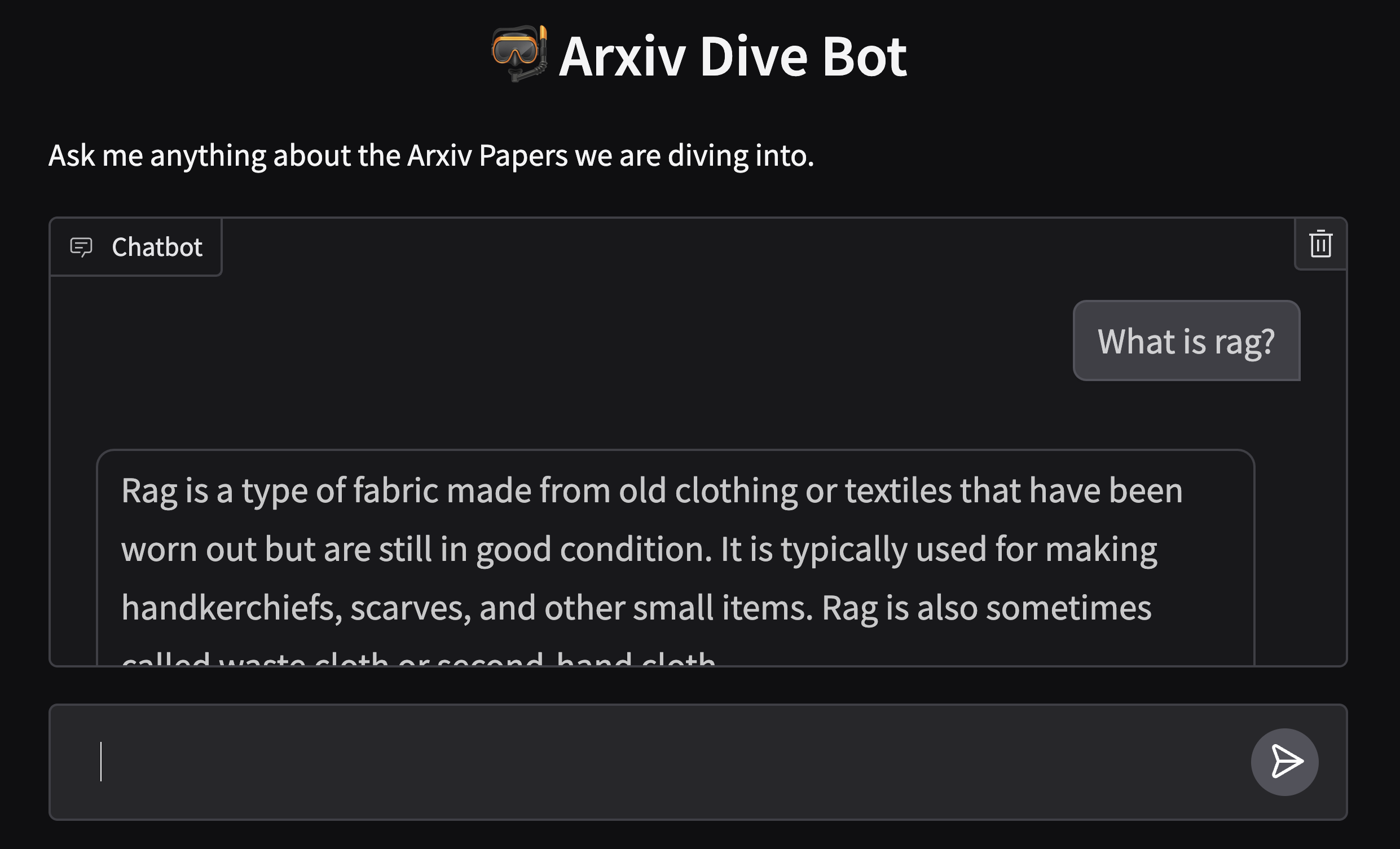
This demo app, which can be found in the repository above, has two modes it can be run in: "with context" and "without context". First let's run it without context.
Q: What is rag?
python app/app.py --without-context
Then let's add some context:
python app/app.py
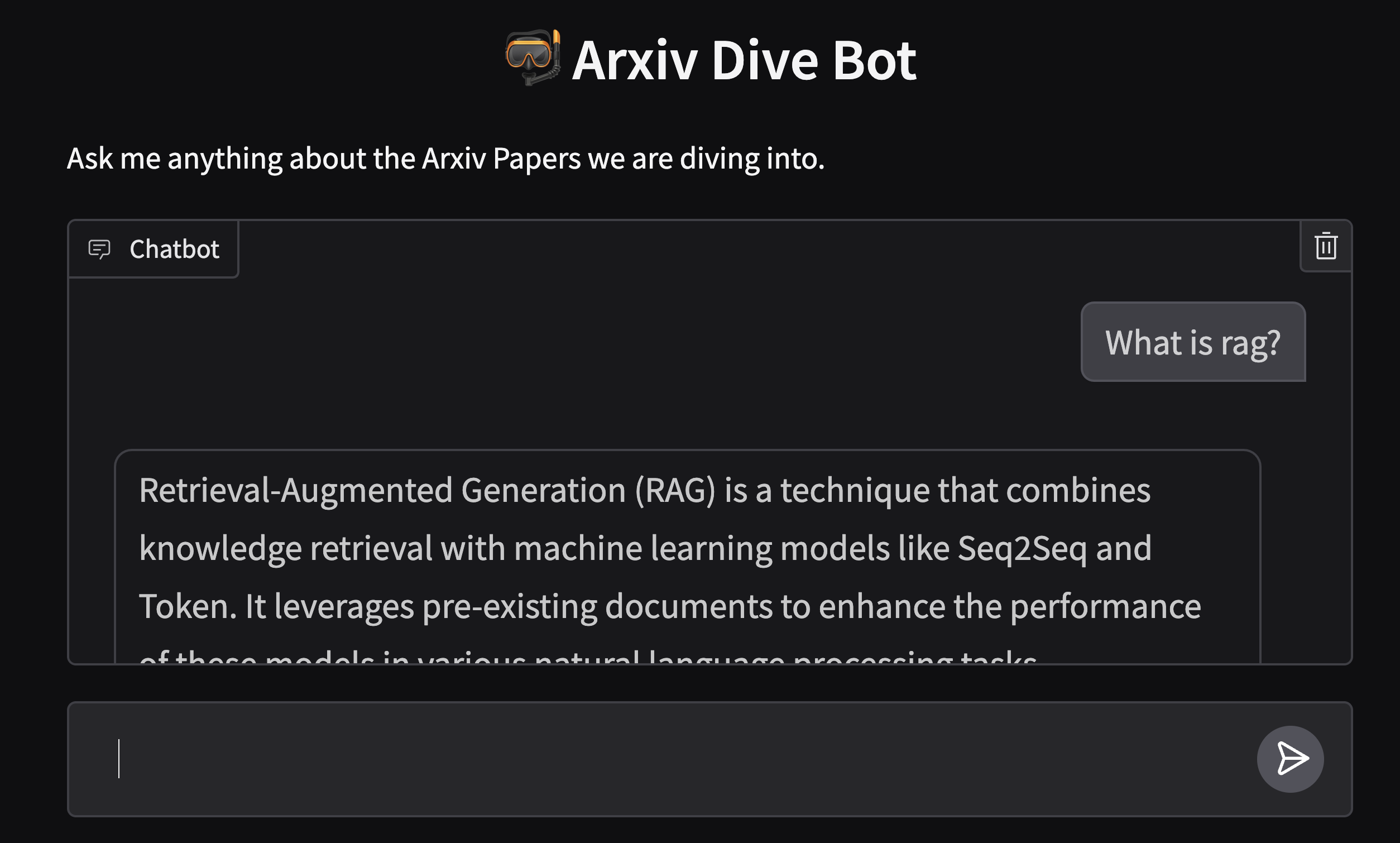
RAG helps disambiguate and ground answers in documents that were retrieved.
How we build AI products is changing. As seen in the AI Engineer by Chip Huyen:

It's actually much easier to create an end to end product and then start collecting data than it is to train a model from scratch. So to start, I created a quick “product” that we can then generate data from and optimize as the AI get’s questions wrong.

# Setup Virtual Environment
python3.12 -m venv ~/.venv_rag
source ~/.venv_rag/bin/activate
# Clone Repo
oxen clone <https://hub.oxen.ai/ox/Arxiv-Dive-RAG>
# Install Deps
pip install -r app/requirements.txt
# Run App
python app/app.py
Once we have an app up and running, then we have something we can evaluate further down the line.
Evaluating RAG is Hard
Evaluating RAG pipelines is hard. We cannot do direct string matches to compute accuracy like traditional classification tasks and there are multiple moving parts we have to evaluate.
Let’s take a look at our example dataset:
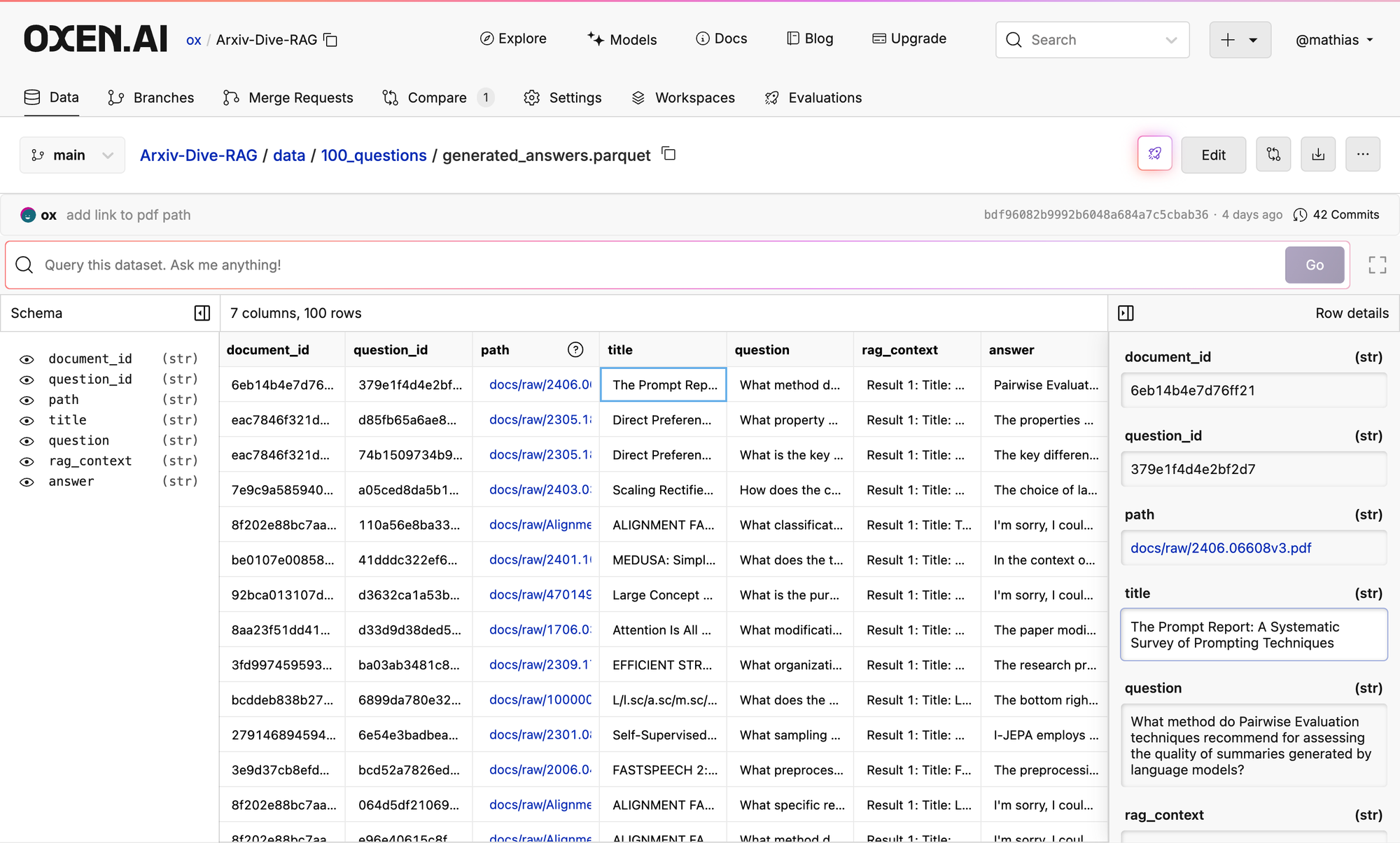
It would probably take me over an hour to read through each question, context, answer triple and figure out if each one is correct. If I made a tweak to the pipeline, I’d then have to go read every answer again….this would not be sustainable.
Enter RAGAS.
RAGAS is a framework to evaluate RAG pipelines without human annotations. There is a significant amount of tuning that needs to be done when building RAG applications, and RAGAS can help speed up iteration cycles when tuning different knobs.
Questions this paper asks are:
- Did we find high quality documents that are relevant to the query?
- Did the LLM understand and use the passages in a faithful way?
- What is the quality of the generation or answer itself?
This leads to the RAGAS evaluation criteria.
RAGAS Evaluation Criteria
This paper focuses on 3 main aspects in order to evaluate answers.
- Faithfulness - answers should be grounded in the context. The LLM should not answer if the answer is not in the context. This helps reduce hallucinations
- Answer Relevance - Answers should address the question that was provided.
- Context Relevance - The context supplied should be focused, and contain as little irrelevant information as possible. If contexts are too long, LLMs tend to be less effective in general.
All experiments in this paper were done using a gpt-3.5-turbo-16kmodel, but obviously we have more sophisticated models now that the framework can be used with. We will be experimenting with GPT-4 level models today.
There is an open source implementation here:
Let’s dive into each evaluation criteria.
Faithfulness
To estimate faithfulness, they first use an LLM to extract a set of statements given a question and answer pair.

Given a question and an answer, create one or more statements from each sentence in the given answer.
The statements should be in an ordered list such as
1. First Statement
2. Second Statement
etc...
question: {question}
answer: {answer}
Notice that we are not giving the context here, just the question and the answer. This is important given the next step.
Let’s take a look at some outputs given our ArXiv Dive questions:
Then for each statement, the LLM determines if the statement can be inferred from the context. This way we have separated out statements about the question+answer from the context. If the context agrees with the statements, without seeing the questions or answers, then we are most likely being faithful to the context with the answer.

Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explanation for each statement before arriving at the final verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
Context:
{context}
Statements:
{statements}
The faithfulness score is then computed by
F = V/S
V = the number of statements that are supported
S = the total number of statements
Answer Relevance
Does the answer directly address the question in an appropriate way? This does not take into account factuality, but does require the answer to be complete.
In order to do this, they first generate N possible questions given the answer:

Generate 3 questions for the given the answer. Generate the questions in an ordered list:
1.
2.
3.
Answer: {answer}
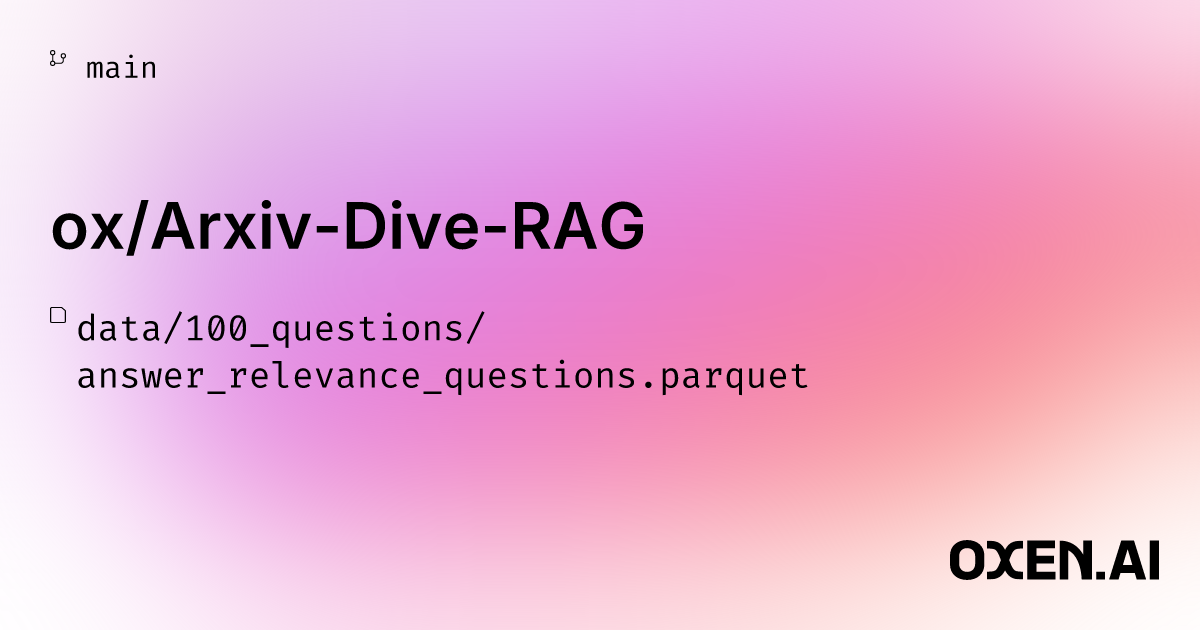
Then they compute the embeddings for each question using text-embedding-ada-002 from OpenAI.
Then for each generated question, they compute the similarity to the original question, and average all the similarities.
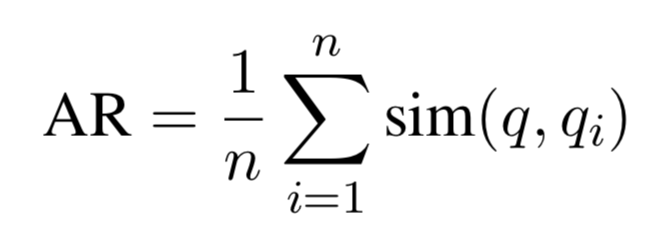
In theory this evaluates how closely the generated answer aligns with the initial question.
I need to look at the actual code and prompt for this…I’m a bit skeptical if it doesn’t include the context because how do you know what the question was asking just from the answer? I want to look at more data.
Context Relevance
This metric aims to have context that exclusively answers the question and does not have excess or redundant information. It’s computed with the following prompt:

Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you're not allowed to make any changes to sentences from given context.
Question:
{question}
Context:
{context}
The score is then calculated by dividing the number of extracted sentences by the total number of sentences.
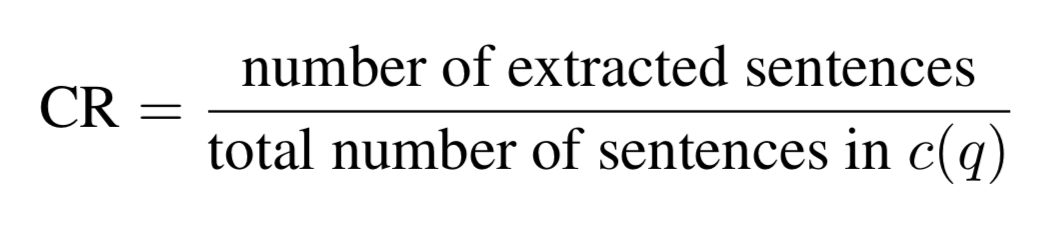
Computing Final Score…
This is a work in process, the Oxen team is spending our Friday hackathon trying to get some RAGAS scores and then tweaking the pipeline to improve the scores.
Faithfulness
$ python scripts/ragas/compute_faithfulness.py
Total Yes verdicts: 134
Total No verdicts: 146
Total verdicts: 280
Score: 0.4785714285714286
Note: I used Cursor and Claude to write the scripts for these computations 30 minutes before this dive…Thanks AI.
Answer Relevance
$ python scripts/ragas/extract_questions.py
$ python scripts/ragas/compute_answer_relevance.py
Number of questions processed: 100
Final average similarity score: 0.6476
Context Relevance
$ python scripts/ragas/compute_context_relevance.py data/100_questions/context_relevance.parquet
Total sentences in RAG context: 3507
Total relevant sentences: 399
Context relevance score: 0.114
Example cursor prompt that generated the "answer relevance" eval scores.
WikiEval Dataset
In the paper they created this dataset - which in my opinion is quite small for an eval dataset. I used 100 examples because it would be easy to whip up a demo for you guys…but for a paper - I’d expect them to have a much larger sample size. They also had human annotators though so I understand that this part is expensive.

It contains 50 Wikipedia pages, and for each page they generate a question based on the intro section of the page.


Then they use another prompt to generate an answer given the question and context.

These 50 question answer pairs were then annotated by two annotators for faithfulness, answer relevance and context relevance.
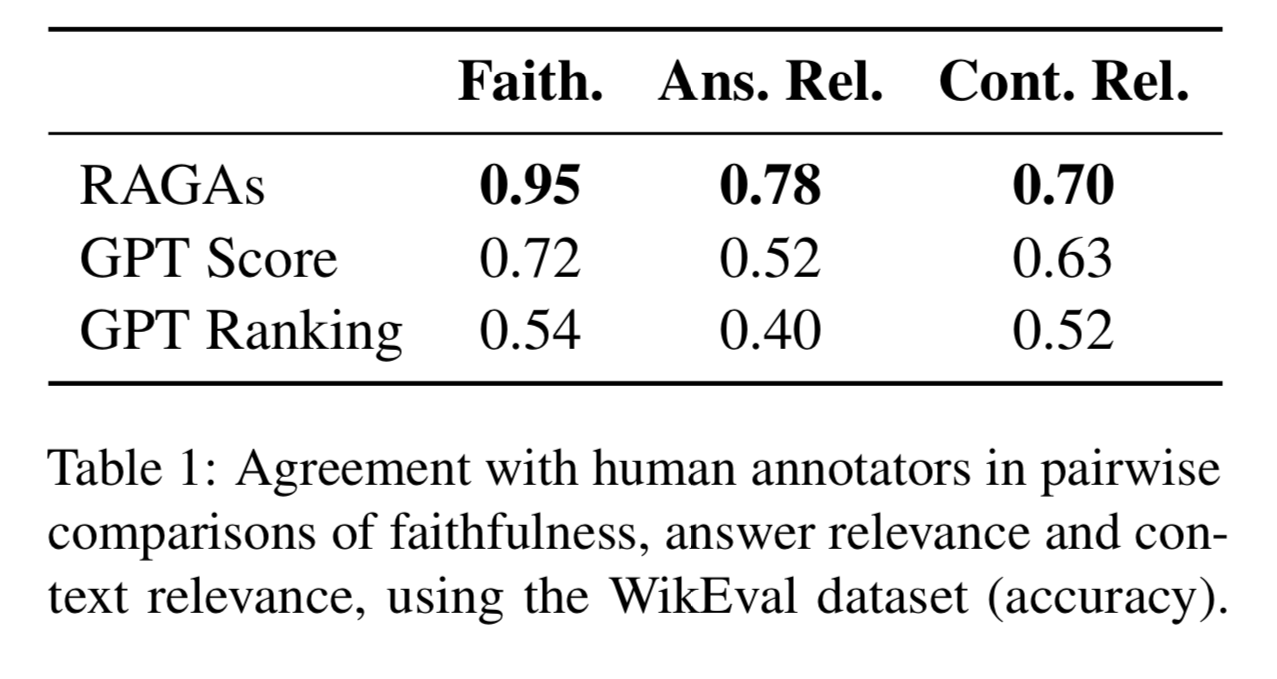
In order to compare different methods to the human annotators, they take answer/context pairs and look which ones the humans prefer and which ones the model prefer. The scores above are the fraction of instances that the model agrees with the annotators.
For GPT Score and GPT Ranking they use a single prompt to decide which answer/context pairs were better. This is more like a simple LLM as a Judge Framework.
GPT Score:

GPT Ranking:

They argue that the differences in answers are often subtle, and ChatGPT at the time struggled to select the sentences from the context that are crucial - especially for longer contexts.
Conclusion
While it can be hard to evaluate RAG pipelines, RAGAS gives a nice framework to evaluate the pipeline without ground truth labels. It seems to get relatively close to human preferences, but still a decent ways off.
This work really shows how you can get creative with LLM as a Judge pipelines, slicing, dicing and ranking the data in different ways. Think of RAGAS as a framework that you can swap pieces in and out of. Change the prompts and descriptions. Change the “metrics” that you think are important for your app.
Do you care more about faithfulness or creativity and novelty? Do you need every answer to be precise or do you can more about recalling more interesting documents? It will be different for every use case.
I think it’s interesting to think how you can shape your model with synthetic data, prompts, preferences and even “constitutions” in the sense of Anthropic’s Constitutional AI. In the future I believe there will be as many different AI systems as there are people on the planet. All trained on their own unique data, shaped by the people who create them.
Instead of hard coding rules in a program, you can now describe in English how you want your model to behave, then generate scores accordingly. If you start optimizing towards those scores, your model will start having the properties that you specified in plain English, which is pretty wild to think about.
Blog Appendix
For the sake of time, I skipped explaining how I got the original data prepped. We will do another post on how to prep your data and best use Oxen.ai for sharing and exploring the data.
🌪️ Whirlwind of Arxiv Dive Bot Data Prep Steps
- Download Raw PDFs
- Parse into Markdown with Docling
- Chunk into Sections
- Compute embeddings for the sections
- Select “interesting” sections and generate questions
- Choose 100 random questions for RAGAS evaluation
Once we have section embeddings and questions, we are ready to create a RAG pipeline and evaluate it.
Questions
Section Embeddings
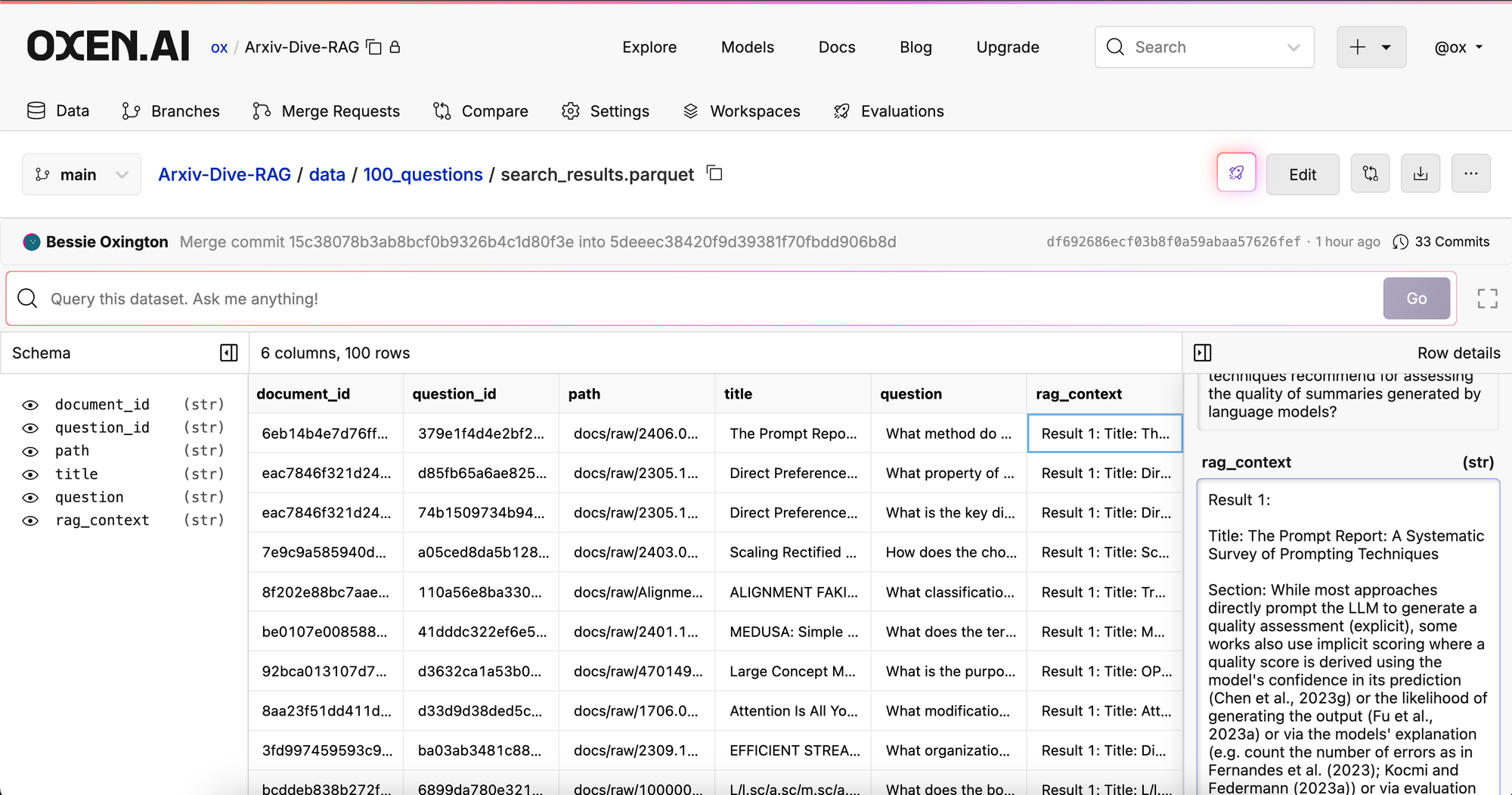
The first thing we have to do is fetch context given the questions + section embeddings.
python app/generate_contexts.py data/100_questions/questions.parquet data/100_questions/search_results.parquet
Then we can answer the questions given the context
You are a helpful assistant that can answer questions. Look at the context provided and answer the question. Answer as concisely as possible. If the context is not relevant, just say "I'm sorry, I couldn't find information on that topic."
Context:
{rag_context}
Question:
{question}
Answers: