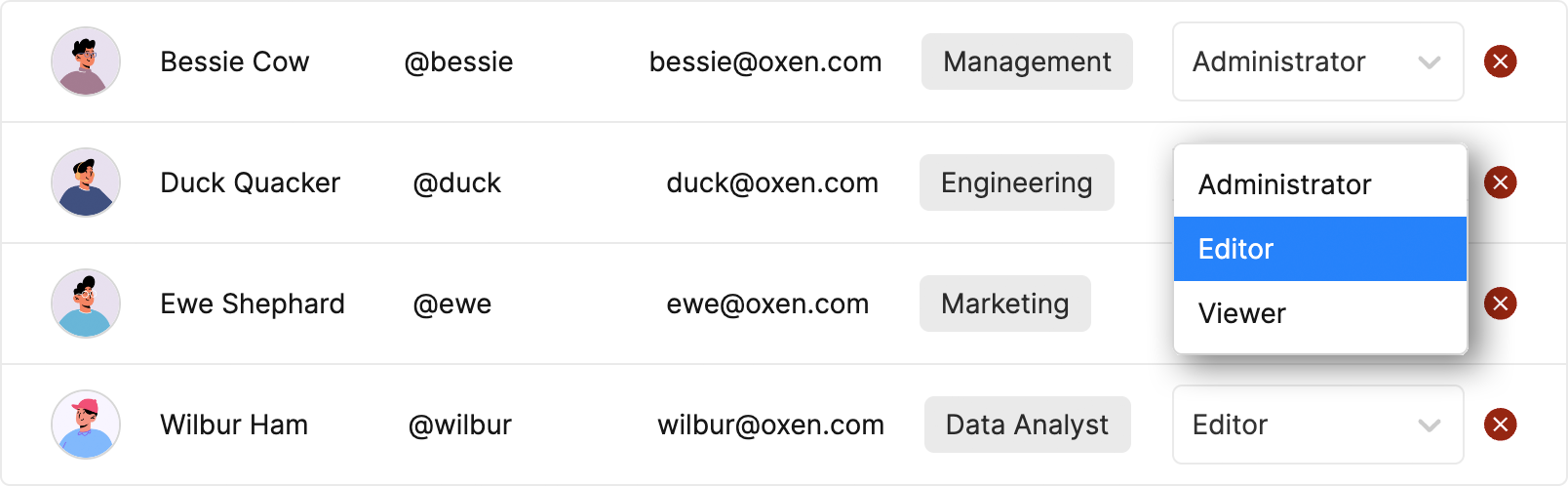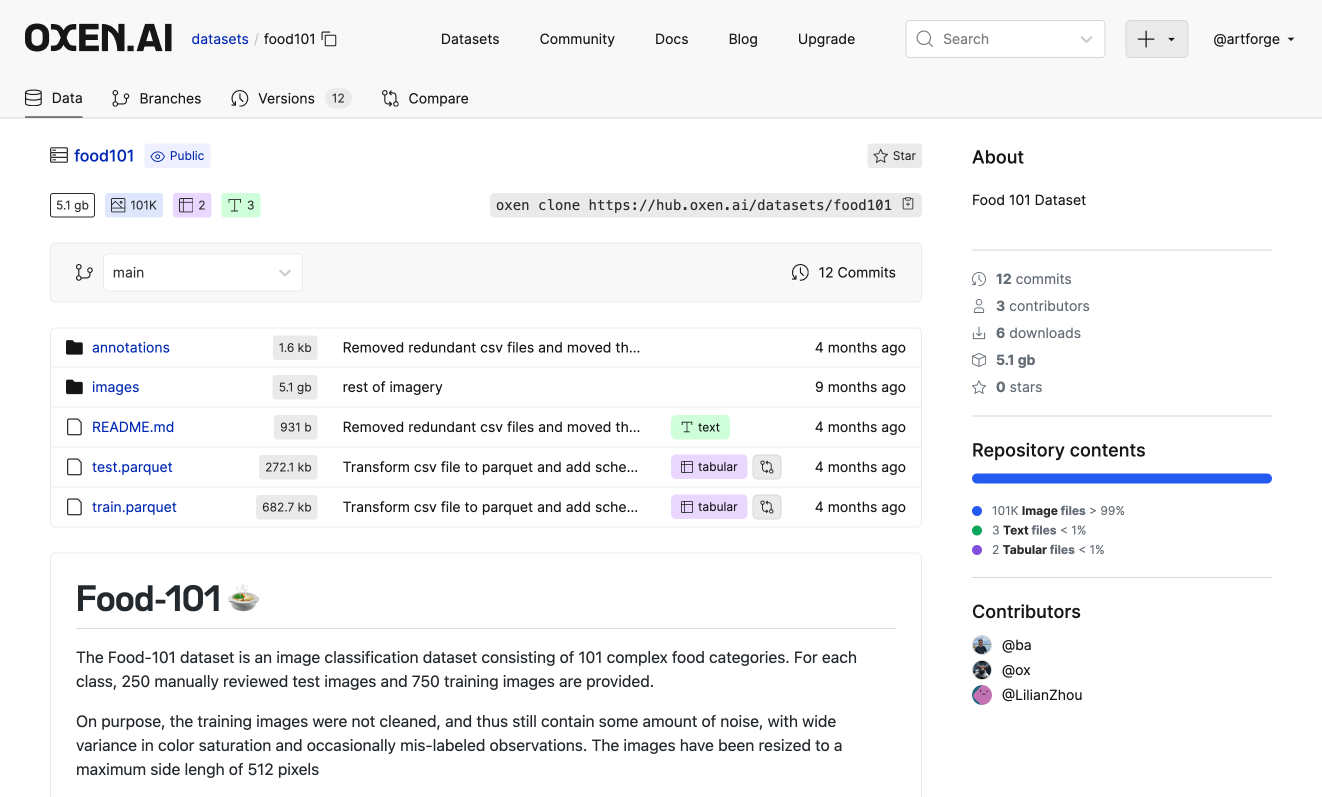
Explore Datasets
Oxen’s public and private datasets allow you to iterate on data within your organization or share them with the world.






Oxen’s public and private datasets allow you to iterate on data within your organization or share them with the world.
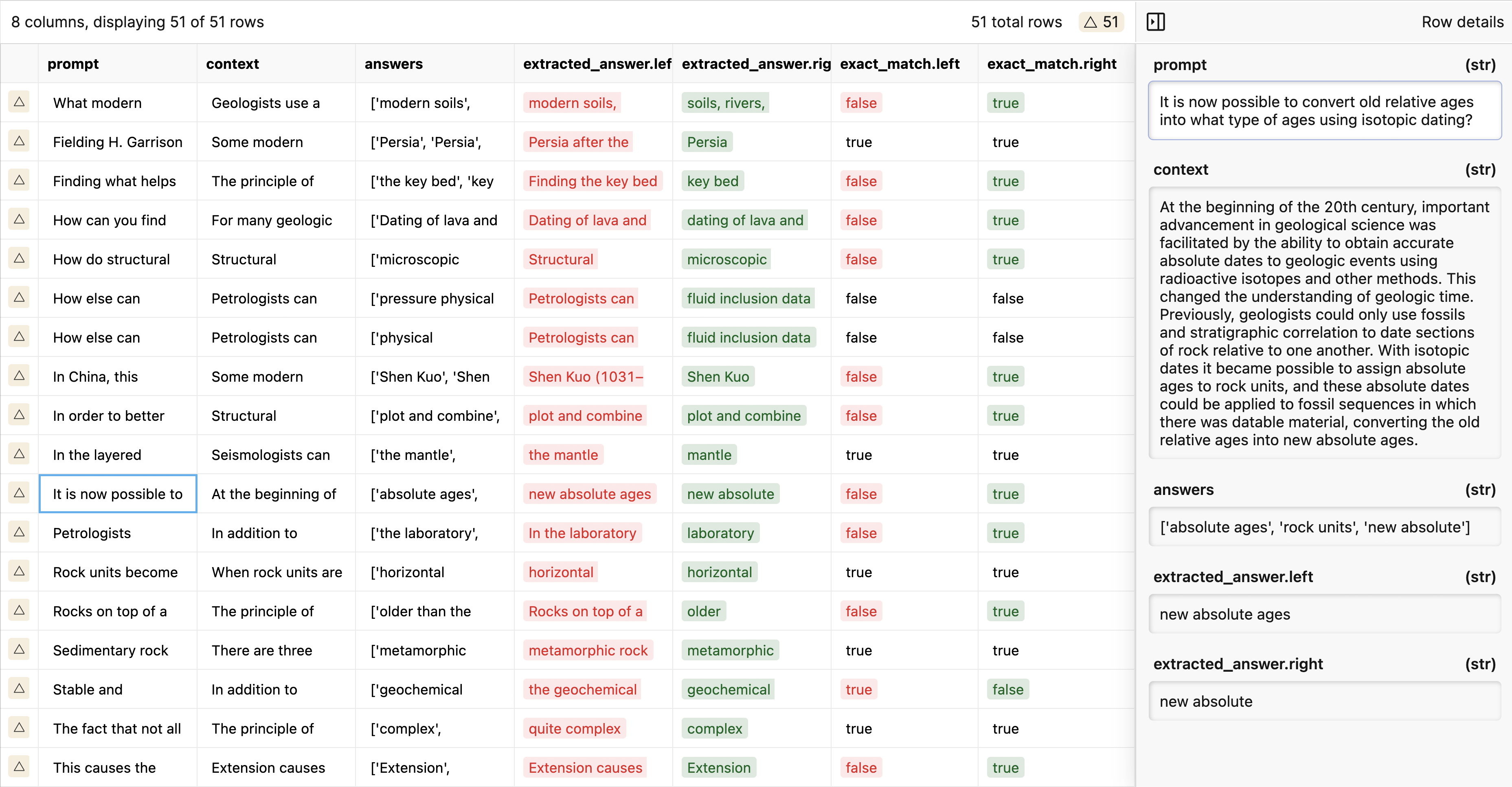
A dataset from the Allen Institute of AI consisting of genuine grade-school level, multiple-choice science questions, assembled to encourage research in advanced question-answering. The dataset the Challenging Set of questions.
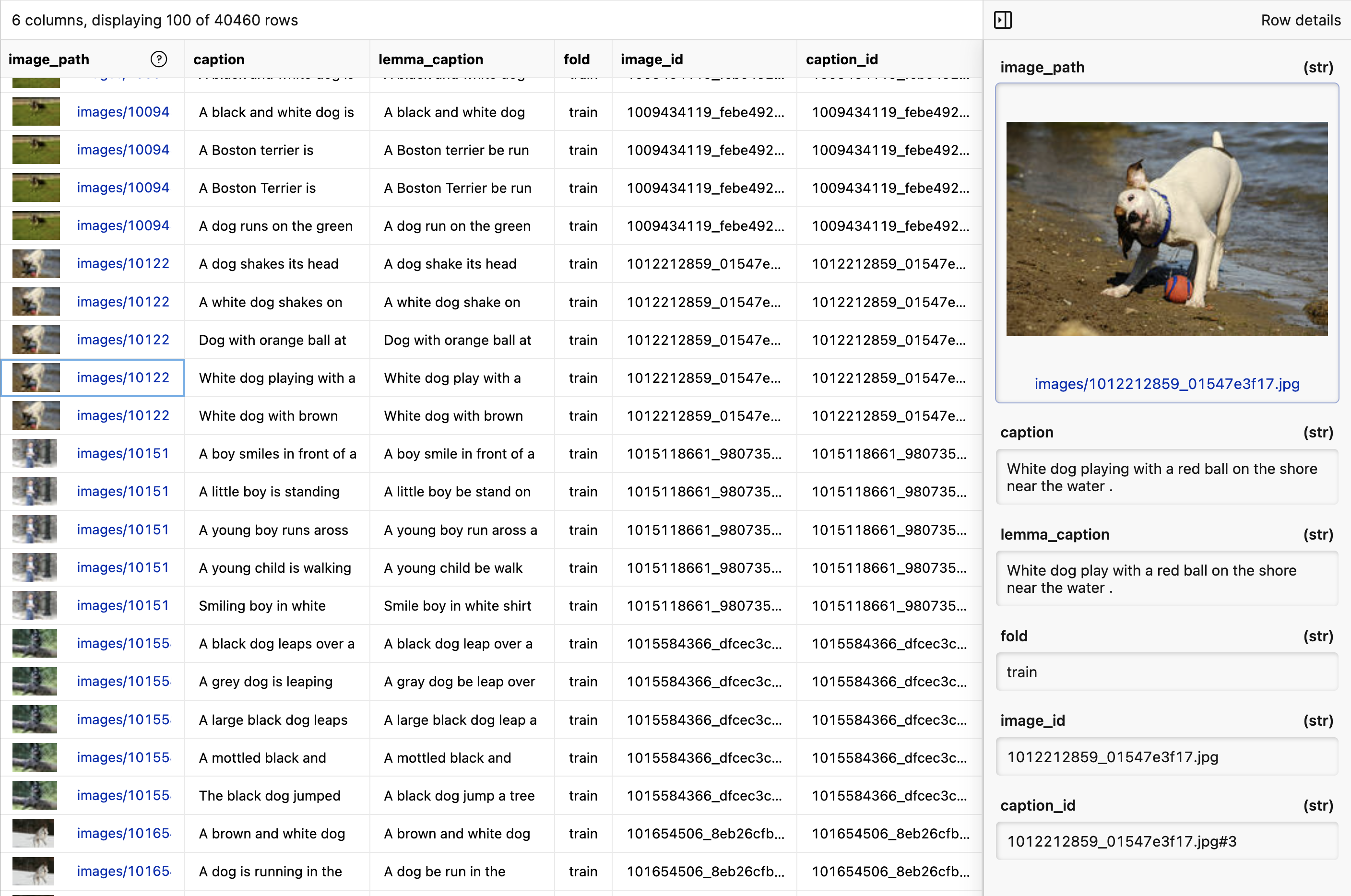
A benchmark collection for sentence-based image description and search, consisting of 8,000 images that are each paired with five different captions which provide clear descriptions of the salient entities and events. … The images were chosen from six different Flickr groups, and tend not to contain any well-known people or locations, but were manually selected to depict a variety of scenes and situations.
Subset of speech commands to test audio recognition systems on.
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations.
AI is only as good as the datasets you feed it. Gain visibility into the data that goes in and out of your model.
Datasets change every day. Oxen’s version control allows you to quickly narrow down the most important changes that affect your model.
Oxen’s data version control is built to handle data of any shape or size.
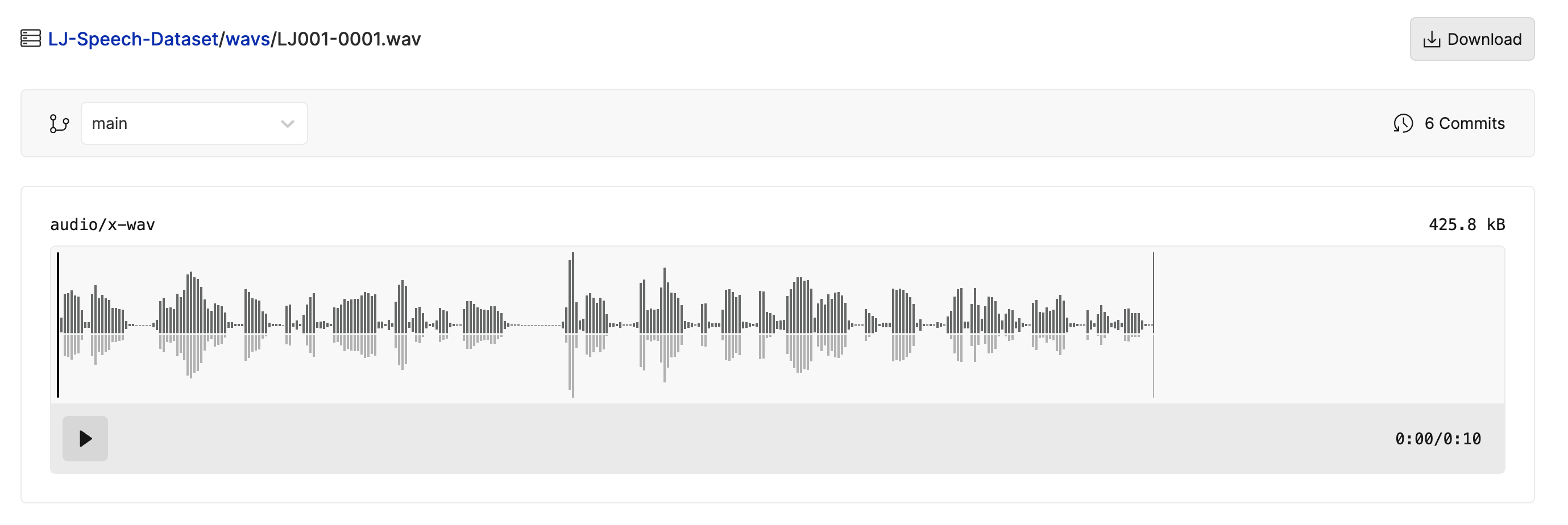
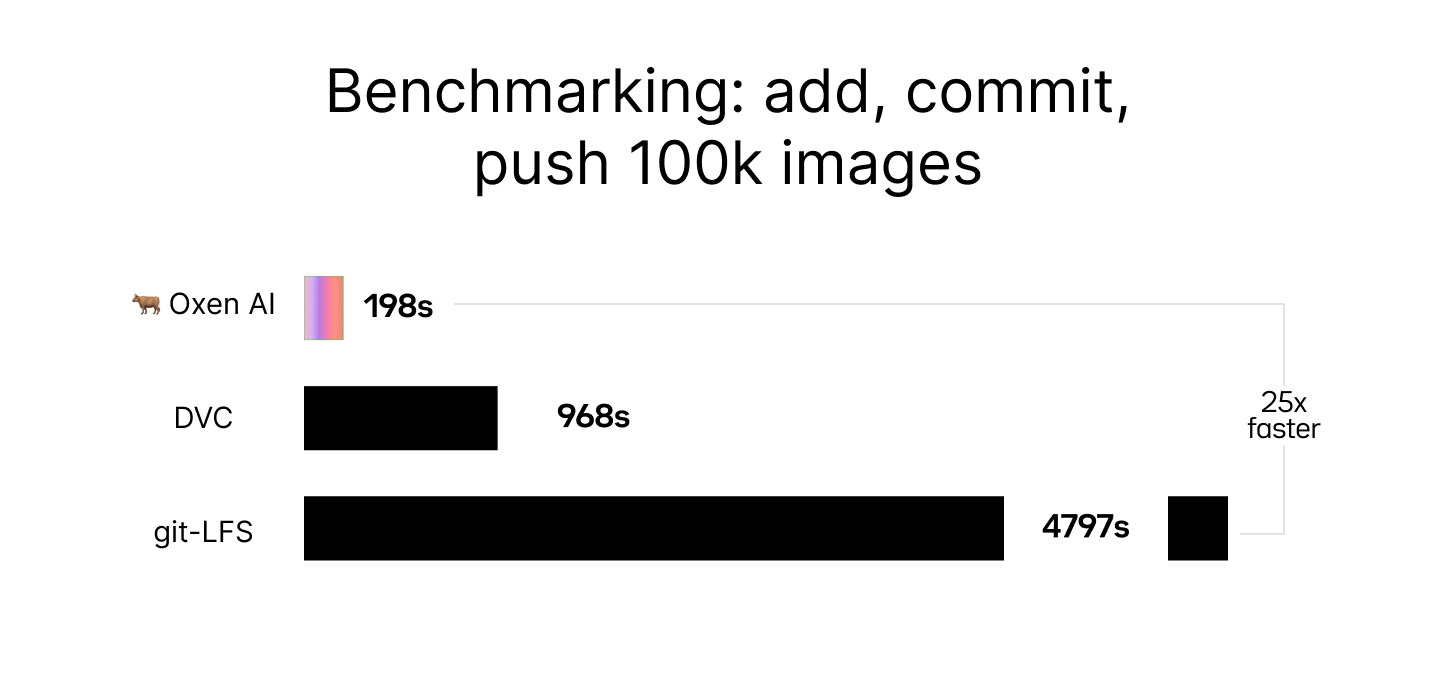
Oxen.ai saves your engineers hours syncing data from training, testing, to evaluation. From fast syncing of data to removing push/pull bottlenecks from traditional VCS systems, Oxen.ai was built for machine learning datasets and workflows.
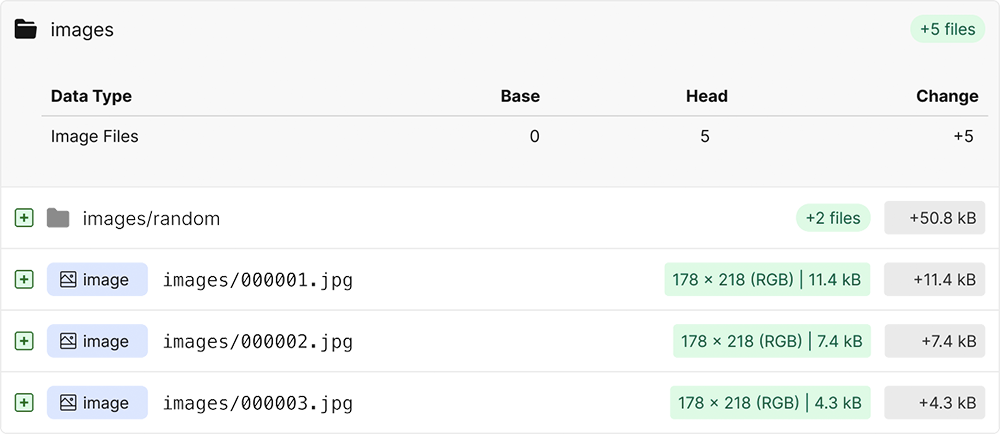
Oxen’s data version control turns your unstructured data into beautifully rendered datasets that evolve overtime. Dive into any version of the dataset at any point in time and see exactly what changed.
Oxen.ai has re-imagined version control for data. At the core are the same principles that have made Git so powerful, but Oxen has optimized down to the merkle trees, hashing principles, and network protocols to make it work more fast and effortless for large scale datasets.
Many stakeholders, ML Eng, Data Science, Product, Legal, Auditing, Community. The more eyes the better
Oxen.ai has developed a strong and growing community of individuals focused on furthering machine learning and artificial intelligence. From academic researchers training the next generation of models, to full-stack developers leveraging existing API's to build amazing products. Every Friday we get together and read research papers, discuss them, and apply them to our own work.
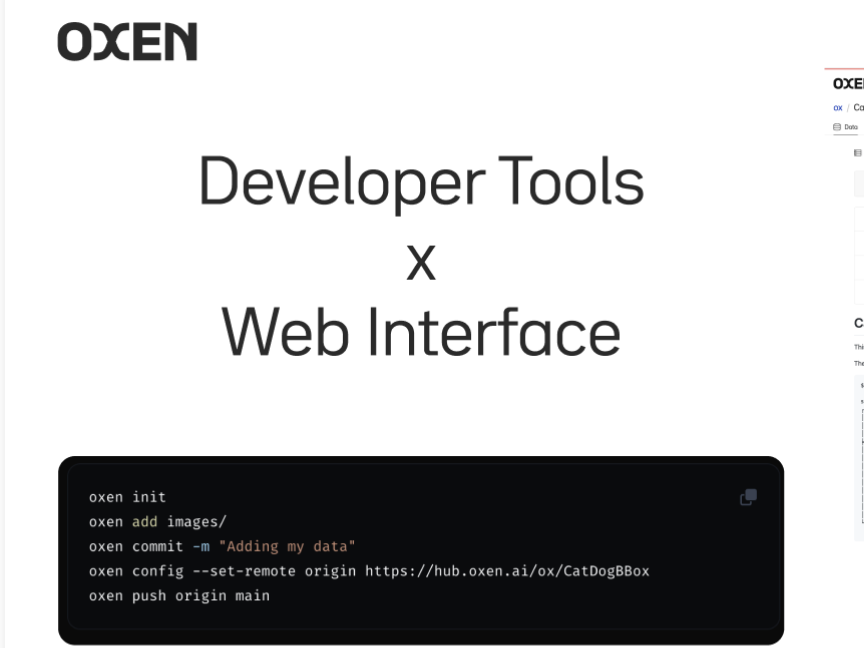
This intro tutorial from Oxen.ai shows how Oxen can make versioning your data as easy as versioning your code. Oxen is built to track and store changes for everything from a single CSV to data repositories with millions of unstructured images, videos, audio or text files. The tutorial will go through what data version control is, why it is important, and how Oxen helps data scientists and engineers gain visibility and confidence when sharing data with the rest of their team. Here's a video ve...


Every Friday the team at Oxen.ai gets together and goes over research papers, blog posts, or books that help us stay up to date with the latest in Machine Learning and AI. We call it Arxiv Dives because https://arxiv.org/ is a great resource for the latest research in the field. In September of 2023, we decided to make it public so that anyone can join. We’ve had amazing minds from hundreds of companies like Amazon, DoorDash, Meta, Google, and Tesla join the conversation, but I thought it would...
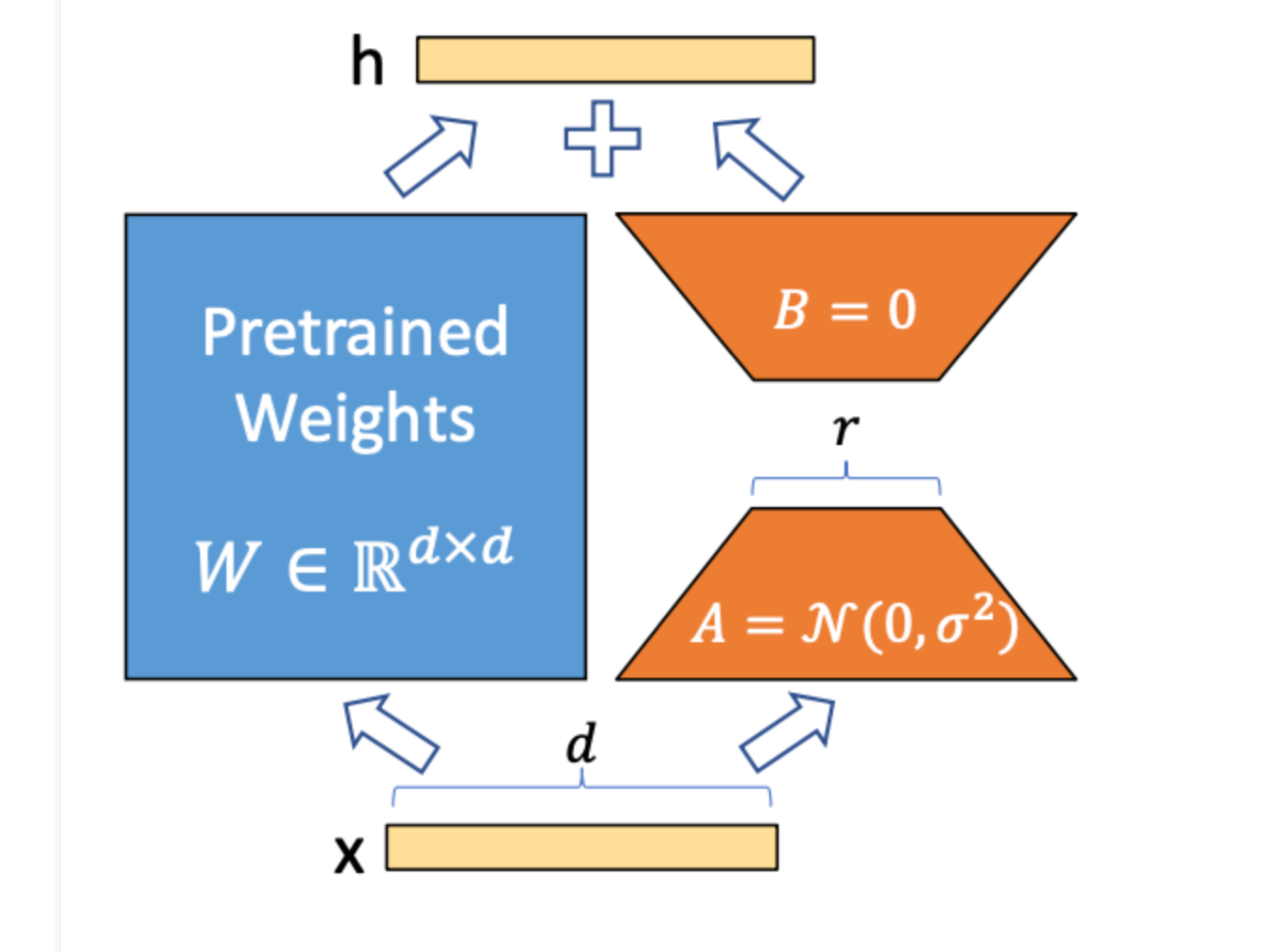
Running Large Language Models (LLMs) on the edge is a fascinating area of research, and opens up many use cases that require data privacy or lower cost profiles. With libraries like ggml coming on to the scene, it is now possible to get models anywhere from 1 billion to 13 billion parameters to run locally on a laptop with relatively low latency. In this tutorial, we are going to walk step by step how to fine tune Llama-2 with LoRA, export it to ggml, and run it on the edge on a CPU. We assume...